Виды безработицы
Система показателей, характеризующих безработицу
Методы, используемые для измерения состояния безработицы
Анализ динамики безработицы с использованием временных рядов
Определение наличия тенденции средних и дисперсии на базе методов: Метод проверки существенности разности средних
Сравнивается каждый уровень ряда со всеми предыдущими, при этом
Определение наличия тенденции автокорреляции
Выявление основной тенденции
Автокорреляция уровней временного ряда
Многофакторный корреляционно – регрессионный анализ безработицы
Прогнозирование безработицы
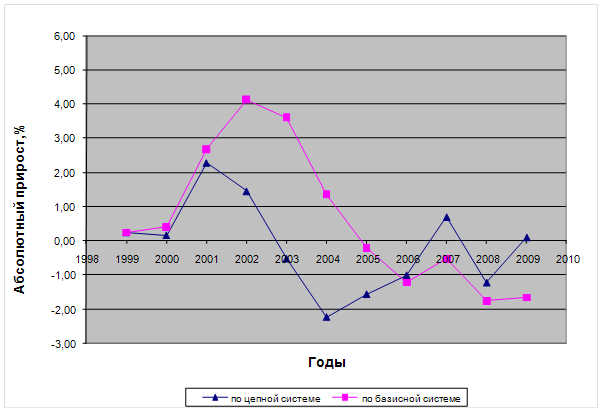
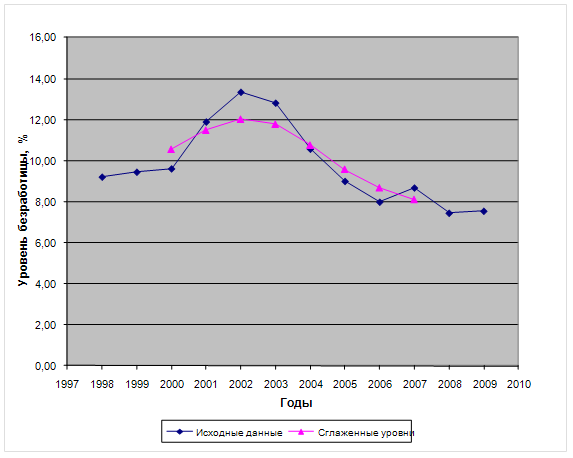
Анализ динамики уровня безработицы
Определение наличия тенденции
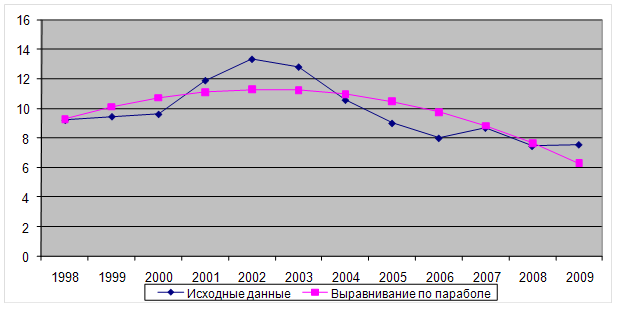
Метод аналитического выравнивания и определение параметров
Многофакторный корреляционно - регрессионный анализ
Прогнозирование уровня безработицы
Распределение численности безработного населения по уровню образования в Республике Бурятия
Уровень безработицы по возрастным группам в Республике Бурятия
Навигация
Прогнозирование безработицы
Статистический анализ и прогнозирование безработицы
90014
знаков
21
таблица
14
изображений
3.4. Прогнозирование безработицы
Определив наличие тенденции, можно начать прогнозирование. Прогнозирование проводится следующими методами:
1)на основе средних показателей динамики;
2)на основе экстраполяции тренда;
3)на основе скользящих и экспоненциальных средних.
