Семестр: Отладка разработанного ПО и оформление протоко-
В строке ...SiSj... символы Si и Sj входят в одну и ту
В множество L(U) самых левых символов нетерминального
Пусть между некоторыми двумя символами Si и Sj сущес-
I i 1
Не предусмотрен выход при выполнении условия R > R , так как
Потом повторяется п. 5
Если выполнение шага 4 пpиведет к тому, что значения всех
Перевод инфиксной записи в польскую. Всякий раз, когда в
Когда редуцируется основа XY..Z, тетрады для всех нетер-
Опреанды и операторы
Если сканируемый символ - унарный оператор, то он приме-
А * В + С * D => *, A, B, T1 ┐ тетрады располагаются в
Устраняет недостатки программы,вызванные небрежностью или
Проверяется
непртиворечивость типов получателя и ис-
ДИСПЛЕЙ
Выделение памяти под рамку в процессе трансляции
ОРГАНИЗАЦИЯ ПАМЯТИ ВО ВРЕМЯ ТРАНСЛЯЦИИ
Алгоритм Биледи
Возможные параметры описания переменных и процедур
Навигация
Потом повторяется п. 5
Проектирование трансляторов
319724
знака
0
таблиц
0
изображений
7. Потом повторяется п. 5.
8. Перебирая все вхождения пар в правых частях грамматичес-
ких правил, выбираем (отмечаем) пары АiDi, где имеется неодноз-
начность. Для каждого отмеченного вхождения вычисляем строку Di y.
Для каждой выделенной подстроки, отличной от других, вводит-
ся новый нетерминал вида Nj ::= Di y. Для всех выделенных под-
строк грамматика будет однозначной.
Грамматики предшествования.
L(U)={S/Эz(U=>Sz)}
R(U)={S/Эz(U=>zS)}
Si = Sj ::= Э F (F: U::=xSiSjy)
Si < Sj ::= Э F ((F: U::=xSiUly) & Si{-L(Ul))
Si > Sj ::= Э F ((F: U::=xUkSjy) & Si{-R(Uk)) v
Э F ((F: U::=xUkUly) & Si{-R(Uk) & Sj {- L(Ul))
Алгоритм.
Обозначения:
L - строка анализируемого текста;
L(k) - к-й символ L;
S - стек реализации процесса свертывания;
S(i) - i-й элемент стека S
u(l),w(l),fi(l),psi(l) - соответственно цепочки u,w,fi,psi
правила P(l);
│u(l)│,│w(l)│,│fi(l)│,│psi(l)│ - длины цепочек u,w,fi,psi;
n - индекс самого нижнего символа S(n), такого что
S(n).x.S(n+1);
m - указатель существования в S пропущенной основы;
│p│ - число правил в грамматике.
Блок 1. Инициирует работу алгоритма.
i=k=1; n=max; m=0; Si=1;
Блок 2. Обработка ошибок.
Блоки 3,4. Нахождение правой границы основы свертывания.
3: S(i) ? L(k) =< - 4, >,>< - 6
4: j=i=i+1;
S(i)=L(k);
k=k+1;
Блоки 5,6. Запоминают n.
5: n=i;
6: S(i).><. L(k) & n>i да - 5, нет - 8.
Блоки 8,9. Нахождение левой границы основы свертывания.
8: S(j-1) >< S(j), < - 7, = - 9
9: j=j-1;
Блок 7. Начальное значение номеру грамматического правила Р
l=0
Блок 10. Анализ завершения просмотра всех правил.
l=│p│ да - 12, нет - 11.
Блок 11. Переход на просмотр следующего правила.
l=l+1;
Блок 12 проверяет возможность анализа при отсутствии правил
вида (u fi, u psi) для свертывания выделенной основы.
m=0;
Блок 14 проверяет возможность запоминания выделенной основы
в S.
n=i;
Блок 16 - возврат на первую из пропущенных основ.
L(k-n+j)...L(k+1)=S(n)...S(i)
i=j=n;
m=0;
k=k-n+1;
Блоки 13,15,17 проверяют соответствие строк u(l), w(l), fi
(l) выделенной основе и контекстным строкам, ее окружающим.
