Семестр: Отладка разработанного ПО и оформление протоко-
В строке ...SiSj... символы Si и Sj входят в одну и ту
В множество L(U) самых левых символов нетерминального
Пусть между некоторыми двумя символами Si и Sj сущес-
I i 1
Не предусмотрен выход при выполнении условия R > R , так как
Потом повторяется п. 5
Если выполнение шага 4 пpиведет к тому, что значения всех
Перевод инфиксной записи в польскую. Всякий раз, когда в
Когда редуцируется основа XY..Z, тетрады для всех нетер-
Опреанды и операторы
Если сканируемый символ - унарный оператор, то он приме-
А * В + С * D => *, A, B, T1 ┐ тетрады располагаются в
Устраняет недостатки программы,вызванные небрежностью или
Проверяется
непртиворечивость типов получателя и ис-
ДИСПЛЕЙ
Выделение памяти под рамку в процессе трансляции
ОРГАНИЗАЦИЯ ПАМЯТИ ВО ВРЕМЯ ТРАНСЛЯЦИИ
Алгоритм Биледи
Возможные параметры описания переменных и процедур
Навигация
Семестр: Отладка разработанного ПО и оформление протоко-
Проектирование трансляторов
319724
знака
0
таблиц
0
изображений
2 семестр: Отладка разработанного ПО и оформление протоко-
лов работы ЭВМ.
МАТЕМАТИЧЕСКИЙ АППАРАТ - теория формальных языков и грамма-
тик. Подробнее мы ознакомимся с ним на последующих лекциях.
ПРОЦЕСС ТРАНСЛЯЦИИ - выполняемое с сохранением смысла
преобразование входного сообщения с одного языка в выходное сооб-
щение на другом языке.
ТРАНСЛЯТОР - программа, выполняющая процесс трансляции. В
случае выполнения исходной программы без получения текста на вы-
ходном языке, говорят о режиме интерпретации входной программы.
Соответствующая программа, обеспечивающая непосредственную тран-
сляцию входного текста в последовательность команд ЭВМ, называет-
ся интерпретатором.
СТРУКТУРНАЯ СХЕМА ТРАНСЛЯТОРА:
- ЛА (сканер), используемый для разбора лексики исходного
языка (ИЯ). Сканер последовательно просматривает литеры исходной
(транслируемой) программы. Из литер по определенным правилам, за-
данным автоматной грамматикой, сканер строит символы программы
(иначе - лексемы). Состав лексем определяется разработчиком ИЯ и
транслятора с него. Как правило, это числа, идентификаторы, слу-
жебные слова, литералы (цепочки литер, имеющие в программе самос-
тоятельное значение);
- СА, используемый для определения синтаксиса транслируемо-
го текста и управления процессом трансляции. Результат СА - дере-
во вывода;
- семантический анализ, используемый для определения смысла
транслируемого сообщения (либо его фрагмента). Результат семанти-
ческого анализа - хранение информации о транслируемом сообщении в
специальных структурах (таблицах символов, идентификаторах, кон-
стант, и других);
- синтезатор (генератор) текста на промежуточном языке
(польская запись, триады, тетрады, графы, и другие). В Вашем КП в
качестве промежуточного языка я рекомендую использовать язык
программирования Си;
- генератор программы в объектном коде;
- редактирование связей, генерация программы в виде загру-
зочного модуля.
Принципы построения транслятора
Общие сведения
Компилятор должен выполнить анализ исходной программы, а
затем синтез обьектной программы. Исходная программа разлагается
на составные части, затем из них строятся части эквивалентной
обьектной программы. Для этого на этапе анализа компилятор строит
несколько таблиц, которые затем используются как при анализе,так
и при синтезе. Этот процесс представлен на рис.
Процесс преобразования языков программирования включает сле-
дующие этапы:
1) распознавание в исходном тексте программы различных сос-
тавляющих языка;
2) этап синтаксического анализа, на котором распознаются
структуры исходной программы и проверяется их правильность;
3) установление связи между используемыми идентификаторами и
их описанием.
Генерирование обьектного кода
Способ взаимодействия и метод обьединения этих этапов в еди-
ный процесс зависит от числа проходов компилятора.