I. Сначала проведем прогнозирование методом среднего абсолютного прироста. Для этого надо проверить выполняются ли предпосылки. Вычисляем данные для подстановки в формулы предпосылок:
ρ2= 310,14
σ2ост = 250,11
т.к. σ2ост< ρ2 , условие выполняется, значит можно строить прогноз на основе среднего абсолютного прироста. Вычислим средний абсолютный прирост:
![]() , где yp- прогнозируемый уровень; yb- конечный уровень ряда как наиболее близкий к прогнозируемому; L-период упреждения; ∆- средний абс.прирост.
, где yp- прогнозируемый уровень; yb- конечный уровень ряда как наиболее близкий к прогнозируемому; L-период упреждения; ∆- средний абс.прирост.
Подставляем значения yb=54,13 L=1 ∆=1,91 в функцию прогноза:
yp=54,13+1,91*1=56,04 – прогноз на 2006г.
yp=54,13+1,91*2=57,95 – прогноз на 2007г.
Фактически численность безработных в 2006г. составила 60,6 тыс.чел.
Вычислим ошибку прогноза для сравнения методов прогнозирования на точность: 60,6-56,04=4,56 тыс.чел.
Теперь составим прогноз методом среднего темпа роста. Вычислим средний темп роста: yp= yb*КL
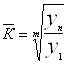 =1,0096
=1,0096
Подставим это значение в формулу и составим прогноз на 2006г.:
yp=54,13*1,00961=54,65
Вычислим ошибку: 60,6-54,65=5,95тыс.чел.
Так как ошибка при прогнозировании методом среднего абсолютного прироста меньше ошибки при прогнозировании методом среднего темпа роста, то можно сделать вывод, что прогнозирование первым методом дает более точные результаты. Поэтому мы оставляем для анализа результатов данные прогноза полученные методом среднего абсолютного прироста. Составим диаграмму при прогнозировании методом абсолютного прироста.
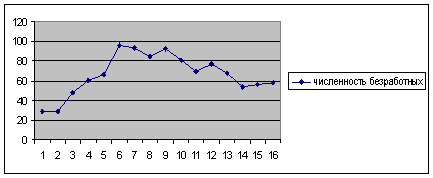
Рис. 4.Численность безработных при прогнозировании «методом абсолютного прироста»
II. Следующий способ прогнозирования - методом экстраполяции тренда.
Ранее по аналитическому выравниванию нашли уравнение параболы второй степени: у =13,37+13,94t-1,0017t2
Сделаем прогноз на 2006г., примем t=7, т.к. нумерация дат определена с середины ряда, т.е. ∑t=0.
уp=13,37+13,94*7-1,0017*49=60,87 – прогноз на 2006г.
Определим доверительный интервал прогноза, в основе которого лежит показатель колеблемости уровней ряда. Колеблемость уровней ряда определяется по формуле: Sy =
Sy=91,44
Интервал определяется с помощью ошибки прогноза Sp= Sy*Q, где Q- поправочный коэффициент, учитывающий период упреждения.
Q= = 1,2127
Тогда ошибка прогноза: Sp=91,44*1,2127=110,886
Соответственно доверительный интервал прогноза составит: уp+t*Sp, где t-табличное значение t-критерия Стьюдента. При ά=0,05 и числе степеней свободы n-3= 11 t=2,2010.
уp+2,2010*110,886 или 61,87 +244,061, т.е. -182,2< уp <305,93
Значит, прогнозная величина находится в данном интервале.
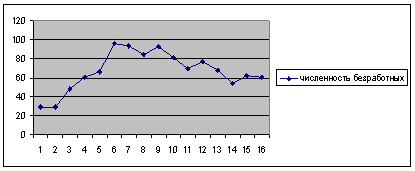
Рис.5. Численность безработных при прогнозировании «методом экстраполяции тренда»
III. Метод скользящих и экспоненциальных средних.
Ранее в своих расчетах я определила, что ряд не содержит периодических колебаний и отсутствуют трендовая компонента Т и циклическая (сезонная) компонента S. Поэтому нет необходимости использовать метод скользящих средних.
Метод экспоненциальных средних.
