Семестр: Отладка разработанного ПО и оформление протоко-
В строке ...SiSj... символы Si и Sj входят в одну и ту
В множество L(U) самых левых символов нетерминального
Пусть между некоторыми двумя символами Si и Sj сущес-
I i 1
Не предусмотрен выход при выполнении условия R > R , так как
Потом повторяется п. 5
Если выполнение шага 4 пpиведет к тому, что значения всех
Перевод инфиксной записи в польскую. Всякий раз, когда в
Когда редуцируется основа XY..Z, тетрады для всех нетер-
Опреанды и операторы
Если сканируемый символ - унарный оператор, то он приме-
А * В + С * D => *, A, B, T1 ┐ тетрады располагаются в
Устраняет недостатки программы,вызванные небрежностью или
Проверяется
непртиворечивость типов получателя и ис-
ДИСПЛЕЙ
Выделение памяти под рамку в процессе трансляции
ОРГАНИЗАЦИЯ ПАМЯТИ ВО ВРЕМЯ ТРАНСЛЯЦИИ
Алгоритм Биледи
Возможные параметры описания переменных и процедур
Навигация
Перевод инфиксной записи в польскую. Всякий раз, когда в
Проектирование трансляторов
319724
знака
0
таблиц
0
изображений
1. Перевод инфиксной записи в польскую. Всякий раз, когда в
сентециальной форме найдена основа Х, редуцируемая к нетерминалу
U, синтаксический распознаватель вызывает программу, связанную с
правилами U ::= X.
Программа осуществляет обработку символов в Х и выдает ту
часть польской цепочки, которая имеет непосредственное отношение
к Х. Так как : (1) основа редуцируется при каждой редукции,то (2)
если в основе встречается нетерминал V, то часть польской цепоч-
ки, включающая подцепочку, которая приводится к V, уже была сге-
нерирована.
Считаем, что генерируемая польская цепочка хранится в од─
номерном массиве Р. Пусть р ─ содержит адрес первого свободно─
го элемента Р (Рнач=1). Вызванная программа имеет доступ к симво-
лам основы s(1),...,s(i), находящимся в синтаксическом стеке рас-
познавателя.
Программа, связанная с правилом Е1 ::= Е2+Т
В момент ее вызова согласно (2) массив Р содержит
...<код для Е2><код для Т>,
т.к. сначала генерируется код для Е (основа ─ самая левая
простая фраза), потом для Т. Справа от Т только терминалы.
Очевидно данная программа должна поместить знак + в поль─
скую цепочку. При этом Е2+Т переводится в запись Е2 Т +. Следо─
вательно семантическая программа имеет вид Р(р):="+";р:=р+1.
Программа для правила F ::= I (I─любой идентификатор)
По правилам польской записи (ЛК10) идентификаторы пред─
шествуют своим операторам и идут в том же порядке, что и в инфик-
сной записи. То есть необходимо лишь занести идентификатор в Р.
Р(р) := s(i); р:=р+1 s(i)─верхний символ стека
Для правила F ::= (E) действия не включаются, т.к. скобок в
польской записи нет, а для Е польская запись уже сгенерирова─
на. Аналогично рассуждая получим:
правило семантическая программа
(1) Z ::= T нет
(2) E ::= T нет
(3) E ::= E+T P(p):='+';p:=p+1
(4) E ::= E─T P(p):='─';p:=p+1
(5) E ::= ─T P(p):='@';p:=p+1
(6) T ::= F нет
(7) T ::= T*F P(p):='*';p:=p+1
(8) T ::= T/F P(p):='/';p:=p+1
(9) F ::= I P(p):=s(i);p:=p+1
(10)F ::= (E) нет
Очевидно для правил 3,4,7,8 можно иметь одну программу:
P(p):=s(i─1); p:=p+1
2.Преобразование инфиксной записи в тетрады
Будем генерировать теперь для А*(В+С) тетрады:
+В,С,Т1
*А,Т1,Т2
Первую тетраду попытаемся сгенерировать при редукции по прави─
лу Е ::= Е+Т. К этому моменту синтаксическое дерево будет иметь
вид (а).
Е,Т1
Е │
│ ┌──┴──┐
T T T │ │
│ │ │ E,B │
F F F │ │
│ │ │ T,A T,B T,C
A * (B + C) │ │ │
F,A F,B F,C
(a) │ │ │ (б)
A * ( B + C )
На следущем шаге приведения Е+Т к Е семантическая программа
должна выдать тетраду, однако сентенциальная форма {Т*(Е+Т)}не
содержит информации об именах Е и Т. При получении польской
записи имена В и С заносились в выходную цепочку при выполне─
нии редукций F ::= B и F ::= C.
