Основные положения теории нейронных сетей
Выбор типа (архитектуры) сети
Постановка задачи классификации сейсмических сигналов
Отбор наиболее информативных признаков для идентификации
Процедура статистической идентификации
Многослойный персептрон
Выводы по разделу
Понижение размерности входов
Выводы по разделу
Определение критерия качества системы и функционала его оптимизации
Формирование обучающей выборки и оценка эффективности обученной нейросетевой модели
Описание входного файла с исходными данными
Заключение
Пример файла отчета
Файл автоматической компиляции программы под Unix -“Makefile”
Навигация
Понижение размерности входов
Классификация сейсмических сигналов на основе нейросетевых технологий
114641
знак
1
таблица
28
изображений
6.3 Понижение размерности входов.
Поскольку заранее неизвестно насколько полезны те или иные входные переменные для предсказания значений выходов, возникает соблазн увеличивать число входных параметров, в надежде на то, что сеть сама определит, какие из них наиболее значимы. Однако чаще всего это не приводит к ожидаемым результатам, а к тому же еще и увеличивает сложность обучения. Напротив, сжатие данных, уменьшение степени их избыточности, использующее существующие в них закономерности, может существенно облегчить последующую работу, выделяя действительно независимые признаки. Можно выделить два типа алгоритмов, предназначенных для понижения размерности данных с минимальной потерей информации:
· Отбор наиболее информативных признаков и использование их в процессе обучения нейронной сети;
· Кодирование исходных данных меньшим числом переменных, но при этом содержащих по возможности всю информацию, заложенную в исходных данных.
Рассмотрим более подробно оба типа алгоритмов.
5.3.1 Отбор наиболее информативных признаков.
Для того, чтобы понять какие из входных переменных несут максимум информации, а какими можно пренебречь необходимо либо сравнить все признаки между собой и определить степень информативности каждого из них, либо пытаться найти определенные комбинации признаков, которые наиболее полно отражают основные характеристики исходных данных.
В разделе 3.2 был описан алгоритм, позволяющий упорядочить все признаки по мере убывания их значимости. Однако накладываемые ограничения не позволяют применять его для более распространенных задач.
Для выбора подходящей комбинации входных переменных используется так называемые генетические алгоритмы [5], которые хорошо приспособлены для задач такого типа, поскольку позволяют производить поиск среди большого числа комбинаций при наличии внутренних зависимостей в переменных.
5.3.2 Сжатие информации. Анализ главных компонент.
Самый распространенный метод понижения размерности - это анализ главных компонент (АГК).
Традиционная реализация этого метода представлена в теории линейной алгебры. Основная идея заключается в следующем: к данным применяется линейное преобразование, при котором направлениям новых координатных осей соответствуют направления наибольшего разброса исходных данных. Для эти целей определяются попарно ортогональные направления максимальной вариации исходных данных, после чего данные проектируются на пространство меньшей размерности, порожденное компонентами с наибольшей вариацией [4]. Один из недостатков классического метода главных компонент состоит в том, что это чисто линейный метод, и соответственно он может не учитывать некоторые важные характеристики структуры данных.
В теории нейронных сетей разработаны более мощные алгоритмы, осуществляющие “нелинейный анализ главных компонент”[3]. Они представляют собой самостоятельную нейросетевую структуру, которую обучают выдавать в качестве выходов свои собственные входные данные, но при этом в ее промежуточном слое содержится меньше нейронов, чем во входном и выходном слоях. (рис 5.3). Сети подобного рода носят название – автоассоциативные сети.