Экспоненциальное сглаживание является простым методом, который в ряде наблюдений позволяет строить приемлемые прогнозы наблюдаемых временных рядов. Суть метода в том, что исходный ряд x(t) сглаживается с некоторыми экспоненциальными весами, образуется новый временной ряд S(t) (с меньшим уровнем шума), поведение которого можно прогнозировать.
Веса в экспоненциальных средних устанавливаются в виде коэффициентов ά(|ά|<1). В качестве весов используется ряд:
ά; ά(1- ά); ά(1- ά)2; ά(1- ά)3 и т.д.
Экспоненциальная средняя определяется по формуле: ![]()
где Qt– экспоненциальная средняя (сглаженное значение уровня ряда) на момент t; ά- вес текущего наблюдения при расчете экспонен. средней; yt–фактический уровень ряда; Qt-1-экспонен. средняя предыдущего периода.
Каждый новый прогноз основывается на предыдущем прогнозе:
St= St-1+ά(yt -1- St-1),
где St- прогноз для периода t; St-1-прогноз предыдущего периода; ά- сглаживающая константа; yt -1- предыдущий уровень.
Например, St=29,3+0,5*(29,25-29,3)=29,275.
При прогнозе учитывается ошибка предыдущего прогноза, т.е. каждый новый прогноз Stполучается в результате корректировки предыдущего прогноза с учетом ошибки.
Таблица 12. Расчет прогноза и ошибки.
| 1992 | 1993 | 1994 | 1995 | 1996 | 1997 | 1998 | 1999 | 2000 | 2001 | 2002 | 2003 | 2004 | 2005 | 2006 | |
| yt | 29,3 | 29,25 | 48,03 | 60,06 | 66,39 | 96,26 | 93,59 | 84,74 | 92,91 | 81,26 | 69,73 | 76,85 | 67,9 | 54,13 | - |
| прогноз | - | 29,3 | 29,28 | 38,65 | 49,36 | 57,87 | 77,07 | 85,33 | 85,03 | 88,97 | 85,12 | 77,42 | 77,14 | 72,52 | 60,32 |
| ошибка | - | -0,05 | 18,76 | 21,41 | 17,03 | 38,39 | 16,52 | -0,59 | 7,876 | -7,71 | -15,4 | -0,57 | -9,24 | -18,4 | - |
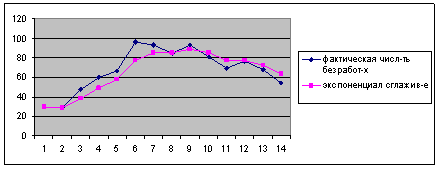
Рис. 6. Экспоненциальное сглаживание.
При прогнозировании могут использоваться экспоненциальные средние более высоких порядков, полученные путем многократного сглаживания. Экспоненциальная средняя К-го порядка:
Qt(к)= ά Qt(к-1)+(1- ά) Qt-1(к)
Экспоненциальные средние 2-го, 3-го порядка применяются в адаптивном прогнозировании по полиномиальным моделям. Для прогноза использован линейный тренд: y=a+bt. Его параметры связаны с экспоненциальными средними 1-го (Qt(1)) и 2-го (Qt(2)) порядков:
![]()
![]()
соответственно: ![]()
![]()
Необходимо задать начальные условия Qt-1к:
![]()
![]()
Линейный тренд: уt=49,25+2,49t
Параметр сглаживания ά определим: ά=2/(n+1).
Так как n=14, то ά=2/(14+1)=0,13.
Соответственно (1- ά)/ά=(1-0,13)/0,13=6,69, ά/(1- ά)=0,13/(1-0,13)=0,15.
