Основные положения теории нейронных сетей
Выбор типа (архитектуры) сети
Постановка задачи классификации сейсмических сигналов
Отбор наиболее информативных признаков для идентификации
Процедура статистической идентификации
Многослойный персептрон
Выводы по разделу
Понижение размерности входов
Выводы по разделу
Определение критерия качества системы и функционала его оптимизации
Формирование обучающей выборки и оценка эффективности обученной нейросетевой модели
Описание входного файла с исходными данными
Заключение
Пример файла отчета
Файл автоматической компиляции программы под Unix -“Makefile”
Навигация
Определение критерия качества системы и функционала его оптимизации
Классификация сейсмических сигналов на основе нейросетевых технологий
114641
знак
1
таблица
28
изображений
6.3 Определение критерия качества системы и функционала его оптимизации.
Если через ![]() обозначить желаемый выход сети (указание учителя), то ошибка системы для заданного входного сигнала (рассогласование реального и желаемого выходного сигнала) можно записать в следующем виде:
обозначить желаемый выход сети (указание учителя), то ошибка системы для заданного входного сигнала (рассогласование реального и желаемого выходного сигнала) можно записать в следующем виде:
![]()
![]() , где
, где
k — номер обучающей пары в обучающей выборке, k=1,2,…,n1+n2
n1 - количество векторов первого класса;
n2 - число векторов второго класса.
В качестве функционала оптимизации будем использовать критерий минимума среднеквадратической функции ошибки:
![]()
6.4 Выбор начальных весовых коэффициентов.
Перед тем, как приступить к обучению нейронной сети, необходимо задать ее начальное состояние. От того насколько удачно будут выбраны начальные значения весовых коэффициентов зависит, как долго сеть за счет обучения и подстройки будет искать их оптимальное величины и найдет ли она их.
Как правило, всем весам на этом этапе присваиваются случайные величины равномерно распределенные в диапазоне [-A,A], например [-1,1], или [-3,3]. Однако, как показали эксперименты, данное решение не является наилучшим и в качестве альтернативы предлагается использовать другие виды начальной инициализации, а именно:
1. Присваивать весам случайные величины, заданные не равномерным распределением, а нормальным распределением с параметрами N[a,s], где выборочное среднее a=0, а дисперсия s = 2, или любой другой небольшой положительной величине. Для формирования нормально распределенной величины можно использовать следующий алгоритм:
Шаг 1. Задать 12 случайных чисел x1, x2, …,x12 равномерно распределенных в диапазоне [0,1]. xi Í R[0,1].
Шаг 2. Для искомых параметров a и s величина ![]() , полученная по формуле:
, полученная по формуле:
![]()
будет принадлежать нормальному распределению с параметрами N[a,s].
2. Можно производить начальную инициализацию весов в соответствии с методикой, предложенной Nguyen и Widrow [7]. Для этой методики используются следующие переменные
![]() число нейронов текущего слоя
число нейронов текущего слоя
![]() количество нейронов последующего слоя
количество нейронов последующего слоя
![]() коэффициент масштабирования:
коэффициент масштабирования:
![]()
Вся процедура состоит из следующих шагов:
Для каждого нейрона последующего слоя![]() :
:
Инициализируются весовые коэффициенты (с нейронов текущего слоя):
![]() случайное число в диапазоне [-1,1] ( или
случайное число в диапазоне [-1,1] ( или ![]() ).
).
Вычисляется норма ![]()
Далее веса преобразуются в соответствии с правилом:
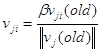
Смещения ![]() выбираются случайным образом из диапазона
выбираются случайным образом из диапазона ![]() .
.
Обе предложенные методики позволили на практике добиться лучших результатов, в сравнении со стандартным алгоритмом начальной инициализации весов.
6.5 Алгоритм обучения и методы его оптимизации.
Приступая к обучению выбранной нейросетевой модели, необходимо было решить, какой из известных типов алгоритмов, градиентный (обратное распространения ошибки) или стохастический (Больцмановское обучение) использовать. В силу ряда субъективных причин был выбран именно первый подход, который и представлен в этом разделе.
Обучение нейронных сетей как минимизация функции ошибки.
Когда функционал ошибки нейронной сети задан (раздел 6.3), то главная задача обучения нейронных сетей сводится к его минимизации. Градиентное обучение – это итерационная процедура подбора весов, в которой каждый следующий шаг направлен в сторону антиградиента функции ошибки. Математически это можно выразить следующим образом:
![]() , или , что то же самое :
, или , что то же самое : ![]() ,
,
здесь ht - темп обучения на шаге t. В теории оптимизации этот метод известен как метод наискорейшего спуска.[]
Метод обратного распространения ошибки.
Исторически наибольшую трудность на пути к эффективному правилу обучения многослойных персептронов вызвала процедура расчета градиента функции ошибки ![]() . Дело в том, что ошибка сети определяется по ее выходам, т.е. непосредственно связана лишь с выходным слоем весов. Вопрос состоял в .том, как определить ошибку для нейронов на скрытых слоях, чтобы найти производные по соответствующим весам. Нужна была процедура передачи ошибки с выходного слоя к предшествующим слоям сети, в направлении обратном обработке входной информации. Поэтому такой метод, когда он был найден, получил название метода обратного распространения ошибки (error back-propagation ).
