Основные теоремы теории вероятностей
Локальная формула Муавра-Лапласа
Дисперсия ДСВ и ее свойства
Дифференциальная функция распределения и ее свойства
Математическое ожидание
Числовые характеристики системы двух случайных величин. Корреляционный момент. Коэффициент корреляции
Понятие и виды статистических гипотез
Особенности статистического анализа количественных и качественных показателей
Определение вариационных рядов. Графическое изображение вариационных рядов
Проверка адекватности модели регрессии
Концепция Data Mining
Понятие и модели дисперсионного анализа
Навигация
Понятие и модели дисперсионного анализа
О теории вероятностей
70295
знаков
2
таблицы
1
изображение
45. Понятие и модели дисперсионного анализа
Дисперсионный анализ позволяет ответить на вопрос о наличии существенного влияния некоторых факторов на изменчивость фактора, значения которого могут быть получены в результате опыта. При проверке статистических гипотез предполагается случайность вариации изучаемых факторов. В дисперсионном анализе один или несколько факторов изменяются заданным образом, причем, эти изменения могут влиять на результаты наблюдений. Исследование такого влияния и является целью дисперсионного анализа.
Идея дисперсионного анализа заключается в том, что основная дисперсия разлагается в сумму составляющих ее дисперсий, каждое слагаемое которой соответствует действию определенного источника изменчивости. Например, в двухфакторном анализе мы получим разложение вида:
sС2=sА2+sВ2+sАВ2+dZ’2,
где
sС2 –общая дисперсия изучаемого признака С
sА2 –доля дисперсии, вызванная влиянием фактора А
sВ2 - доля дисперсии, вызванная влиянием фактора В
sАВ2 - доля дисперсии, вызванная взаимодействием факторов А и В
dZ’2 –доля дисперсии, вызванная неучтенными случайными причинами (случайная дисперсия).
В дисперсионном анализе рассматривается гипотеза: Н0 – ни один из рассматриваемых факторов не оказывает влияния на изменчивость признака. Значимость каждой из оценок дисперсии проверяется по величине ее отношения к оценке случайной дисперсии и сравнивается с соответствующим критическим значением, при уровне значимости a, с помощью таблиц критических значений F – распределения Фишера-Снедекора. Гипотеза Н0 относительно того или иного источника изменчивости отвергается, если Fрасч.> Fкр.
В дисперсионном анализе рассматриваются эксперименты трех видов:
А) эксперименты, в которых все факторы имеют систематические (фиксированные) уровни;
Б) эксперименты, в которых все факторы имеют случайные уровни;
В) эксперименты, в которых есть факторы, имеющие случайные уровни, а так же факторы, имеющие фиксированные уровни.
Все три случая соответствует трем моделям, которые рассматриваются в дисперсионном анализе.
Однофакторный дисперсионный анализ.
Рассмотрим единичный фактор, который принимает р различных уровней, и предположим, что на каждом уровне сделано n наблюдений, что дает N = np наблюдений. (все факторы имеют фиксированные уровни)
Пусть результаты представлены в виде Хij (i=1,2...,p; j=1,2...,n).
Предполагается, что доля каждого уровня n наблюдений имеется средняя, которая равна сумме общей средней и ее вариации обусловленной выбранным уровнем:
Xij = m + Ai + eij,
где m - общая средняя;
Ai– эффект, обусловленный i-м уровнем фактора;
eij– вариация результатов внутри отдельного уровня фактора. С помощью члена eijпринимаются в расчет все неконтролируемые факторы.
Пусть наблюдения на фиксированном уровне фактора нормально распределены относительно среднего значения m + Aiс общей дисперсией s2.
Тогда (точка вместо индекса обозначает усреднение соответствующих наблюдений по этому индексу):
Xij – X.. = (Xi. – X..) + (Xij – Xi.).
Иначе первую формулу можно записать: S = S1 + S2. Величина S1 вычисляется по отклонениям р средних от общей средней X.. , поэтому S1 имеет (р-1) степеней свободы. Величина S2 вычисляется по отклонениям N наблюдений от р выборочных средних и, следовательно, имеет N – р = np – p = p(n - 1) степеней свободы. S имеет (N -1) степеней свободы.
Если гипотеза о том, что влияние всех уровней одинаково, справедлива, то обе величины М1 и М2 будут несмещенными оценками s2. Значит, гипотезу можно проверить, вычислив отношение (М1/М2) и сравнив его с Fкр. с n1= (р-1) и n2= (N – р) степенями свободы.
Если Fрасч.> Fкр. , то гипотеза о незначимом влиянии фактора А на результат наблюдений не принимается.
Многофакторный дисперсионный анализ. Дисперсионный анализ в Excel.