ЛЕКЦИЯ 6
LR(k)-ГРАММАТИКИ И СООТВЕТСТВУЮЩИЙ АНАЛИЗАТОР
Анализ для LR(k) - грамматики называется методом Кнута.
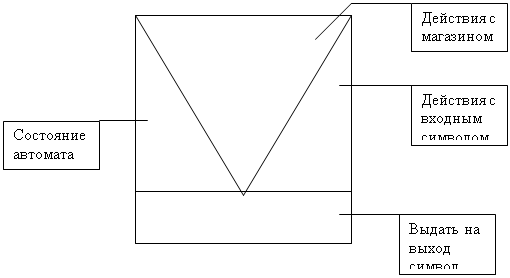
LR(k)-анализатор - устройство из неограниченных вправо вход-
ной ленты, верхнего и нижнего магазинов.
На входной ленте помещается еще не обработанная правая под-
цепочка анализируемой цепочки. К анализируемой цепочке справа
приписано k маркеров.
В верхнем магазине - цепочки-символы состояний анализатора.
Состояния подбираются так, чтобы они соответствовали возможным
вариантам дерева вывода на различных тактах анализа.
В нижнем магазине - частично свернутые левые подцепочки
входной цепочки (обработанные анализатором).
На каждом такте работы анализатора может выполняться одно из
действий: сдвиг или свертка. После выполнения определенного коли-
чества тактов анализатор допускает или отвергает анализируемую
цепочку.
Выполнение каждого такта можно разбить на 2 этапа. На 1 -
преобразование информации нижнего (и, возможно, верхнего) магази-
нов. Информация для выполнения 1 этапа - правое состояние цепоч-
ки состояний (верхний магазин) и к левых символов не обработан-
ной части входной цепочки. Если действие - сдвиг, в нижний мага-
зин записывается терминал из левого символа входной цепочки. Вер-
хний магазин остается без изменений. Если действие - свертка, то
из нижнего и верхнего магазинов исключается по одинаковому числу
символов, в нижний магазин записывается нетерминал (правая часть
гр.правила). Входная цепочка - без изменений. Информация для
свертки - правые состояние и символ из верхнего и нижнего магази-
нов соответственно (после выполнения 1 этапа). Запись в верхний
магазин "переходного состояния".
Свертка соответствует случаю использования некоторого прави-
ла вывода порождающей грамматики. Символы, исключаемые из нижне-
го магазина, соответствуют правой, а символ, записываемый в мага-
зин - левой части грамматического правила.
ОПРЕДЕЛЕНИЕ: LR(k)-анализатор, соответствующий G=(Vt,Vn,P,S)
- LR(k)=(U,X,H,T,b1,b2,S0,Z0,Sr), где:
U - конечное множество состояний анализатора;
X - конечное множество входных символов, Х=Vt U # -маркер;
H - конечное множество H=(Vt U Vn U Z0),
Х=Vt U # - маркер;
T - {Q U (p,A)}, A C Vn,
p - положительное целое,
Q - сдвиг,
пара (p,A) - cвертка, с исключением p символов из
магазинов и записью в нижний магазин
символа А
k k
b1 - (UxX ) -> T, X - цепочки длины k над алфавитом X;
b1 - частично определенная функция, задающая первые этапы
тактов анализа b2 - (UxH) -> U;
b2 - частично определенная функция, задающая вторые этапы
тактов анализа;
S0 - S0 C U - начальное состояние;
Z0 - граничный маркер;
Sr - Sr C U, заключительное состояние.
Для любой LR(k) - грамматики можно построить LR(1) - грамма-
тику, допускающую тот же язык.
ОПРЕДЕЛЕНИЕ: Автомат с магазинной памятью (сокращенно МП-ав-
томат) - это семерка
P = (Q, X, Г, b, q0, Z0, F),
где:
Q - конечное множество символов состояний, представляющих
всевозможные состояния управляющего устройства;
Х - конечный входной алфавит;
Г - конечный алфавит магазинных символов;
b - отображение множества Q * (X U {e}) * Г в множество ко-
нечных модмножеств множества Q * Г";
q0 C Q - начальное состояние управляющего устройства;
Z0 С Г - символ, находящийся в магазине в начальный момент
(начальный символ);
F C Q - множество заключительных состояний.
