Семестр: Отладка разработанного ПО и оформление протоко-
В строке ...SiSj... символы Si и Sj входят в одну и ту
В множество L(U) самых левых символов нетерминального
Пусть между некоторыми двумя символами Si и Sj сущес-
I i 1
Не предусмотрен выход при выполнении условия R > R , так как
Потом повторяется п. 5
Если выполнение шага 4 пpиведет к тому, что значения всех
Перевод инфиксной записи в польскую. Всякий раз, когда в
Когда редуцируется основа XY..Z, тетрады для всех нетер-
Опреанды и операторы
Если сканируемый символ - унарный оператор, то он приме-
А * В + С * D => *, A, B, T1 ┐ тетрады располагаются в
Устраняет недостатки программы,вызванные небрежностью или
Проверяется
непртиворечивость типов получателя и ис-
ДИСПЛЕЙ
Выделение памяти под рамку в процессе трансляции
ОРГАНИЗАЦИЯ ПАМЯТИ ВО ВРЕМЯ ТРАНСЛЯЦИИ
Алгоритм Биледи
Возможные параметры описания переменных и процедур
Навигация
Пусть между некоторыми двумя символами Si и Sj сущес-
Проектирование трансляторов
319724
знака
0
таблиц
0
изображений
1. Пусть между некоторыми двумя символами Si и Sj сущес-
твуют два отношения предшествования Si = Sj и Si < Sj.
Значит, существуют правила
Un ::= XnSiSjYn (n = 1,2,...,N); (1)
Um ::= ZmSiFkDm (m = 1,2,...,M; k = 1,2,...,K);
Fk -> SjQk; (2)
Введем новые нетерминальные символы Pn и синтаксические
правила Pn ::= SjYn (n = 1,2,...,N), заменяя все правила (1)
правилами Un ::= XnSiPn, при этом если исходная грамматика со-
держит правила вида Qn ::= SjYn, то заменяем их правилами Qn ::=
Pn.
1а. Если применение правила 1 не устраняет неоднозначности,
то вводятся нетерминальные символы Pn и Lm и синтаксические пра-
вила Pn ::= XnSi и Lm ::= ZmSi и все правила (1) заменяются на
Un ::= PnSjYn, а все правила (2) на правила Um ::= LmFkDm.
Если исходная грамматика содержит правила вида Qn ::= XnSi и
Tm ::= ZmSi, то заменяя их на правила Qn::=Pn и Tm::=Lm соответ-
ственно. Правила Pn и Lm надо выбирать так, чтобы Pn не совпада-
ло с Lm, т.е. чтобы ни для каких n и m Xn не совпадало с Zm.
Алгоритмы 1 и 1а устраняют отношения предшествования =. Это
видно из определений 1а-3а.
2. Пусть между некоторыми двумя символами Si и Sj сущес-
твуют два отношения предшествования Si = Sj и Si > Sj.
Значит, существуют правила
Un ::= XnSiSjYn (n = 1,2,...,N); (3)
Um ::= ZmFkSjDm или Um ::= ZmFkRlDm (4)
(m = 1,2,...,M; k = 1,2,...,K; l = 1,2,...,L);
Fk -> QkSi Rl -> SjTl.
Введем новые нетерминальные символы Pn и синтаксические пра-
вила Pn ::= XnSi (n = 1,2,...,N). Заменяем правила (3) правилами
Un ::= PnSjYn, устраняя тем самым отношения предшествования =.
Если исходная грамматика содержит правила вида Qn ::= XnSi, то
заменяем их правилами Qn ::= Pn.
3. Пусть между некоторыми двумя символами Si и Sj сущес-
твуют два отношения предшествования Si < Sj и Si > Sj, т. е. су-
ществуют правила
Un ::= XnSiFkYn (n = 1,2,...,N); (5)
Um ::= ZmRlSjDm или Um ::= ZmRlTpDm (6)
(m = 1,2,...,M; k = 1,2,...,K; l = 1,2,...,L;
p = 1,2,...,P);
Fk -> SjQk Rl -> HlSi, Tp -> SjWp.