Все 4-е последовательных процесса: сканирование, анализ,
подготовку к генерации и генерацию команд - можно выполнять пос-
ледовательно или параллельно определенной взаимной синхрониза-
цией. Одним из критериев, определяющих выбор в данном случае, яв-
ляется обьем доступной памяти. Часто выгодно или даже необходимо
иметь несколько проходов.
В однопроходных трансляторах целая последоватеьлность прос-
тых преобразований (этапов) применяется по очереди к каждой не-
большой части исходной программы таким образом, что рабочая прог-
рамма обращается в процессе единственного просмотра исходной
программы. В многопроходном трансляторе последовательности преоб-
разований применяются ко всей программе как к целому.
Имеется много факторов, определяющих выбор числа проходов
при проектировании трансляторов (время компиляции, время разра-
ботки, относительная независимость фаз трансляции, размеры ОП
ЭВМ).
Некоторые языки (Алгол-68, АДА) принципиально требуют для
своей реализации несколько проходов, в частности можно рассмот-
реть двухпроходную схему трансляции. Ее особенности:
1) она может использоваться для языков программирования, в
которых определяющая реализация идентификатора появляется (тек-
стуально) раньше любой прикладной реализации, что имеет место для
большинства языков;
2) при написании транслятора необходимо пректировать проме-
жуточный язык, на котором должен представляться исходный текст
между программными проходами.
Лексический анализ (сканер)
Сканер - самая простая часть компилятора, иногда также назы-
ваемая лексическим анализатором. Сканер просматривает литеры ис-
ходной программы слева направо и строит символы программы - це-
лые числа, идентификаторы, служебные слова, двухлитерные символы,
такие как ** и // и т.д. Символы передаются затем на обработку
фактическому анализатору. На этой стадии может быть исключен ком-
ментарий. Сканер также может заносить идентификаторы в таблицу
символов и выполнять другую простую работу, которая фактически
требует анализа исходной программы. Он может выполнить большую
часть работы по макрогенерации в тех случаях, когда требуется
только текстовая подготовка.
Синтаксический анализ
Анализаторы выполняют работы по расчленению исходной прог-
раммы на составные части, формированию ее внутреннего представле-
ния и занесению информации в таблицу символов и другие таблицы.
При этом также выполняется полный синтаксический и семантический
контроль программы.
Обычный анализатор представляет собой синтаксически управ-
ляющую программу. В действительности стремяться отделить синтак-
сис от семантики настолько, насколько это возможно. Когда синтак-
сический анализатор узнает конструкцию исходного языка, он вызы-
вает соответствующую семантическую программу, которая контроли-
рует данную конструкцию с точки зрения семантики и затем запоми-
нает информацию о ней в таблице символов или во внутреннем пред-
ставлении программы.
Семантический анализ
Семантическая программа осуществляет семантическую обработ-
ку, когда связанное с ней правило вызывает семантическую редукцию.
Мы предполагаем, что всякий раз, когда в сентенциальной фор-
ме основа x найдена и ее можно привести к нетерминалу U, синтак-
сический распознаватель вызывает программу, связанную с правилом
U ::= x. Генерируемая польская цепочка хранится в одномерном мас-
сиве Р. Целая переменная р содержит индекс, указывающий на пер-
вый свободный элемент массива. Каждый элемент массива может со-
держать один символ (идентификатор или оператор). Предположим
также, что вызванная семантическая программа имеет доступ к сим-
волам основы S(1) ... S(i), находящимся в синтаксическом стеке S,
который используется распознавателем.
Рассмотрим программу, связанную с правилом E1 ::= E2 + T.
Если она вызвана, то мы можем считать, что польская запись для Е2
и Т уже получена. При этом массив Р содержит
... <код для Е2> <код для Т>
поскольку Е2 раположено левее Т. Справа от в исходной прог-
рамме находятся только терминалы, т.к. разбор производится слева
направо. Следовательно, все, что требуется от программы, - это
занести знак "+" в польскую цепочку. При этом инфиксная запись Е2
+ Т переводится в суффиксную запись Е2 Т +. Следоватедьно, семан-
тическая программа имеет вид Р(р) := '+'; p := p+1.