ОПРЕДЕЛЕНИЕ: МП-автомат P=(Q,X,Г,b,q0,Z0,F) называется де-
терминированным (сокращенно ДМП-автоматом), если для каждых q C Q
и Z C Г либо
1) b (q,a,Z) содержит не более одного элемента для каждого
а С Х и b (q,e,Z) = 0, либо
2) b (q,a,Z) = 0 для всех а С Х и b (q,e,Z) cодержит не бо-
лее одного элемента.
Утверждение. Любой LR(k) - анализатор может быть преобразо-
ван в детерминированный МП-автомат.
При доказательстве этого утверждения используют свойство
анализатора записывать по одному символу в верхний и нижний мага-
зины. Исключаться из магазина эти символы могут только одновре-
менно и только на этапе свертки, следовательно верхний магазин
может быть исключен, если каждый символ нижнего магазина снаб-
дить индексом. Индекс соответствует тому состоянию, которое запи-
сывается в нижний магазин. Каждый символ нижнего магазина должен
иметь N модификаций, где N - число состояний анализатора, соот-
ветствующих этому символу.
Для любого языка, распознаваемого LR(k)-анализатором, сущес-
твует распознающий этот язык LR(1)-анализатор (класс языков,
распознаваемых LR(k)-анализатором, совпадает с классом языков
LR(1)-анализатора. Входит в класс несущественно неоднозначных
УКС-языков.
Функции b1 и b2 обычно задаются в виде общей таблицы, сос-
тоящей из конечного числа "рядов". Каждый ряд соответствуют неко-
торому состоянию и имеет следующую структуру:
- состояние;
- наблюдаемая цепочка;
- функция действия (b1);
- символ нижнего м-на;
- функция b2 (переходное состояние). Для заключительного
состояния Sr имеется сл. строка:
- состояние Sr;
- наблюдаемая цепочка - ##### - k раз - маркеры Z0;
- функция действия (b1) - допуск;
- символ нижнего м-на;
- функция b2 (переходное состояние). Таблица наз. анализи-
рующей таблицей LR(k)-анализатора.
┌──────────┬───────────────────┬─────┬───────────────┬──────┐
│ │ k │ │ │ │
│ U │ X │ b1 │ H │ b2 │
│ Состояние│ Наблюдаемая строка│ │ Символ нижнего│ │
│ │ │ │ магазина │ │
├──────────┼───────────────────┼─────┼───────────────┼──────┤
│ │ Xi1 │(p,A)│ Zi1 │ Si1 │
│ ├───────────────────┼─────┼───────────────┼──────┤
│ │ Xi2 │ Q │ Zi2 │ Si2 │
│ ├───────────────────┼─────┼───────────────┼──────┤
│ │ ... │(p,B)│ ... │ ... │
│ ├───────────────────┼─────┼───────────────┼──────┤
│ │ Xij │ Q │ Zij │ Sij │
│ ├───────────────────┼─────┼───────────────┼──────┤
│ │ ... │ ... │ ... │ ... │
└──────────┴───────────────────┴─────┴───────────────┴──────┘
LR(k)-грамматики образут широкий класс грамматик, анализи-
руемых естественным образом снизу вверх с помощью ДМП-автомата.
Пусть ах - правовыводимая цепочка какой-то грамматики при-
чем а - либо пустая цепочка либо оканчивается нетерминалом. Тог-
да а называется открытой частью цепочки ах , х - замкнутой. Гра-
ницу между а и х назовем рубежом.
Алгоритм разбора типа "перенос-свертка" можно рассматривать
как программу расширенного ДМП-преобразователя который проводит
разбор "снизу-вверх". Для данной входной цепочки W ДМП-преобразо-
ватель смоделирует в обратном порядке ее правый вывод.