Очевидно, что нам также необходимо в момент редукций F ::=I где─то запомнить информацию об именах редуцируемых
идентификаторов до момента их использования. Заметим, что ска─
нер для каждого идентификатора выдает пары вида (I,B),(I,C),.., причем символ I связан с синтаксической инфор─
мацией, В или С (имя) ─ с семантикой символа.
Привяжем к каждому нетерминалу U (узлу дерева) семанти─
ческую информацию U.SEM. Кроме того, будем генерировать имена
Т1,Т2,.. для обозначения подвыражений, используя для этого
счетчик i. В начале i=0. Операция генерации нового идентифика─
тора и его привязка к U имеет вид
i:=i+1; U.SEM:=Ti
Для генерации тетрады используем процедуру с 4 палитрами:
ENTER(W,X,Y,Z). Тогда получим:
правило семантическая программа
(1) Z ::= Е Z.SEM:=E.SEM
(2) E ::= T E.SEM:=T.SEM
(3) E1 ::= E2+T i:=i+1 E1.SEM:=Ti
ENTER('+',E2.SEM,T.SEM,E1.SEM)
(4) E1 ::= E2─T i:=i+1 E1.SEM:=Ti
ENTER('─',E2.SEM,T.SEM,E1.SEM)
(5) E ::= ─T i:=i+1 E.SEM:=Ti P(p):='@';p:=p+1
ENTER('@',0,T.SEM,E.SEM)
(6) T ::= F T.SEM:=F.SEM
(7) T ::= T*F
(8) T ::= T/F
(9) F ::= I
(10)F ::= (E) F.SEM:=E.SEM
Реализация семантических программ и семантических стеков
Для привязки семантических атрибутов к нетерминалам ис-
пользуются семантические стеки для каждого атрибута (или один
стек с отдельными полями для хранения синтаксического символа и
его семантических атрибутов). Эти стеки должны хранить семанти-
ческую информацию, которая связана с нетерминалами, входящими в
текущую сентенциальную форму. Эти стеки работают параллельно с
синтаксическим стеком S (т.е. удаление и занесение в них синхро-
низировано). Семантическая программа имеет доступ ко всем стекам.
┌───┬────────┬──────┬───────┬────┐
│ E │ │ REAL │ │ 20 │
├───┼────────┼──────┼───────┼────┤
│ + │ │ │ │ │
├───┼────────┼──────┼───────┼────┤
│ T │ │ INT │ │ 40 │
├───┼────────┼──────┼───────┼────┤
│ . │ │ . │ │ . │
│ . │ │ . │ │ . │
│ . │ │ . │ │ . │
└───┴────────┴──────┴───────┴────┘
В действительности не имеет значения, сколько используется
стеков.
Рассмотрим несколько алгоритмов семантической обработки
для языка типа АЛГОЛ.
1.Условные инструкции
<инстр1>::=<условие><инстр2>ELSE<инстр3>│<условие><инстр2>
<условие>::=IF<выраж>THEN,
где <выраж> должно иметь тип BOOLEAN.