Рассмотрим семантическую программу для F ::= I, где I обоз-
начает произвольный идентификатор. В соответствии с правилами
польской записи идентификаторы предшествуют своим операторам; бо-
лее того они встречаются в том же порядке, что и в инфиксной за-
писи. Все, что необходимо сделать, - это занести идентификатор в
массив Р. Поэтому программа имеет следующий вид;
Р(р) = S(i); p := p+1 где S(i) - верхний символ стека.
Т.к. для каждой продукции мы пишем одну семантическую прог-
рамму, то это помогает поделить обработку на мелкие независимые
части, каждую из которых можно запрограммировать отдельно, что
позволяет не думать обо всем сразу.
Небольшие изменения в синтаксисе или семантике требуют лишь
незначительных изменений в соответствующих правилах грамматики
или семантических программах. Различные части анализа отделены
друг от друга, поэтому внесение изменений не представляет особых
затруднений.
СПИСОК ЛИТЕРАТУРЫ
1. Грис Д. Конструирование компиляторов для цифровых вычис-
лительных машин. М., Мир, 1975 г.
2. Ахо А., Ульман Дж. Теория синтаксического анализа, пере-
вода и компиляции. М. Мир 1978 г.
3. Льюис Ф., Розенкранц Д., Стирнз Р. Теоретические основы
проектирования компиляторов. М., Мир, 1979 г.
4. Вирт, Вебер. Теория перевода, компиляции и редактирова-
ния. М., Мир, 1980 г.
5. Виленкин С.Я., Трахтенгерц Э.А. Математическое обеспече-
ние управляющих вычислительных машин. М., Энергия, 1972 г.
6. Фельдман Дж., Грис Д. Системы построения трансляторов.
Сб. Алгоритмы и алгоритмические языки, вып.5, ВЦ АН СССР, 1971 г.
ЛЕКЦИЯ 2
ОПРЕДЕЛЕНИЯ
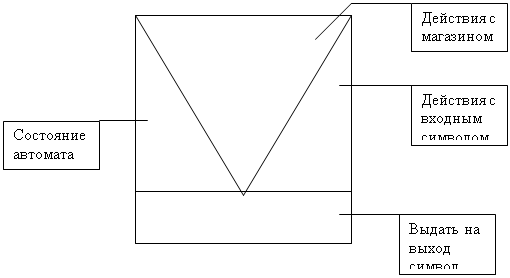
Автомат с конечным числом состояний - это пятерка вида
(K,Vt,M,S,Z), где:
K - алфавит элементов, называемых состояниями;
Vt - входной алфавит (литеры, которые могут встретится в
цепочке или предложении);
M - отображение (или функция) множества К*Vt вo множество K
(если M(Q,T) = R, то это значит, что из состояния Q при входной
литере T происходит переключение в состояние R);
S C К - начальное состояние;
Z - непустое множество заключительных состояний, каждое из
которых принадлежит К.
Автомат - устpойство, пpедназначенное для выполнения целе-
напpавленных действий без непосpедственного участия человека.
Абстpактный автомат - математическая модель автомата, задан-
ная множествами (входных символов, состояний и выходных символов)
и двух двуместных функций (пеpеходов и выходов). Функция пеpехо-
дов отобpажает пеpвые два множества во втоpое, а функция выходов,
соответственно - в третье.
Конечный автомат - абстpактный автомат, все тpи опpеделяю-
щие множества котоpого конечны.
V+ - транзитивное замыкание множества V.
V* - рефлексивно-транзитивное замыкание множества V.
Фоpмальная гpамматика - фоpмальная система пpавил, описываю-
щих в опpеделенном аспекте некотоpый язык G=(Vt,Vn,P,S), где:
Vt - множество терминальных символов;
Vn - множество нетерминальных символов;
P - конечный набор правил подстановки;
S С Vn - начальный символ.
Символы в левой и правой частях правил в совокупности обра-
зуют словарь V, V = Vt U Vn.
Символы грамматики G, встречающиеся в левой части правил,
называются нетерминальными. Множество нетерминалов Vn С V являет-
ся подмножеством словаря, остальная часть множества V образует
множество терминальных симолов Vt С V.