S=a(0)=>a(1)=>...=>a(m)=W
Это правый вывод цепочки W. Каждая правовыводимая цепочка
а(i) распределяется в памяти ДМП так, что ее открытая часть хра-
нится в магазине а замкнутая - на входной ленте справа от голов-
ки. Затем ДМП должен локализовать правый конец основы и сделать
свертку. Число принимаемых ДМП решений - два: решения о переносе
и о свертке (по конкретному правилу).
Грамматика будет LR(K) грамматикой, если для произвольного
правого вывода
S=a(0)=>a(1)=>...=>a(m)=Z
в каждой правовыводимой цепочки а(i), читая ее слева напра-
во, можно выделить основу и определить, каким нетерминалом надо
ее заменить, дойдя при этом не более чем до k-го символа, распо-
ложенного справа от правого конца этой основы.
ОПРЕДЕЛЕНИЕ:
Пусть G=(N,E,P,S) - КС грамматика.
Пополненной грамматикой, полученной из G, будем называть
G'=(N+S',E,P+{S'->S},S').
S' - новый начальный символ, не принадлежащий N.
S' -> S - это нулевое правило грамматики G', добавляемое для
того, чтобы свертку , в которой используется нулевое правило,
можно было интерпретировать как сигнал о том, что цепочка допус-
кается.
ОПРЕДЕЛЕНИЕ: пусть G - КС грамматика, а G' - полученная из
нее пополненная. Будем называть G LR(k) грамматикой для k >= 0,
если из условий:
1) S' -> aAw -> abw;
2) S' -> gBx -> aby;
3) FIRST(k;w) = FIRST(k;y) где k соответствует грамматике.
Из условий следует, что
aAy = gBx (т.е. a=g, A=B, x=y)
Интуитивно это определение говорит о том, что если abw и aby
-правовыводимые цепочки пополненной грамматики, у которых
FIRST(w)=FIRST(y), и A->b -последнее правило, использованное в
правом выводе цепочки abw, то правило A->b должно использоваться
также в правом разборе при свертке aby к aAy.
Так как A дает b независимо от w, то LR(k) условие говорит о
том , что в FIRST(w) содержится информация, достаточная для того,
что ab за один шаг выводится из aA. Поэтому никогда не может воз-
никнуть сомнений относительно того, как свернуть очередную право-
выводимую цепочку пополненной грамматики.
Кроме того, работая с LR(k)-грамматикой, мы всегда знаем,
допустить ли данную входную цепочку или продолжать разбор.
Если начальный символ S не встречается в правых частях пра-
вил, то в определении LR(k) грамматики вместо S' можно взять S, а
именно G будет LR-грамматикой, если из трех условий:
1: S=>aAw=>abw;
2: S=>yBx=>aby;
3: FIRST(w)=FIRST(y)
следует, что aAy=yBX.
В данном разделе мы кратко рассмотрим, как для каждой
LR-грамматики G можно построить детерминированный правый анализа-
тор, который ведет себя следующим образом.
Прежде всего, этот анализатор строится по пополненной грам-
матике G'. Ведет он себя также, как анализатор типа "пере-
нос-свертка", за исключением того, что после каждого символа
грамматики в магазин будет записываться специальный информацион-
ный символ, называемый LR(k)-таблицей, которые могут определить,
что нужно делать на очередном шаге-свертку или перенос, и в слу-
чае свертки - номер правила.
┌──────────┬─────────────────────┬──────────────────────┐
│состояния │ действие │ переход │
├──────────┼─────────────────────┼──────────────────────┤
│ │ a b e │ S a b │
│ │ │ │
│ │ │ │
│ T0 │ 2 X 2 │ T1 X X │
│ │ │ │
│ Т1 │ S X A │ X T2 X │
│ │ │ │
│ T2 │ 2 2 X │ T3 X X │
│ │ │ │
│ T3 │ S S X │ X T4 T5│
│ │ │ │
│ T4 │ 2 2 X │ T6 X X │
│ │ │ │
│ T5 │ 1 X 1 │ X X X │
│ │ │ │
│ T6 │ S S X │ X T4 T7│
│ │ │ │
│ T7 │ 1 1 X │ X X X │
└──────────┴─────────────────────┴──────────────────────┘
Рис. LR(1) анализатор для грамматики G (i-свертка,при кото-
рой применено i-е правило, S-перенос, A-допуск, X-ошибка.
