Навигация
Этап. Проверка наличия необходимых свойств у остатка модели
17491
знак
9
таблиц
6
изображений
3 этап. Проверка наличия необходимых свойств у остатка модели.
Таблица 8.
| ВЫВОД ОСТАТКА | |||
| Наблюдение | Предсказанное 101,3 | Остатки | Стандартные остатки |
| 1 | 101,0953062 | -0,095306249 | -0,079492648 |
| 2 | 101,1406289 | -0,540628945 | -0,450925589 |
| 3 | 98,91981687 | 2,280183127 | 1,901845857 |
| 4 | 101,3219197 | -0,521919726 | -0,43532068 |
| 5 | 101,9564375 | -0,956437461 | -0,797741462 |
| 6 | 107,3045155 | 1,495484488 | 1,247347611 |
| 7 | 101,0499836 | 1,150016446 | 0,959201034 |
| 8 | 101,0046609 | 0, 195339141 | 0,162927675 |
| 9 | 102,5909552 | -1,790955196 | -1,493792616 |
| 10 | 101,1406289 | -0,340628945 | -0,284110403 |
| 11 | 101,7751467 | -0,87514668 | -0,729938779 |
График 2.
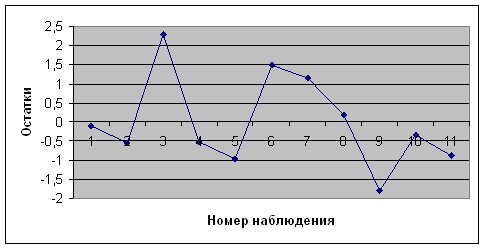
Проверяем случайность остатков. Согласно предпосылкам МНК возмущение должно быть случайной величиной с нулевым математическим ожиданием. Это имеет место для получения однофакторной регрессии. График остатка (возмущения, ошибки) располагается в горизонтальной полосе. Имеется большое количество локальных экстремумов (максимумов и минимумов). ![]() -значит остатки случайные.
-значит остатки случайные.
Согласно следующей предпосылке остатки должны быть равно изменчивы. Для проверки этой предпосылки используем в Microsoft Excel инструмент "Среднее значение".
![]()
![]()
![]() -0,0000000000000026
-0,0000000000000026![]() .
.
Проверка на гомоскедастичность по методу Гольдфельда-Квандта невозможна, так как недостаточно наблюдений (должно быть n>12m) /
Проверим отсутствие автокорреляции остатков. Для этого чаще всего используют критерий Дарбина Уотсона (d-критерий):
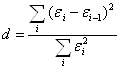 .
.
![]() находится в Microsoft Excel при помощи инструмента "СУММКВРАЗН"
находится в Microsoft Excel при помощи инструмента "СУММКВРАЗН"
![]() =29,573
=29,573
![]() , берется из таблицы 4.1 "SS"/ "остаток"
, берется из таблицы 4.1 "SS"/ "остаток"
![]() 14,374
14,374
d=![]() .
.
Критерий Дарбина Уотсона (d-критерий): n=12, m=1, ![]() , dl=0,97,du=1,33
, dl=0,97,du=1,33
![]() I dl II du III IV 4-du V 4-dl VI
I dl II du III IV 4-du V 4-dl VI
0 0,97 1,33 2 2,67 3,03 4
d=2,057![]() III, IV. Значит нет оснований отклонить предположение об отсутствии автокорреляции соседних остатков по d-критерию с уровнем значимости
III, IV. Значит нет оснований отклонить предположение об отсутствии автокорреляции соседних остатков по d-критерию с уровнем значимости ![]() . Следующее необходимое условие: остатки должны иметь распределение Гаусса. можно ограничиться критерием размахов (RS - критерий).
. Следующее необходимое условие: остатки должны иметь распределение Гаусса. можно ограничиться критерием размахов (RS - критерий).
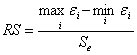 .
.
![]() -стандартная ошибка модели
-стандартная ошибка модели
![]() =1,263784889.
=1,263784889.
![]() находится в Microsoft Excel при помощи функции "МАКС".
находится в Microsoft Excel при помощи функции "МАКС".
![]() =.2,280183127
=.2,280183127
![]() находится в Microsoft Excel при помощи функции "МИН".