Начальные условия для экспоненциального сглаживания:
Qо(1)=а-6,69*b=49,25-6,69*2,49=32,59
Qo(2)=а-2*6,69*b=49,25-2*6,69*2,49=15,93
Экспоненциальные средние Qt(1) и Qt(2) составят:
Qt(1)= άyt+(1- ά) Qt-1(1)=0,13*84,11+(1-0,13)*32,59=39,28, где yt=yt=n;Qt-1(1)= Qо(1)
Qt(2)= άQt(1)+(1- ά) Qt-1(2)=0,13*39,28+(1-0,13)*15,93=18,97, где Qt-1(2)= Qo(2)
Тогда скорректированные параметры линейного тренда составят:
![]() 2*39,28-18,97=59,59
2*39,28-18,97=59,59
![]() =0,15*(39,28-18,97)=3,0465
=0,15*(39,28-18,97)=3,0465
Прогноз производим по модели: ![]() , где l-период упреждения.
, где l-период упреждения.
Тогда при l=1 прогноз на 2006г. составит: уp=59,59+3,0465*1 =60,6т.ч.
Соответственно при прогнозе на 2007г. берем l=2: уp=59,59+3,0465*2=65,683.
Таким образом, по результатам проведенного анализа следует, что численность безработных в 2006 году возрастет по сравнению с 2005г. на 6,5 тыс.чел. или 12% и составит 60,6 тыс.чел., а в 2007г. возрастет на 11,55 тыс.чел. и составит 65,68 тыс.человек.
Похожие работы





... степень сбалансированности системы подготовки кадров с потребностью экономики в квалифицированных работниках. 6.2. Статистика занятости и безработицы Занятость - одна из важнейших социально-экономических проблем рыночной экономики. Ее статистическое отражение неоднократно обсуждалось на международных конференциях статистиков труда (1949, 1957, 1982, 1993 гг.), проводимых Международным бюро ...