В зависимости от ограничений, накладываемых на грамматичес-
каие правила (продукции), различают 4 основных класса грамматик
(по Хомскому). Их определение содержится ниже.
Правила автоматной гpамматики имеют вид:
U ::= N или U ::= NW, где N C Vt, а U, W C Vn.
Правила контекстно-свободной гpамматики имеют вид:
U ::= u, где U C Vn, u C V.
Правила контекстно-зависимой грамматики имеют вид:
xUy ::= xuy, где U C Vn, x, u, y C V.
Грамматика без ограничений на грамматичекие правила:
u ::= v, где u C V+ и v C V*.
Всякая конечная последовательность символов алфавита А назы-
вается цепочкой.
Непосредственный вывод. Пусть G - грамматика. Говорят, что
цепочка v непосредственно порождает цепочку w, т.е. v -> w, если
для некоторых цепочек x и y можно написать v = xUy, w = xuy, где
U ::= u - правило грамматики G. Также говорят, что w непосред-
ственно выводима из v.
Вывод. Пусть G - грамматика. Цепочка v порождает цепочку w,
т.е. v => w, если существует последовательность непосредственных
выводов v = x1 -> x2 -> x3 -> ... -> xn = w.
Формальный язык L(g) = { x | S=>x, x С Vt+ } Таким образом,
язык - это выводимое из S подмножество множества всех терми-
нальных цепочек, т.е. цепочек в Vt.
Сентенциальная форма. S => x - цепочка символов языка х, по-
рождаемых из аксиомы S.
Предложение: { x | S=>x, x C Vt* } - выводимая из аксиомы S
цепочка терминальных символов, принадлежащая рефлексивно-транзи-
тивному замыканию множества терминальных символов Vt*.
Транслятор - это программа, которая преобразовывает сообще-
ние, написанное на языке L1, в сообщение, написанное на языке L2,
с сохранением смысла.
Формальный язык характеризуется алфавитом, лексикой, семан-
тикой и синтаксисом.
┌──────────── ПРЕДЛОЖЕНИЕ ───────────┐
│ │ │ │
│ │ │ │
ОПРЕДЕЛЕНИЕ ПОДЛЕЖАЩЕЕ СКАЗУЕМОЕ ДОПОЛНЕНИЕ
│ │ │ │
голодный верблюд съел колючку
В самом общем виде в состав транслятора должны входить сле-
дующие блоки:
- Лексический анализ;
- Синтаксический анализ;
- Семантический анализ;
- Синтез программы на промежуточном языке;
- Оптимизация программы;
- Синтез объектной программы.
Лексический анализ реализуется с помощью лексического анали-
затора (сканера). ЛА выделяет лексемы из транслируемого сообще-
ния и заменяет их на символы языка. В процессе анализа могут воз-
никать ошибки.
Лексемы могут быть следующих классов:
- разделители;
- арифметические операции: + - / *;
- ключевые слова: for, begin, end, do, to, step;
- идентификаторы.
Синтаксический анализатор распознает синтаксис языка (струк-
туру).
Семантический разбор - это программа или группа программ,
занимающаяся распознаванием смысла сообщения.
Синтез программы - программа, которая занимается генерацией
программы на промежуточном языке.
Оптимизация программы - синтез программы в виде объектного
кода.
ФОРМАЛЬНОЕ ОПРЕДЕЛЕНИЯ ГРАММАТИКИ:
Грамматика - упорядоченная четверка G = (Vт, Vn, P, S), S C
Vn, множества терминальных Vt и нетерминальных Vn символов, грам-
матических правил P, начальный нетерминальный символ S или аксио-
ма.
Правила P непосредственно определяют процесс вывода. Хом-
ский ввел 4 класса грамматик:
1. Автоматная грамматика: символы, которые встречаются в ле-
вой части правил называются нетерминалами, они образуют множес-
тво нетерминальных символов Vn; символы, которые входят в множес-
тво Vт, называются терминалами. Нетерминалы и терминалы вместе
образуют словарь V.