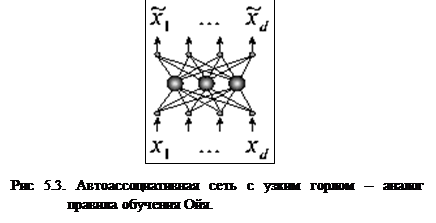
Чтобы восстановить свои входные данные, сеть должна научиться представлять их в более низкой размерности. Базовый алгоритм обучения в этом случае носит название правило обучения Ойя для однослойной сети. Учитывая то, что в такой структуре веса с одинаковыми индексами в обоих слоях одинаковы, дельта-правило обучения верхнего (а тем самым и нижнего) слоя можно записать в виде:
![]() , где
, где
![]()
![]() ,и
,и
![]()
![]() ,
,
![]() , j=1,2,…,d – компонента входного вектора;
, j=1,2,…,d – компонента входного вектора;
![]() , выходы сети j=1,…,d;
, выходы сети j=1,…,d;
d - количество нейронов на входном ми выходном слоях (размерность вектора признаков);
yi - выход с i-го нейрона внутреннего слоя, i=1,…,M
M – количество нейронов на внутреннем слое;
h - коэффициент обучения;
wij=wkj - веса сети , соответственно между входным – скрытым и скрытым – выходным слоями.
Скрытый слой такой сети осуществляет оптимальное кодирование входных данных, и содержит максимально возможное при данных ограничениях количество информации. После обучения внешний интерфейс (wij) (рис.5.4) может быть сохранен и использован для понижения размерности.
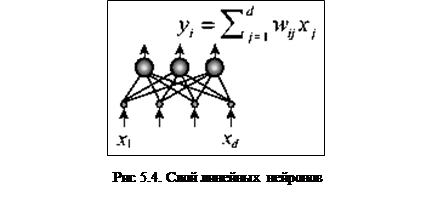
Нелинейный анализ главных компонент.
Главное преимущество нейроалгоритмов в том, что они легко обобщаются на случай нелинейного сжатия информации, когда никаких явных решений уже не существует. Можно заменить линейные нейроны в описанных выше сетях – нелинейными. С минимальными видоизменениями нейроалгоритмы будут работать и в этом случае, всегда находя оптимальное сжатие информации при наложенных ограничениях. Например, простая замена линейной функции активации нейронов на сигмоидную в правиле обучения Ойя:
![]()
приводит к новому качеству.
Таким образом, нейроалгоритмы представляют собой удобный инструмент нелинейного анализа, позволяющий относительно легко находить способы глубокого сжатия информации и выделения нетривиальных признаков.
Похожие работы

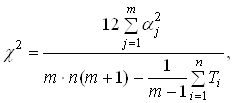
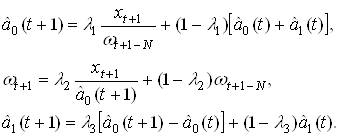
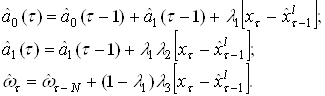
... МП к некритическому экстраполированию результата считается его слабостью. Сети РБФ более чувствительны к «проклятию размерности» и испытывают значительные трудности, когда число входов велико. 5. МОДЕЛИРОВАНИЕ НЕЙРОННЫХ СЕТЕЙ ДЛЯ ПРОГНОЗИРОВАНИЯ СТОИМОСТИ НЕДВИЖИМОСТИ 5.1 Особенности нейросетевого прогнозирования в задаче оценки стоимости недвижимости Использование нейронных сетей можно ...
... в связи с необходимостью упорядоченного сообщения с высоким приоритетом при радикальном изменении окружающих условий и двунаправленностью каналов. Возможности вычисления путей маршрутизации можно применять при построении интегральных схем и проектирования кристаллов процессоров. Нейрокомпьютеры с успехом применяются при обработке сейсмических сигналов в военных целях для определения коорди
... (ШД), адресов (ША) и управления (ШУ). Однокристальные микропроцессоры получаются при реализации всех аппаратных средств процессора в виде одной БИС или СБИС (сверхбольшой интегральной схемы). По мере увеличения степени интеграции элементов в кристалле и числа выводов корпуса параметры однокристальных микропроцессоров улучшаются. Однако возможности однокристальных микропроцессоров ограничены ...


... данных а разбивать входные данные на кластеры. •Рекурсивные сети Элмана, способные обрабатывать последовательности векторов. •Вероятностные сети, аппроксимирующие Байесовские классификаторы с любой степенью точности. Общие принципы, характерные для нейросетей Согласно общепринятым представлениям наиболее общими принципами, характерными для современных нейросетей являются: коннекционизм, ...
0 комментариев