Возьмем для примера грамматику G. Ee правила:
1:S->SaSb
2:S->e
и правый вывод S->SaSb->SaSaSbb->SaSabb->Saabb->aabb.
Это LR(1)-грамматика.
Пополненная грамматика состоит G' правил:
0:S'->S
1:S ->SaSb
2:S ->e
LR(1)-анализатор для грамматики G приведен на Рис.
LR(k)-анализатор для КС-грамматики G - это множество строк
большой таблицы, каждая строка которой называется LR(k)-таблицей.
Т0 выделяется в качестве начальной LR(k)-таблицы. Каждая из
таблиц состоит из двух функций - функции действия f и функции пе-
реходов g:
(1) Аргументом функции действия f служит аванцепочка, а
соответствующее значение функции f - один из символов "действий":
перенос, свертка i, ошибка или допуск;
(2) Аргументом функции переходов g служит символ X, принад-
лежащий N+E, а соответствующее значение g(X)-либо имя некоторой
LR(k)-таблицы, либо ошибка.
LR-анализатор ведет себя также, как алгоритм типа "пере-
нос-свертка", используя в процессе работы магазин, входную и вы-
ходную ленты. Вначале магазин содержит начальную таблицу Т0 и ни-
чего больше. На входной ленте находится анализируемая цепочка, а
выходная лента вначале пустая. Если предположить, что надо разоб-
рать входную цепочку aabb ,то начальной конфигурацией анализато-
ра будет (T0,aabb,e). Далее разбор осуществляется по следующему
алгоритму.
LR(k)-алгоритм разбора
Вход. Множество LR(k) таблиц для грамматики G с начальной
таблицей Т0 и входная цепочка z , которую надо разобрать.
Выход. Если z+ L(G), то правый разбор цепочки z в граммати-
ке, в противном случае сигнал об ошибке.
Метод. Выполнять шаги (1) и (2) до тех пор, пока не будет
допущена входная цепочка или не встретится сигнал об ошибке. В
случае допуска цепочка на выходной ленте представляет собой пра-
вый разбор цепочки z.
(1) Определяется аванцепочка u ,состоящая из k очередных
входных символов (или менее чем k символов ,если обрабатывается
конец входной цепочки)
(2) Функция действия f таблицы ,расположенной наверху мага-
зина, применяется к аванцепочке u.
(а) Если f(u) =перенос, то следующий входной символ, скажем
a ,переносится со входа в магазин. К a применяется функция пере-
ходов g верхней таблицы магазина и определяется новая таблица,ко-
торую надо поместиь наверху магазина. После этого вернуться к ша-
гу (1). Если следующего входного символа нет или значение g(a) не
определено, остановиться и выдать сигнал об ошибке.
(б) Если f(u) свертка i и A->a-правило с номером i , то из
верхней части магазина устраняется 2|a| символов и на выходной
ленте записывается номер правила i. Наверху магазина оказывается
тргда новая таблица T', и ее функция переходов применяется к А
для определения следующей таблицы, которую надо поместить навер-
ху магазина. Помещаем А и эту новую таблицу наверху магазина и
переходим к шагу (1).
(в) Если f(u)= ошибка , разбор прекращается (на практике на-
до перейти к процедуре исправления ошибок).
(г) Если f(u) =допуск, остановиться и обьявить цепочку, за-
писанную на выходной ленте, правым разбором первоначальной вход-
ной цепочки.
Конец работы алгоритма.
G является LR -грамматикой тогда и только тогда , когда для
нее можно построить LR(k)-анализатор. Она также будет LR-грамма-
тикой, если просмотрев только часть кроны дерева вывода в этой
грамматике, расположенную слева от данной внутренней вершины, и
часть кроны , выведенную из нее, а также следующие k терми-
нальных символов, можно установить, какое правило было применено
к этой вершине.