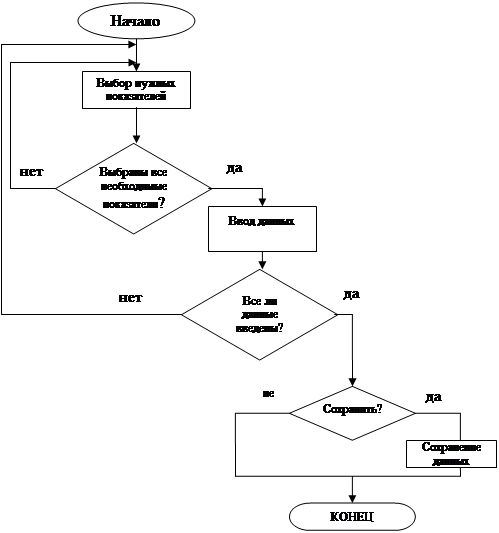
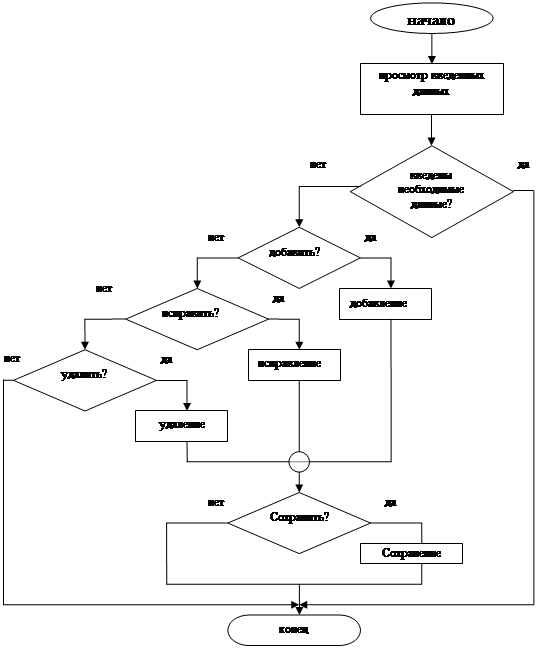
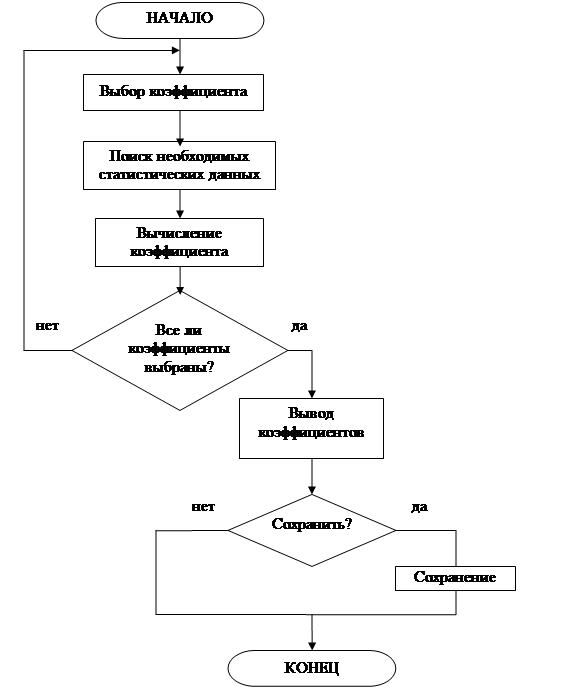

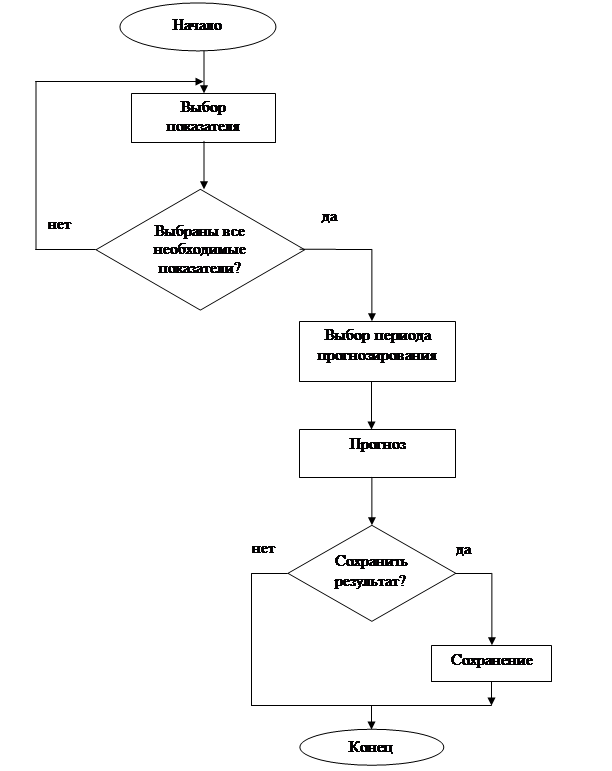
... с распространением явления неполная занятость: , (1.11) где ТНЗ– численность занятых неполное рабочее время [1]. 2 ПРОЕКТНАЯ ЧАСТЬ В курсовом проекте для проведения анализа и прогнозирования рынка труда применяются динамические ряды, тренды, а также алгоритмы и блок-схемы. Для начала необходимо провести анализ требований к данной модели. 2.1 Анализ ...
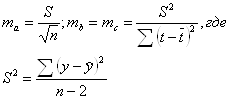
... и сельского хозяйства. Хотя и наблюдается рост средней продолжительности поисков работы, что 60-80 % трудоустраивающихся находят работу менее чем за 4 месяца 3 Статистический анализ занятости населения 3.1 Анализ динамики уровня безработицы Анализ динамики явления производится на основе рядов динамики. Ряд динамики, или временной ряд – это последовательность упорядоченных во времени ...
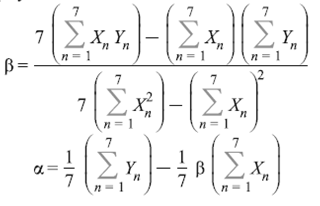
... полномочий; · методологическое и организационное обеспечение формирования показателей, характеризующих уровень достижения целей социально-экономического развития государства, и показателей деятельности федеральных органов исполнительной власти; · интеграцию статистических информационных ресурсов на основе методологической и технологической совместимости для эффективного их использования при ...
0 комментариев