Основные положения теории нейронных сетей
Выбор типа (архитектуры) сети
Постановка задачи классификации сейсмических сигналов
Отбор наиболее информативных признаков для идентификации
Процедура статистической идентификации
Многослойный персептрон
Выводы по разделу
Понижение размерности входов
Выводы по разделу
Определение критерия качества системы и функционала его оптимизации
Формирование обучающей выборки и оценка эффективности обученной нейросетевой модели
Описание входного файла с исходными данными
Заключение
Пример файла отчета
Файл автоматической компиляции программы под Unix -“Makefile”
Навигация
Отбор наиболее информативных признаков для идентификации
Классификация сейсмических сигналов на основе нейросетевых технологий
114641
знак
1
таблица
28
изображений
3.2 Отбор наиболее информативных признаков для идентификации.
Как было показано выше, в сейсмограмме анализируемого события можно выделить достаточно много различных характеристик, однако, далеко не все из них могут действительно нести информацию, существенную для надежной идентификации взрывов и землетрясений. Многочисленные исследования в дискримининтном анализе показали, что выделение малого числа наиболее информативных признаков исключительно важно для эффективной классификации. Несколько тщательно отобранных признаков могут обеспечить вероятность ошибочной классификации существенно меньшую, чем при использовании полного набора.
Ниже представлена процедура отбора наиболее информативных дискриминантных признаков, осуществляемая на основании обучающих реализаций землетрясений и взрывов из данного региона.[8]
В начале каждый вектор xsj = (x(i)sj, iÎ1,p); где sÎ1,2 -номер класса (s=1 - землетрясения s=2 - взрывы), jÎ1,ns , ns -число обучающих векторов данного класса состоит из p признаков, выбранных из эвристических соображений как предположительно полезные для данной проблемы распознавания. При этом число p может быть достаточно велико и даже превышать число имеющихся обучающих векторов в каждом из классов, но для устойчивости вычислений должно выполняться условие p < n1+n2 . Процедура отбора признаков - итерационная и состоит из p шагов на каждом из которых число отобранных признаков увеличивается на единицу. На каждом промежуточном k-м шаге процедура работает с n1+n2 k-мерными векторами xsj(k) (k£p), сформированных из k-1 признаков, отобранных в результате первых k-1 шагов и некоторого нового признака из числа оставшихся. Отбор признаков основан на оценивании по векторам, состоящим из различных признаков, стохастического расстояния Кульбака-Махаланобиса D(k) между распределениями вероятностей векторов xsj(k):
D(k)= (m(k,1) - m(k,2))T S-1n1+n2(k) (m(k,1) - m(k,2)), (6)
где: m(k,1), m(k,2) k - мерные векторы выборочных средних, вычисленные по k-мерным векторам x1j(k) jÎ1,n1 и x2j(k) jÎ1,n2 первого и второго классов; S-1n1+n2(k) есть (k´k)- мерная обратная выборочная матрица ковариаций, вычисленная с использованием всего набора k - мерных векторов x1j(k) jÎ1,n1 и x2j(k) jÎ1,n2
На первом шаге процедуры отбора значения функционала D(1) вычисляются для каждого из p признаков. Максимум из этих p значений достигается на каком то из признаков, который таким образом отбирается как первый информативный. На втором шаге значения функционала D(2) вычисляются уже для векторов, состоящих из пар признаков. Первый элемент в каждой паре - это признак, отобранный на предыдущем шаге, второй элемент пары - один их оставшихся признаков. Таким образом получаются p-1 значения функционала D(2). Второй информативный признак отбирается из условия, что на нем достигается максимум функционала D(2). Далее процедура продолжается аналогично, и на k-м шаге процедуры отбора вычисляются значения функционала D(k) по обучающим векторам, состоящим из k признаков. Первые k-1 компонент этих векторов есть информативные признаки, отобранные на предыдущих k-1 шагах, последняя компонента - один из оставшихся признаков. В качестве k-го информативного признака отбирается тот признак, для которого функционал D(k) -максимален.