V = Vn U Vт
U ::= N, U ::= WN
N C Vт, U,W C Vn
На базе автоматной грамматики строятся конечные или беско-
нечные автоматы, использующиеся для сканирования или синтаксичес-
кого анализа.
2. Контекстно-свободная грамматика:
U ::= u ; U C Vn , u C V
│ │
цепочка строка состоит из
исходного термин. и нетерм.
текста символов
(нетерм.)
Строка u сворачивается в U вне зависимости от контекста.
3. Контекстно-зависимые грамматики:
x U y ::= xuy
U C Vn; x,y,u C V
4. Грамматика без ограничения на правила вывода:
V ::= u u C V*, V C V*
Грамматика, которая позволяет разбирать арифметические выра-
жения:
<выражение>::= <терм>│
<выражение>+<терм>│
<выражение>-<терм>
<терм> ::= <множество>│
<терм>*<множество>│
<терм>/<множество>
<множество> ::= (<выражение>)│ i
i - идентификатор
Алфавит языка - это некоторое непустое конечное множество
элементов, называемых символами.
Всякая конечная последовательность символов языка называет-
ся цепочкой.
Пустая цепочка - цепочка, не содержащая ни одного символа.
Ее длина равна 0.
Множества цепочек в алфавите обычно обозначаются заглавными
буквами.
Х = mABCn
│ │
голова хвост
xy - конкатенация цепочек x, y. х - голова, у - хвост цепоч-
ки z=xy.
Произведение АВ двух множеств цепочек А и В:
AB = { xy │ x C A, y C B }
Степень цепочки: x^0 - "", x^N = x^(N-1)*x
V* - рефлексивно-транзитивное замыкание (итерация).
V+ - транзитивное замыкание (усеченная итерация).
Бесконечные множества:
V* = V^0 U V^1 U ... U V^N U ...
Формальное описание строки:
V*={z │ z = "",z = xU}, z,x C V*, U C V - любой символ из V.
Строка x непосредственно порождает y относительно P (x->y),
когда существуют строки u, w, (возможно пустые) такие, что x=uVw,
y=uzw, V ::= z C P.
Строка x порождает y относительно P (x=>y), когда сущес-
твует последовательность строк x0, x1, x2, ... xN, такая, что
x=x0, y=xN, xI-1 -> xI (I=1,2,...,N).
Язык - некоторое множество предложений:
Lg = { x │ x C Vt*, S => x }.
Порождение (либо свертывание) строк Lg можно представить в
виде дерева. Терминальные символы не порождают новых символов,
нетерминальные - порождают. Иначе терминальные символы - это те,
на которых образуются конструкции Lg.
Cентенциальная форма: S => x, х C V+.
Предложение - цепочка терминальных символов, выведенных из
аксиомы: { x │ S => x, x C Vt* }
Пусть w=xuy - сентенциальная форма. Тогда u - фраза для U C
Vn, если S => xUy и U => u. Простая фраза - если U -> u.
Основа - самая левая простая фраза. Существуют леворекурсив-
ные и праворекурсивные грамматики. Различные грамматики могут по-
рождать один и тот же L. Мы можем генерировать синтаксически пра-
вильные сообщения.
<предложение>::=<определение><подлежащее><сказуемое><дополнение>
<определение>::=<голодный>│<большой>
<подлежащее>::=<верблюд>│<слон>│ ...
<сказуемое>::=<съел>│<взял>│ ...
<дополнение>::=<колючку>│<ветку>│ ...
Используя функции порождения строк относительно синтаксиса
этого языка, можно генерировать строки, формально принадлежащие
этому языку, правильные синтаксически, но неверные семантически (
Пример - Глоклая куздра бодланула куздренка).
G1 и G2 эквивалентны, если порождаемые ими языки Lg1 и Lg2
равны. Эквивалентные преобразования грамматик могут быть ис-
пользованы для удобства выбора семантических программ.
Однозначная грамматика - если существует только одно дерево
вывода для каждого предложения Lg.
Разбор или синтаксический анализ сентенциальной формы - это
построение вывода и, возможно, синтаксического дерева для нее.
Существуют методы как нисходящего, так и восходящего разбо-
ра (относительно движения по синтаксическому дереву).