Введем новые нетерминальные символы Pn и синтаксические пра-
вила Pn ::= XnSi (n = 1,2,...,N). Заменяем правила (5) правилами
Un ::= PnFkYn, сведя их к правилам (6) и устранив тем самым отно-
шения предшествования типа <. Если исходная грамматика содержит
правила вида Qn ::= XnSi, то заменяем их правилами Qn ::= Pn.
Справедлива теорема, согласно которой алгоритмы 1-3 измене-
ния синтаксиса языка программирования не изменяют правила на-
писания и семантику программ на данном языке.
Для тех случаев, когда КС-грамматику надо преобразовывать в
грамматику типа 2 только с одним дополнительным ограничением -
однозначность отношений предшествования (одинаковые правые части
допускаются), Ленаром и Лимом предложен следующий универсальный
алгоритм.
1. Составляются таблицы L(N) самых левых и R(N) - самых пра-
вых сиволов нетерминального символа N. Символ N C L(N) назовем
леворекурсивным, ссимвол N C R(N) - праворекурсивным.
2. Составляется матрица предшествования и определяются все
нарушения единственности отношений предшествования, и если их
нет, то производится остановка. Если они есть, то осуществляется
переход к 3.
3. К каждому праворекурсивному символу применяется процеду-
ра ограниченного правого расширения, которая заключается в том,
что каждый праворекурсивный символ N заменяется символом N1 и
вводится новое грамматическое правило N1::=N. Символ N не заме-
няется на символ N1, если в данном грамматическом правиле он яв-
ляется самым правым символом.
4. К каждому леворекурсивному символу применяется процедура
ограниченного левого расширения, которая заключается в том, что
каждый леворекурсивный символ N заменяется символом N2 и вводит-
ся новое грамматическое правило N2::=N. Символ N не заменяется
символом N2, если в данном грамматическом правиле он является са-
мым левым символом.
5. Если выполнен п. 3 или 4, то осуществляется переход к
п.1. Если нет, то осуществляется переход к п.6.
6. По матрице предшествования находятся пары символов X,Y и
P,Q такие, что X = Y и P = Q.
а. Если X C R(P) и выполняется одно из следующих условий: Q
и Y являются одними и теми же символами или Q C L(Y) или Y C L(Q)
или существует символ D такой, что D C (L(Q) /\ L(Y)), то к сим-
волу X применяется процедура ограниченного правого расширения.
б. Если Y C L(Q) а P и X являются одними и теми же символа-
ми, то к символу Y применяется процедура ограниченного левого
расширения и осуществляется переход к п.1.
ЛЕКЦИЯ 5
АНАЛИЗ КОНТЕКСТНО-ЗАВИСИМЫХ ЯЗЫКОВ
С ПОМОЩЬЮ МАТРИЦ ПРЕДШЕСТВОВАНИЯ
Наиболее распространенные грамматики, описывающие языки
программирования, - это КС-грамматики (грамматики типа 2 в клас-
сификации Хомского). Однако описание языков программирования
грамматиками типа 1, т.е. контекстно-зависимыми (КЗ) грамматика-
ми во многих случаях может облегчить как сам процесс описанияопи-
сания языка, так и построение транслятора.
Рассмотрим алгоритм анализа программы, если алгоритмический
язык описан неукорачивающей грамматикой. Класс неукорачивающих
грамматик совпадает с классом КЗ-грамматик (грамматики типа 1 по
Хомскому).
Грамматика G является неукорачивающей, если для каждого
правила x ::= y С Ф выполняется условие │ x │<=│ y │, где │ x │
i i i i i
и │ y │ - число символов, входящих в строки x и y соответ-
i i i
ственно.
Множества самых левых Л(В) и самых правых П(В) символов сим-
вола В:
L(В) = { U/ ] (Be ::= Ux) С Ф \/ ] (Be ::= B1x) С Ф /\
/\ U С L(В1) };
R(В) = { U/ ] (eB ::= xU) С Ф \/ ] (eB ::= xB1) С Ф /\
/\ U С R(В1) };
где e, x - строки, возможно, пустые; В, В1, U С Vt U Vn.