Описанная процедура ранжирует порядок следования признаков в обучающих векторах так, чтобы обеспечить максимально возможную скорость возрастания расстояния Махаланобиса (6) с ростом номера признака. Для селекции множества наиболее информативных признаков на каждом шаге k=1,2,...,p описанной выше итерационной процедуры ранжирования признаков по информативности сохраняются номер j(k) в исходной таблице признаков и имя выбранного признака, также вычисляется теоретическое значение полной вероятности ошибки классификации P(k) по формуле Колмогорова-Деева [12].
P(k) = (1/2)[1 - Tk(D(k)/s(k)) + Tk(-D(k)/ s(k))],
где k - число используемых признаков
s2(k) = [(t+1)/t][r1+r2+D(k)]; t = [(r1+r2)/r1r2]-1; r1=k/n1; r2=k/n2 (7)
Tk(z) = F(z) + (1/(k-1) ) (a1 - a2H1(z) + a3H2(z) - a4H3(z)) f(z),
F(z) - функция стандартного Гауссовского распределения вероятностей; f(z) - плотность этого распределения; Hi(z) - полином Эрмита степени i, i=1,2,3; aj, j=1,...,4 - некоторые коэффициенты, зависящие от k, n1, n2 и D(k) [12]. Эта формула, как было показано в различных исследованиях, имеет хорошую точность при размерах выборок порядка сотни и rs<0.3, s=1,2.
Функция D(k), получаемая в результате процедуры ранжирования признаков, возрастает с ростом k, однако, на практике ее рост, как правило, существенно замедляется при k® p. В этом случае функция P(k) на каком то шаге k0 между 1 и p имеет минимум. В качестве набора наиболее информативных признаков и принимается совокупность признаков, отобранных на шагах 1,...,k0 описанной выше процедуры. Именно они обеспечивают минимальную полную вероятность ошибочной классификации, которая может быть получена при данных обучающих наблюдениях.
Похожие работы

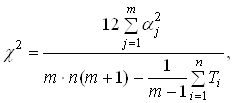
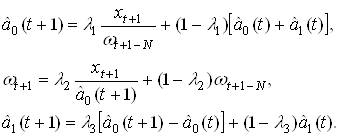
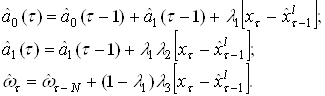
... МП к некритическому экстраполированию результата считается его слабостью. Сети РБФ более чувствительны к «проклятию размерности» и испытывают значительные трудности, когда число входов велико. 5. МОДЕЛИРОВАНИЕ НЕЙРОННЫХ СЕТЕЙ ДЛЯ ПРОГНОЗИРОВАНИЯ СТОИМОСТИ НЕДВИЖИМОСТИ 5.1 Особенности нейросетевого прогнозирования в задаче оценки стоимости недвижимости Использование нейронных сетей можно ...
... в связи с необходимостью упорядоченного сообщения с высоким приоритетом при радикальном изменении окружающих условий и двунаправленностью каналов. Возможности вычисления путей маршрутизации можно применять при построении интегральных схем и проектирования кристаллов процессоров. Нейрокомпьютеры с успехом применяются при обработке сейсмических сигналов в военных целях для определения коорди
... (ШД), адресов (ША) и управления (ШУ). Однокристальные микропроцессоры получаются при реализации всех аппаратных средств процессора в виде одной БИС или СБИС (сверхбольшой интегральной схемы). По мере увеличения степени интеграции элементов в кристалле и числа выводов корпуса параметры однокристальных микропроцессоров улучшаются. Однако возможности однокристальных микропроцессоров ограничены ...


... данных а разбивать входные данные на кластеры. •Рекурсивные сети Элмана, способные обрабатывать последовательности векторов. •Вероятностные сети, аппроксимирующие Байесовские классификаторы с любой степенью точности. Общие принципы, характерные для нейросетей Согласно общепринятым представлениям наиболее общими принципами, характерными для современных нейросетей являются: коннекционизм, ...
0 комментариев