. Дело в том, что ошибка сети определяется по ее выходам, т.е. непосредственно связана лишь с выходным слоем весов. Вопрос состоял в .том, как определить ошибку для нейронов на скрытых слоях, чтобы найти производные по соответствующим весам. Нужна была процедура передачи ошибки с выходного слоя к предшествующим слоям сети, в направлении обратном обработке входной информации. Поэтому такой метод, когда он был найден, получил название метода обратного распространения ошибки (error back-propagation ).
Разберем этот метод на примере двухслойного персептрона с одним нейроном на выходе.(рис 6.1) Для этого воспользуемся введенными ранее обозначениями. Итак,
![]() -Функция ошибки (13)
-Функция ошибки (13)
![]() -необходимая коррекция весов коррекция весов (14)
-необходимая коррекция весов коррекция весов (14)
для выходного слоя Dv записывается следующим образом.
![]()
Коррекция весов между входным и скрытым слоями производится по формуле:
![]() (15)
(15)
![]()
![]()
![]()
Подставляя одно выражение в другое получаем
![]() (16)
(16)
Производная функции активации, как было показано ранее (раздел 6.1), вычисляется через значение самой функции. ![]()
![]()
Непосредственно алгоритм обучения состоит из следующих шагов:
1. Выбрать очередной вектор из обучающего множества и подать его на вход сети.
2. Вычислить выход сети y(x) по формуле (12).
3. Вычислить разность между выходом сети и требуемым значением для данного вектора (13).
4. Если была допущена ошибка при классификации выбранного вектора, то подкорректировать последовательно веса сети сначала между выходным и скрытым слоями (15), затем между скрытым и входным (16).
5. Повторять шаги с 1 по 4 для каждого вектора обучающего множества до тех пор, пока ошибка на всем множестве не достигнет приемлемого уровня.
Несмотря на универсальность, этот метод в ряде случаев становится малоэффективным. Для того, чтобы избежать вырожденных случаев, а также увеличить скорость сходимости функционала ошибки, разработано много модификаций стандартного алгоритма, в частности две из которых и предлагается использовать.
Многостраничное обучение.
С математической точки зрения обучение нейронных сетей (НС) – это многопараметрическая задача нелинейной оптимизации. В классическом методе обратного распространения ошибки (single-режим) обучение НС рассматривается как набор однокритериальных задач оптимизации. Критерий для каждой задачи - качество решения одного примера из обучающей выборки. На каждой итерации алгоритма обратного распространения параметры НС (синаптические веса и смещения) модифицируются так, чтобы улучшить решение одного примера. Таким образом, в процессе обучения циклически решаются однокритериальные задачи оптимизации.
Из теории оптимизации следует, что при решении многокритериальных задач модификации параметров следует производить, используя сразу несколько критериев (примеров), в идеале - все. Тем более нельзя ограничиваться одним примером при оценке производимых изменений значений параметров.
Для учета нескольких критериев при модификации параметров используют агрегированные или интегральные критерии, которые могут быть, например, суммой, взвешенной суммой или квадратным корнем от суммы квадратов оценок решения отдельных примеров.
В частности, в настоящих исследованиях изменения весов проводилось после проверки всей обучающей выборки, при этом функция ошибки рассчитывалась в виде :
![]()
где,
k - номер обучающей пары в обучающей выборке, k=1,2,…,n1+n2
n1 - количество векторов первого класса;
n2 - число векторов второго класса.
Как показывают тестовые испытания, обучение при использовании пакетного режима, как правило сходится быстрее, чем обучение по отдельным примерам.
Автоматическая коррекция шага обучения.
В качестве еще одного расширения традиционного алгоритма обучения предлагается использовать так называемый градиентный алгоритм с автоматическим определением длины шага h. Для его описания необходимо определить следующий набор параметров:
· начальное значение шагаh0 ;
· количество итераций, через которое происходит запоминание данных сети (синоптических весов и смещений);
· величина (в процентах) увеличения шага после запоминания данных сети, и величина уменьшения шага в случае увеличения функции ошибки.
В начале обучения записываются на диск значения весов и смещений сети. Затем происходит заданное число итераций обучения с заданным шагом. Если после завершения этих итераций значение функции ошибки не возросло, то шаг обучения увеличивается на заданную величину, а текущие значения весов и смещений записываются на диск. Если на некоторой итерации произошло увеличение функции ошибки, то с диска считываются последние запомненные значения весов и смещений, а шаг обучения уменьшается на заданную величину.
При использовании автономного градиентного алгоритма происходит автоматический подбор длины шага обучения в соответствии с характеристиками адаптивного рельефа, и его применение позволило заметно сократить время обучения сети без потери качества полученного результата.
Эффект переобучения.