находится в Microsoft Excel при помощи функции "МИН".
![]() =-1,790955196
=-1,790955196
RS=3,22138
Критерий размахов, RS - критерий: n=12, α =0,05, a=2,8, b=3,91.
Если a <RS < b, то остатки имеют нормальный закон распределения с уровнем α =0,05.
2,8 <3,22138 < 3,91.
Вывод: Все предпосылки регрессионного анализа выполняются с уровнем α =0,05. Значит модель успешно прошла проверку оценки ее качества.
3. Предложить модели тренда изучаемого показателя. Оценить качество моделейЛинейный тренд у показателя связан с ситуацией, когда наибольшим является коэффициент автокорреляции первого порядка.
![]() >0,7, при это
>0,7, при это ![]() , где a,b
, где a,b![]() R.
R.
При выборе модели тренда нельзя выбирать функцию тренда с числом параметров при факторе время больше шестой части n, то есть m>![]() .
.
Существует несколько видов тренда (линейный, полиномиальный, степенной, логарифмический, гиперболический). Из них необходимо выбрать наилучший вид тренда.
Построим графики основных типов тренда. Для выявления наилучшего уравнения тренда определим параметры трендов. Результаты расчетов представим в таблице 9. Согласно, данным этой таблицы наилучшей моделью тренда является полиномиальный тренд, для которого значение коэффициента детерминации наиболее высокое.
График 3. Линейный тренд.
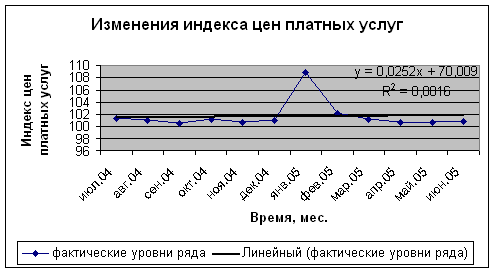
График 4. Полиномиальный тренд.
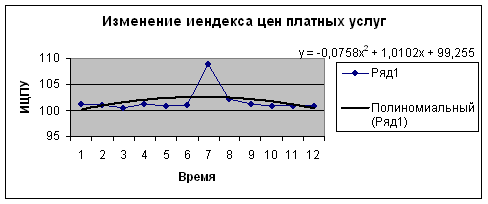
График 5. Степенной тренд.
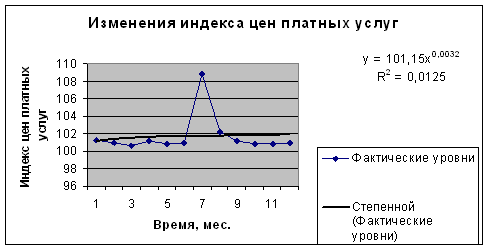
График 6. Экспоненциальный тренд.
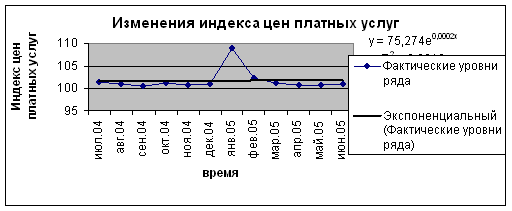
Таблица 9.
| Тип тренда | Уравнение |
|
| Линейный |
| 0,0016 |
| Полиномиальный |
| 0,1371 |
| Степенной |
| 0,0125 |
| Экспоненциальный |
| 0,0016 |
Итак, рассмотрим модель тренда![]() . Но у показателя Y явно нет никакой тенденции (тренда), так как для
. Но у показателя Y явно нет никакой тенденции (тренда), так как для ![]()
![]() =0.1371<0,3. Модель неудачна.
=0.1371<0,3. Модель неудачна.
4. Используя значимые в целом и по параметрам модели (с приемлемым уровнем значимости), для которых выполняются все предпосылки метода наименьших квадратов (свойств остатков), получит прогнозы изучаемого показателя на два следующих месяца.
Модели ![]() ,
, ![]() значимы в целом и по параметрам и для них выполняются все предпосылки МНК. По этим моделям можно строить прогнозы изучаемого показателя. Различают точечный и доверительный прогнозы показателя. Точечный прогноз получают путем подстановки в уравнение регрессии значения фактора x, и он имеет нулевую вероятность. Этот прогноз полезен при формировании доверительного прогноза.