Из этих определений следует, что терминальные символы также
могут обладать непустым множеством самых левых (правых) символов
при условии, что они использовались как начальные (конечные) сим-
волы в строках грамматических правил (x i ::= y i) С Ф.
Из определения L(В) непосредственно следует, что если a ->
b, т. е. a = f1 -> f2 -> ... -> fk = b (k>1) и a = Bx, то на-
чальные символы строк f i = Ux i (1<i<=k), в которых начальный
символ U участвовал в строках y правил вывода, принадлежат мно-
жеству L(В).
Аналогично из определения R(В) непосредственно следует, что
если a -> b, a = xB и, кроме того, a = f1 -> f2 -> ... -> fk =
= b (k>1), то конечные символы строк f i = x i U (1<i<=k), в кото-
рых конечный символ U участвовал в правилах вывода, принадлежат
множеству R(В).
Определим отношения предшествования для неукорачивающих
грамматик:
В = В <--> ] ф (ф: g ::= xB B y) С Ф;
i j i j
B < B <--> ] ф (ф: g ::= xB Ny) С Ф /\ B С Л(N);
i j i j
B > B <--> ] ф (ф: g ::= xNB y) С Ф /\ B С П(N) \/
i j j i
\/ ] ф (ф: g ::= xNN y) С Ф /\ B С П(N) /\ B С Л(N );
Похожие работы
... работы. В ходе работы над дипломным проектом разработан транслятор. Проблема создания такого транслятора является очень актуальной, т.к. многим пользователям САПР необходимо доступ к технической документацию, которую удобнее хранить на удаленных серверах в формате HTML. Поэтому степень положительного эффекта от выполнения дипломного проекта научно-исследовательского характера 1=6.5. В ...

... направления, активно развиваемого сейчас в разных коллективах и странах. Отталкиваясь от трансформационной модели смешанных вычислений и от своих работ в области трансляции и оптимизации программ, Ершов определяет концепцию трансформационной машины. Трансформационная машина есть абстрактное вычислительное устройство, выполняющее программы в некотором "сверхязыке", действиями которого являются ...
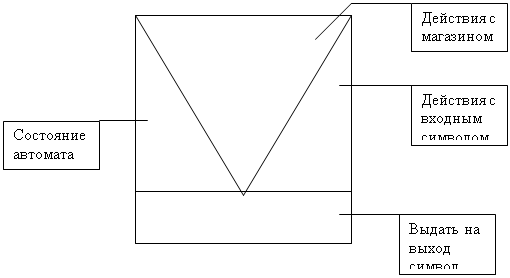
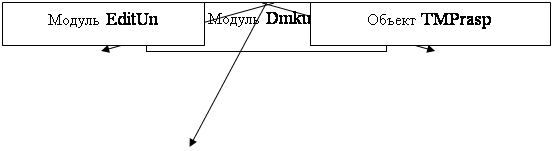
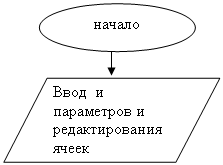
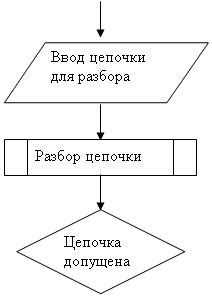

... 166, 16 Mb RAM, Windows 95 Вывод В ходе разработки курсового проекта я ближе ознакомился с теорией МП- трансляторов, научился писать программы - конструкторы для построения МП – транслятора по его параметрам с последующей проверкой задаваемых цепочек, закрепил знания по системному программированию. Разрабатывая программу, я научился применять знания дискретной математике, что облегчает ...
... позволяет связывать твёрдотельные модели, сборки или чертежи, созданные с помощью SolidWorks 97, с файлами других приложений, что значительно расширяет возможности автоматизации процесса проектирования. С помощью технологии OLE можно использовать информацию, полученную в других приложениях Windows, для управления моделями и чертежами SolidWorks. Например, размеры модели могут быть рассчитаны в ...
0 комментариев