Одна из наиболее серьезных трудностей изложенного подхода обучения заключается в том, что таким образом минимизируется не та ошибка, которую на самом деле нужно минимизировать, а ошибка, которую можно ожидать от сети, когда ей будут подаваться совершенно новые наблюдения. Иначе говоря, хотелось бы, чтобы нейронная сеть обладала способностью обобщать результат на новые наблюдения. В действительности сеть обучается минимизировать ошибку на обучающем множестве, и в отсутствие идеального и бесконечно большого обучающего множества это совсем не то же самое, что минимизировать "настоящую" ошибку на поверхности ошибок в заранее неизвестной модели явления [5]. Иначе говоря, вместо того, чтобы обобщить известные примеры, сеть запомнила их. Этот эффект и называется переобучением.
Соответственно возникает проблема – каким методом оценить ошибку обобщения? Поскольку эта ошибка определена для данных, которые не входят в обучающее множество, очевидным решением проблемы служит разделение всех имеющихся в нашем распоряжении данных на два множества: обучающее – на котором подбираются конкретные значения весов, и валидационного – на котором оцениваются предсказательные способности сети. На самом деле, должно быть еще и третье множество, которое вообще не влияет на обучение и используется лишь для оценки предсказательных возможностей уже обученной сети. Ошибки, полученные на обучающем, валидационном и тестовом множестве соответственно называются ошибка обучения, валидационная ошибка и тестовая ошибка.
В нейроинформатике для борьбы с переобучением используются три основных подхода:
· Ранняя остановка обучения;
· Прореживание связей (метод от большого к малому);
· Поэтапное наращивание сети ( от малого к большому).
Самым простым является первый метод. Он предусматривает вычисление во время обучения не только ошибки обучения, но и ошибки валидации, используя ее в качестве контрольного параметра. В самом начале работы ошибка сети на обучающем и контрольном множестве будет одинаковой. По мере того, как сеть обучается, ошибка обучения, естественно, убывает, и, пока обучение уменьшает действительную функцию ошибок, ошибка на контрольном множестве также будет убывать. Если же контрольная ошибка перестала убывать или даже стала расти, это указывает на то, что сеть начала слишком близко аппроксимировать данные и обучение следует остановить. Рисунок 6.5 дает качественное представление об этой методике.
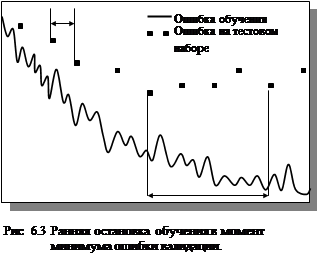
Использование этой методики в работе с сейсмическими данными затруднено тем обстоятельством, что исходная выборка очень мала, а хотелось бы как можно больше данных использовать для обучения сети. В связи с этим было принято решение отказаться от формирования валидационного множества, а в качестве момента остановки алгоритма обучения использовать следующее условие: ошибка обучения достигает заданного минимального уровня, причем значение минимума устанавливается немного большим чем обычно. Для проверки этого условия проводились дополнительные эксперименты, показавшие что при определенном минимуме ошибки обучения достигался относительный минимум ошибки на тестовых данных.
Два других подхода для контроля переобучения предусматривают постепенное изменение структуры сети. Только в одном случае происходит эффективное вымывание малых весов (weight elimination) ,т.е. прореживание малозначительных связей, а во втором, напротив, поэтапное наращивание сложности сети. [3,4,5].
Похожие работы

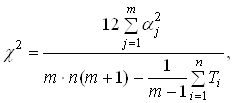
... МП к некритическому экстраполированию результата считается его слабостью. Сети РБФ более чувствительны к «проклятию размерности» и испытывают значительные трудности, когда число входов велико. 5. МОДЕЛИРОВАНИЕ НЕЙРОННЫХ СЕТЕЙ ДЛЯ ПРОГНОЗИРОВАНИЯ СТОИМОСТИ НЕДВИЖИМОСТИ 5.1 Особенности нейросетевого прогнозирования в задаче оценки стоимости недвижимости Использование нейронных сетей можно ...
... в связи с необходимостью упорядоченного сообщения с высоким приоритетом при радикальном изменении окружающих условий и двунаправленностью каналов. Возможности вычисления путей маршрутизации можно применять при построении интегральных схем и проектирования кристаллов процессоров. Нейрокомпьютеры с успехом применяются при обработке сейсмических сигналов в военных целях для определения коорди
... (ШД), адресов (ША) и управления (ШУ). Однокристальные микропроцессоры получаются при реализации всех аппаратных средств процессора в виде одной БИС или СБИС (сверхбольшой интегральной схемы). По мере увеличения степени интеграции элементов в кристалле и числа выводов корпуса параметры однокристальных микропроцессоров улучшаются. Однако возможности однокристальных микропроцессоров ограничены ...


... данных а разбивать входные данные на кластеры. •Рекурсивные сети Элмана, способные обрабатывать последовательности векторов. •Вероятностные сети, аппроксимирующие Байесовские классификаторы с любой степенью точности. Общие принципы, характерные для нейросетей Согласно общепринятым представлениям наиболее общими принципами, характерными для современных нейросетей являются: коннекционизм, ...
0 комментариев