Дисперсионный анализ позволяет ответить на вопрос о наличии существенного влияния некоторых факторов на изменчивость фактора, значение которого могут быть получены в результате опыта. При проверке статистических гипотез предполагается случайность вариации изучаемых факторов. В дисперсионном анализе один или несколько факторов изменяются заданным образом, причем, эти изменения могут влиять на результаты наблюдений. Исследование такого влияния и является целью дисперсионного анализа. Идея дисперсионного анализа заключается в том, что основная дисперсия разлагается на сумму составляющих ее дисперсий, каждое слагаемое которой соответствует действию определенного источника изменчивости. Например, в двухфакторном анализе мы получим разложение вида:
sC2=sA2 + sB2 + sAB2 + dZ2
sC2 – общая дисперсия изучаемого признака С;
sA2 – доля дисперсии, вызванная влиянием фактора А;
sB2 – доля дисперсии, вызванная влиянием фактора В;
sAB2 – доля дисперсии, вызванная взаимодействием факторов А и В;
dZ2 – доля дисперсии, вызванная неучтенными случайными причинами (случайная дисперсия);
В дисперсионном анализе рассматривается гипотеза Н0 – и один из рассматриваемых факторов не оказывает влияния на изменчивость признака. Значимость каждой из оценок дисперсии проверяется по величине ее отношения к оценке случайной дисперсии и сравнивается с соответствующим критическим значением, при уровне значимости a, с помощью таблиц критических значений F-распределения Фишера-Снедекора. Гипотеза Н0 относительно того или иного источника изменчивости отвергается, если Fрасч>Fкр. В дисперсионном анализе рассматриваются эксперименты 3 видов:
1. эксперименты, в которых все факторы имеют систематические (фиксированные) уровни;
2. эксперименты, в которых все факторы имею случайные уровни;
3. эксперименты, в которых есть факторы, имеющие случайные уровни, а так же факторы, имеющие случайные уровни.
Двухфакторный дисперсионный анализ с повторениями представляет собой более сложный вариант однофакторного анализа, включающего более чем одну выборку для каждой группы данных. Двухфакторный дисперсионный анализ позволяет статистически обосновать существенность влияния факторных признаков А и В взаимодействия факторов (А и В) на результативный фактор F.
Двухфакторный дисперсионный анализ без повторений позволяет оценить существенность воздействия факторов А и В на результирующий фактор без учета воздействия взаимодействии факторов А и В.
46. Оценка методом наименьших квадратов коэффициентов регрессии
Регрессионный анализ – один из основных методов современной мат статистики. Корреляционный анализ позволяет установить существует или не существует зависимость м/у парами наблюдений, то регрессионный анализ дает целый арсенал методов построения соответствующих зависимостей. Классическим методом оценивания коэффициентов уравнения регрессии является метод наименьших квадратов (МНК).
На основании известных n пар наблюдений (xi, yi) делается предположение о виде зависимости, например:
y=a+bx,
где y – зависимая (результативная) переменная, х – независимая (факторная) переменная.
Пусть переменная x задается точно (без ошибок), тогда отклонение наблюдений yi от зависимости y=a+bx является случайным и параметры a и b можно найти из условия минимизации суммы квадратов ошибок
εi=yi–a–bxi
S= Sεi2→ min,
S= S( yi–a–bxi)2→ min,
Эта система носит название системы нормальных уравнений Гаусса, т.к. получена из условия минимизации суммы квадратов отклонении, в предположении, что xi – фиксированы, т.е. отклонения перпендикулярны оси ОХ.
Похожие работы
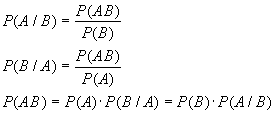
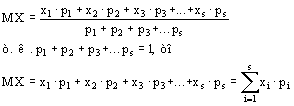
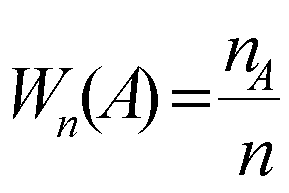
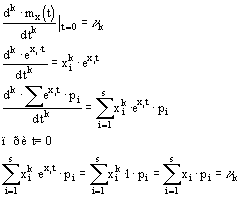
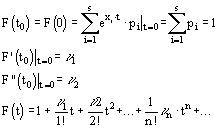
... Доказать: По определению второй смешанной производной. Найдем по двумерной плотности одномерные плотности случайных величин X и Y. Т.к. полученное равенство верно для всех х, то подинтегральные выражение аналогично В математической теории вероятности вводится как базовая формула (1) ибо предлагается, что плотность вероятности как аналитическая функция может не существовать. Но т.к. в нашем ...
... равна 0,515). Конец 19 в. и 1-я половина 20 в. отмечены открытием большого числа статистических закономерностей в физике, химии, биологии и т.п. Возможность применения методов теории вероятностей к изучению статистических закономерностей, относящихся к весьма далёким друг от друга областям науки, основана на том, что вероятности событий всегда удовлетворяют некоторым простым соотношениям, о ...
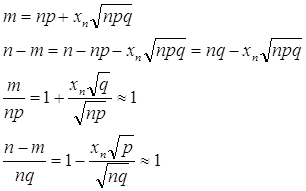
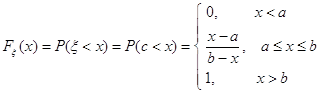
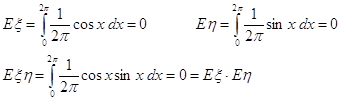
... {ξn (ω )}¥n=1 . Поэтому, во-первых, можно говорить о знакомой из математического анализа (почти) поточечной сходимости последовательностей функций: о сходимости «почти всюду», которую в теории вероятностей называют сходимостью «почти наверное». Определение 46. Говорят, что последовательность с. в. {ξn } сходится почти наверное к с. в. ξ при n ® ¥ , и пишут: ξn ...
... ничего другого, кроме как опять же события и . Действительно, имеем: *=, *=, =, =. Другим примером алгебры событий L является совокупность из четырех событий: . В самом деле: *=,*=,=,. 2.Вероятность. Теория вероятностей изучает случайные события. Это значит, что до определенного момента времени, вообще говоря, нельзя сказать заранее о случайном событии А произойдет это событие или нет. Только ...
0 комментариев