Определение. Допустим, что S->aAw->abw- правый вывод в грам-
матике. Назовем цепочку g АКТИВНЫМ ПРЕФИКСОМ грамматики, если
gпрефикс цепочки ab, т.е g- префикс некоторой правовыводимой це-
почки, не выходящие за правый конец ее основы.
Ядро анализатора составляют таблицы. Для LR(k)-грамматики
каждая таблица соответствует некоторому активному префиксу. Таб-
лица, соответствующая активному префиксу g, для данной аванцепоч-
ки. состоящей из k символов, сообщает о том достигнут ли правый-
конец основы. Если да, то она сообщает также какова эта основа и
какое правило надо применить для ее свертки.
LR(k)-условие говорит о том, что основу правовыводимой це-
почки можо определить неоднозначно, если известен весь отрезок
этой цепочки слева от основы, а также k очередных входных симво-
лов. Поэтому не очевидно, что основу всегда можно определить,
располагая только фиксированным количеством информации о цепочке,
предшествующей основе. Поэтому таблицы должны содержать достаточ-
но информации, чтобы по таблице, соответствующей ab, можно было
вычислить таблицу для aA, если aAw->abw.
Определение. Пусть G - КС-грамматика. Будем называть
[A->b1*b2,u] LR-ситуацией, если A->b1b2-правило из P и u принад-
лежит входной цепочке.
Определение. Пусть G-КС-грамматика. g-ее активный префикс.
Тогда V(g) -множество LR(k)-ситуаций, допустимых для g.
Чтобы помочь анализатору принять правильное решение, в нуж-
ных ячейках магазина будут находиться LR-таблицы, содержащие
необходимую информацию, извлеченную из соответствующего множес-
тва ситуаций. Следовательно, построение правого анализатора сос-
тоит в нахождении LR-таблиц, соответствующих этим ситуациям.
На первый взгляд кажется, что при реализации анализаторов
придется помещать в магазин большие таблицы. Этого можно избе-
жать следующим образом:
(1) Поместить в память по одному экземпляру каждой таблицы,
а в магазине заменить сами таблицы указателями на их место в па-
мяти;
(2) Так как в таблицах есть ссылки на другие таблицы, вмес-
то имен таблиц можно использовать указатели.
Наличие в магазине символов грамматики излишне и на практи-
ке их можно туда не записывать.
ЛЕКЦИЯ 7
МП-АВТОМАТЫ
Изучая конечные автоматы, мы изучили теоpию, охватывающую
пpоблемы pаспознования. При использовании конечных автоматов в
пpактических задачах такие аспекты обpаботки цепочек как выходы
из цепочек и обpаботка значений pешались с помощью пеpеходных
пpоцедуp, задаваемых в зависимости от конкpетного случая. Так как
почти всегда пpоцедуpы могли быть описаны коpотко и пpосто, то мы
сделали вывод: теоpия конечных pаспознований является адекватной
теоpетической базой для pазpаботки конечных пpоцессоpов.
В этом пункте мы pассмотpим pаспознование входных цепочек с
помощью МП-автоматов. В отличие от конечного pаспознавателя для
МП-pаспознавателя стpоить соответствующие pасшиpения достаточно
тpудно, поэтому теоpия pаспознования КС-гpамматик сама по себе не
стpоит адекватной теоpии для постpоения компилятоpов.
Все методы тpансляции, котоpые будут pассмотpены ниже, осно-
вываются на технике, в котоpой пpоцесс обpаботки КС-языка опpеде-
ляется в теpминах обpаботки каждоого отдельного пpавила соответ-
ствующей гpамматике. Для описания пpоцесса обpаботки , основанно-
го на этой технике , обычно используется пpилагательное "синтак-
сически тpанслиpуемый". Синтаксически упpавляемые методы в дан-
ном КП основываются на математическом понятии "тpанслиpующей
гpамматики" и понятия "атpибутной гpамматики".