значимы в целом и по параметрам и для них выполняются все предпосылки МНК. По этим моделям можно строить прогнозы изучаемого показателя. Различают точечный и доверительный прогнозы показателя. Точечный прогноз получают путем подстановки в уравнение регрессии значения фактора x, и он имеет нулевую вероятность. Этот прогноз полезен при формировании доверительного прогноза.
Пусть в модели ![]() Х5 в последующих два будет увеличиваться на столько на сколько и в прошлом месяце 1,7% (в% к предыдущему периоду). Значит Х5 в следующем периоде уменьшится на 1%.
Х5 в последующих два будет увеличиваться на столько на сколько и в прошлом месяце 1,7% (в% к предыдущему периоду). Значит Х5 в следующем периоде уменьшится на 1%.
![]() 1,017*101,69
1,017*101,69![]() 103,41
103,41
![]() 55,68+0,453*103,41=102,52.
55,68+0,453*103,41=102,52.
Доверительная вероятность равна 95%
![]()
где 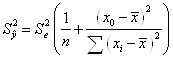
![]()
![]() =1,59,
=1,59, ![]() =0,55, тогда
=0,55, тогда
102,52-5,12*0,55≤![]() ≤102,52+5,12*0,55
≤102,52+5,12*0,55
99,704≤![]() ≤105,33.
≤105,33.
4. Сравнить полученные прогнозы показателей с фактическими данными
Получили, что в последующих двух месяцах изучаемый показатель будет колебаться в интервале от 99,704 до 105,33.
В июле ![]() 0,99*101,69
0,99*101,69![]() 100,67
100,67
![]() 55,68+0,453*100,67=101
55,68+0,453*100,67=101![]() 100,9 (как и фактические данные).
100,9 (как и фактические данные).
В августе![]() 0,98*101,69
0,98*101,69![]() 99,65
99,65
![]() 55,68+0,453*99,65
55,68+0,453*99,65![]() 100,82 (как и фактические данные)
100,82 (как и фактические данные)
Похожие работы
... , ; , , ; Случай группированных данных. Подставим найденные значения в уравнеиня линейной регрессии Y на x и X на y. Получим: y(x) = 17,14 – 1,4*x; x(y) = 10,83 – 0,54*y; Проверка: Задание 5 Для негруппированных данных нанести графики выборочных регрессионных прямых на диаграмму рассеивания. Задание 6 Для негруппированных данных по найденным оценкам параметров ...
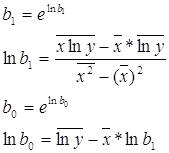
... теперь на основе выше рассчитанного доверительный интервал: 3.Сравнительный анализ расчетов, произведенных с помощью формул Excel и с использованием «Пакета анализа» Если сравнивать между собой результаты, полученные при расчетах линейной и степенной регрессионной модели, то можно выделить следующее: 1. Значение b1 в линейной регрессионной модели < b1 в степенной регрессионной ...
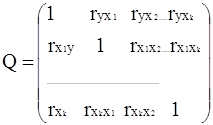
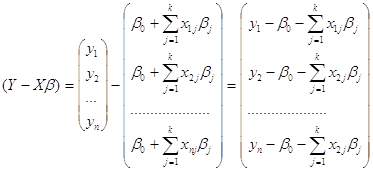
... 9472;───────┴─────────┘ Реализация алгоритма многомерного регрессионного анализа начинается с расчета важнейших статистических характеристик исходной информации и матрицы выборочных парных коэффициентов корреляции. Рассмотрим более подробно вариационные характеристики переменной у: ...
... деле независимой постоянной составляющей в отклике нет (альтернатива – гипотеза Н1: a ¹ 0). Для проверки этой гипотезы, с заданным уровнем значимости g, рассчитывается t-статистика, для парной регрессии: Значение t-статистики сравнивается с табличным значением tg/2(n-1) - g/2-процентной точка распределения Стьюдента с (n-1) степенями свободы. Если |t| < tg/2(n-1) – гипотеза Н0 не ...
0 комментариев