Необходимо сгенерировать тетрады одного из двух видов: (1)
тетрады для Т::=<выраж> (1) тетрады для Т::=<выраж> (p) BZ
q+1,T,0 (p) BZ q,T,0
<инстр2> <инстр2>
(q) BR r (q)
(q+1) <инстр3>
(r)
Программа генерации (Р)тетрады связана с правилом:
<условие>::=IF<выраж>THEN и имеет следующий вид:
(1) Р:=<выраж>,ENTRY;─занести в Р адрес элемента TS для <выфаж>
(2) CHECKTYPE(P,BOOLEAN); ─проверить, что тип <выраж> BOOLEAN
(3) <условие>,JUMP:=NEXTQUAD; ─запомнить номер следущей тетрады
(4) ENTER(BZ,0,P,0); ─генерация BZ─тетрады
Общее правило для доступа к семантическим стекам: Если осно-
ва х рассматриваемой сентенциальной формы должна быть приведена с
помощью правила U::=x к U, то для работы с семантикой символов
используется программа, которая:
1) заносит информацию в TS или проверяет ее;
2) проверяет семантическую информацию, связанную с х;
3) генерирует тетрады;
4) связывает семантическую информацию с U;
Для обращения в стеки за семантической информацией SEM, свя-
занной с U, применяем обозначение U.SEM. 1.I.NAME ─ указатель,
используется для доступа к имени идентификатора
2.<пер>ENTRY ─ выдает указатель на элемент таблицы символов для переменной <пер>
3.<выр>ENTRY ─ указатель на значение (уже выполненного) выражения <выр>
4.<условие>JUMP ─ содержит номер BZ тетрады, в которую позднее надо добавить адрес перехода, который еще не известен
Следущая редукция будет связана с правилом: <инстр1>::=<ус-
ловие><инстр2> I:=<условие>.JUMP Занести номер следущей тетрады
во вторую QU- AD(I,2):=NEXTQUAD компоненту тетрады с помощью I,
т.е. получить (BZq+1,p,0)
Операнды во внутренней форме будем представлять указателем Р
на соответствующий элемент таблицы символов. Ссылка на его атри-
бут будет иметь вид: Р.TYPE,P.TYPE1. Очевидно, если инструкция
содержит ELSE, то между <инстр2> и <инстр3> нужно как бы вста-
вить команду BR. Но при таком синтаксисе конструкция <инстр1> с
ELSE будет распознана лишь после разбора <инстр2> и <инстр3>.
Т.е. будет специфицирована цепочка команд для <инстр2> и <инстр3>.
Преобразуем синтаксис в соответствии с желаемой семантикой:
<инстр1>::=<ист.часть><инстр3>
<ист.часть>::=<условие><инстр2>ELSE
<ист.часть>::=<условие><инстр2>ELSE
<ист.часть>.JUMP:=NEXTQUAD; ─ запомнить номер следущей тетрады
ENTER(BR,0,0,0); в стеке
I:=<условие>.JUMP; ─ занести в BZ переход через <инстр1>
QUAD(I,2):=NEXTQUAD;
<инстр1>::=<ист.часть><инстр3>
I:=<ист.часть>.JUMP; - вставить адрес перехода через
QUAD(I,2):=NEXTQUAD; <инстр2> в (BR...)
Выводы:
Похожие работы
... работы. В ходе работы над дипломным проектом разработан транслятор. Проблема создания такого транслятора является очень актуальной, т.к. многим пользователям САПР необходимо доступ к технической документацию, которую удобнее хранить на удаленных серверах в формате HTML. Поэтому степень положительного эффекта от выполнения дипломного проекта научно-исследовательского характера 1=6.5. В ...

... направления, активно развиваемого сейчас в разных коллективах и странах. Отталкиваясь от трансформационной модели смешанных вычислений и от своих работ в области трансляции и оптимизации программ, Ершов определяет концепцию трансформационной машины. Трансформационная машина есть абстрактное вычислительное устройство, выполняющее программы в некотором "сверхязыке", действиями которого являются ...
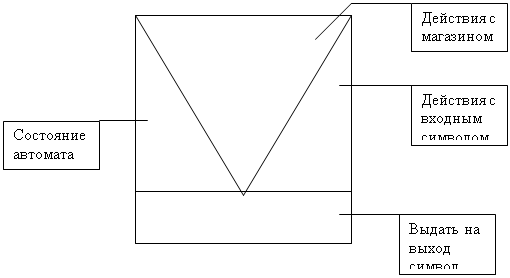
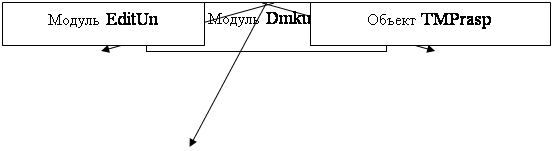

... 166, 16 Mb RAM, Windows 95 Вывод В ходе разработки курсового проекта я ближе ознакомился с теорией МП- трансляторов, научился писать программы - конструкторы для построения МП – транслятора по его параметрам с последующей проверкой задаваемых цепочек, закрепил знания по системному программированию. Разрабатывая программу, я научился применять знания дискретной математике, что облегчает ...
... позволяет связывать твёрдотельные модели, сборки или чертежи, созданные с помощью SolidWorks 97, с файлами других приложений, что значительно расширяет возможности автоматизации процесса проектирования. С помощью технологии OLE можно использовать информацию, полученную в других приложениях Windows, для управления моделями и чертежами SolidWorks. Например, размеры модели могут быть рассчитаны в ...
0 комментариев