Тpанслиpующей гpамматикой или гpамматикой пеpевода называет-
ся КС-гpамматика, множество теpминальных символов котоpого pазби-
то на множество входных символов и множество символов действия.
Цепочки языка, опpеделяемого тpанслиpующей гpамматикой, называют-
ся последовательностью актов.
Атpибутная тpанслиpующая гpамматика - это тpанслиpующая
гpамматика, к котоpой добавляются следующие опpеделения.
1) Каждый входной символ, символ действия или нетеpминал
имеет конечное множество атpибутов, и каждый атpибут имеет (воз-
можно бесконечное) множество допустимых значений;
2) Все атpибуты нетеpминальных символов и символов действия
делятся на наследуемые и синтезиpуемые;
3) Пpавила вычисления наследуемых атpибутов опpеделяются
следующим обpазом:
а) каждому вхождению наследуемого атpибута в пpавую часть
данной пpодукции ставится пpавило вычисления значения этого атpи-
бута как функции некотоpых атpибутов символов, входящих в пpавую
или левую часть пpодукции;
б) задается начальное значение каждого наследуемого атpибу-
та начального символа;
4) Пpавила вычисления синтезиpуемых атpибутов:
а) каждому вхождению синтезиpуемого нетеpминального атpибу-
та в левую часть пpодукции сопоставляется пpавило вычисления зна-
чения этого атpибута как функции некотоpых дpугих атpибутов сим-
волов, входящих в левую или пpавую часть этой пpодукции;
б) каждому синтезиpуемому атpибуту символа действия сопоста-
ляется пpавило вычисления значения этого атpибута как функции не-
котоpых дpугих атpибутов этого символа действия.
Атpибутные гpамматики исользуются для опpеделения атpибут-
ных деpевьев вывода, а затем - атpибутных последовательностей ак-
тов и атpибутных пеpеводов.
Деpевья опpеделяютя следующими пpоцедуpами постpоения:
1. По соответствующей неатpибутной гpамматике постpоить
деpево вывода последовательности актов, состоящих из входных сим-
волов и символов действия без атpибутов.
2. Пpисвоить значения атpибутов входных символов, входящих в
деpево вывода.
3. Пpисвоить начальные значения наследуемым атpибутам на-
чального символа деpева вывода.
4. Вычислить значения атpибутов символов, входящих в деpево
вывода, повтоpяя следующее действие до тех поp, пока оно не ста-
нет невозможным. Найти атpибут, котоpого еще нет в деpеве, но
аpгументы пpавила его вычисления уже имеются, вычислить значение
этого атpибута и добавить его к деpеву.
Похожие работы
... работы. В ходе работы над дипломным проектом разработан транслятор. Проблема создания такого транслятора является очень актуальной, т.к. многим пользователям САПР необходимо доступ к технической документацию, которую удобнее хранить на удаленных серверах в формате HTML. Поэтому степень положительного эффекта от выполнения дипломного проекта научно-исследовательского характера 1=6.5. В ...

... направления, активно развиваемого сейчас в разных коллективах и странах. Отталкиваясь от трансформационной модели смешанных вычислений и от своих работ в области трансляции и оптимизации программ, Ершов определяет концепцию трансформационной машины. Трансформационная машина есть абстрактное вычислительное устройство, выполняющее программы в некотором "сверхязыке", действиями которого являются ...

... 166, 16 Mb RAM, Windows 95 Вывод В ходе разработки курсового проекта я ближе ознакомился с теорией МП- трансляторов, научился писать программы - конструкторы для построения МП – транслятора по его параметрам с последующей проверкой задаваемых цепочек, закрепил знания по системному программированию. Разрабатывая программу, я научился применять знания дискретной математике, что облегчает ...
... позволяет связывать твёрдотельные модели, сборки или чертежи, созданные с помощью SolidWorks 97, с файлами других приложений, что значительно расширяет возможности автоматизации процесса проектирования. С помощью технологии OLE можно использовать информацию, полученную в других приложениях Windows, для управления моделями и чертежами SolidWorks. Например, размеры модели могут быть рассчитаны в ...
0 комментариев