Непосредственный вывод xUy -> xuy называют каноническим, ес-
ли u C Vt*. Вывод w=>v канонический, если все непосредственные
выводы в нем канонические.
Сентенциальная форма, имеющая канонический вывод - канони-
ческая сентенциальная форма.
Свертывание будем называть проходом или анализом. В дальней-
шем будем считать, что в процессе анализа считывание входного
текста происходит слева направо, а свертывание начинается с той
самой левой части строки, которая может быть свернута без допол-
нительного анализа последующего текста. Такое свертывание будем
называть каноническим.
Отношения
->, => - символы отношений между цепочками.
Пара цепочек (c,d) принадлежит отношению R, если выполняет-
ся cRd.
Отношение P включает R, если из (c,d) C R следует (c,d) C Р.
Отношение, обратное R - R^(-1).
Рефлексивное отношение - при справедливости сRc.
Например: i <= i - рефлексивное, а i < i - не рефлексивное
отношение.
Транзитивное отношение R - если выполняется aRb, bRc => aRc.
Произведение R,P: cRPd - если существует е, такое что cRe и ePd.
Итерация R - (обозначается R*): aR*b - когда a=b или aR+b.
Ограничения, накладываемые на грамматику G:
- нет правил вида U ::= U;
- S=>xUy, U=>t, t C Vt* - приведенная грамматика;
Пример. G - язык арифметических выражений.
S ::= E
E ::= T
E ::= E+T
T ::= P
T ::= T*P
P ::= (E)
P ::= I
ЛЕКЦИЯ 3
АНАЛИЗ КОНТЕКСТНО-СВОБОДНЫХ ЯЗЫКОВ
С ПОМОЩЬЮ МАТРИЦ ПРЕДШЕСТВОВАНИЯ
Будем рассматривать каноническое свертывание контекстно-сво-
бодных (КС) языков. Нахождение эффективных методов свертывания -
одна из важнейших задач в теории построения трансляторов. В рас-
сматриваемых алгоритмах анализа входного текста, написанного на
КС-языке, используются отношения предшествования между каждой па-
рой соседних символов строки.
Рассмотрим подробнее отношения предшествования: пусть Si и
Sj - символы языка L (Si,Sj С V). Если в некоторой строке языка
они могут быть записаны рядом (...SiSj...), то между ними могут
существовать только три отношения.
1. В строке ...SiSj... свертываемая часть строки начинается
└──┘
с символа Sj, то есть Sj - самый левый символ свертываемой под-
строки. Если при этом Si не является последним символом другой
строки свертываемой подстроки, то будем говорить, что Si предшес-
твует Sj. Запишем это условие в виде Si < Sj.
Похожие работы
... работы. В ходе работы над дипломным проектом разработан транслятор. Проблема создания такого транслятора является очень актуальной, т.к. многим пользователям САПР необходимо доступ к технической документацию, которую удобнее хранить на удаленных серверах в формате HTML. Поэтому степень положительного эффекта от выполнения дипломного проекта научно-исследовательского характера 1=6.5. В ...

... направления, активно развиваемого сейчас в разных коллективах и странах. Отталкиваясь от трансформационной модели смешанных вычислений и от своих работ в области трансляции и оптимизации программ, Ершов определяет концепцию трансформационной машины. Трансформационная машина есть абстрактное вычислительное устройство, выполняющее программы в некотором "сверхязыке", действиями которого являются ...

... 166, 16 Mb RAM, Windows 95 Вывод В ходе разработки курсового проекта я ближе ознакомился с теорией МП- трансляторов, научился писать программы - конструкторы для построения МП – транслятора по его параметрам с последующей проверкой задаваемых цепочек, закрепил знания по системному программированию. Разрабатывая программу, я научился применять знания дискретной математике, что облегчает ...
... позволяет связывать твёрдотельные модели, сборки или чертежи, созданные с помощью SolidWorks 97, с файлами других приложений, что значительно расширяет возможности автоматизации процесса проектирования. С помощью технологии OLE можно использовать информацию, полученную в других приложениях Windows, для управления моделями и чертежами SolidWorks. Например, размеры модели могут быть рассчитаны в ...
0 комментариев