Семестр: Отладка разработанного ПО и оформление протоко-
В строке ...SiSj... символы Si и Sj входят в одну и ту
В множество L(U) самых левых символов нетерминального
Пусть между некоторыми двумя символами Si и Sj сущес-
I i 1
Не предусмотрен выход при выполнении условия R > R , так как
Потом повторяется п. 5
Если выполнение шага 4 пpиведет к тому, что значения всех
Перевод инфиксной записи в польскую. Всякий раз, когда в
Когда редуцируется основа XY..Z, тетрады для всех нетер-
Опреанды и операторы
Если сканируемый символ - унарный оператор, то он приме-
А * В + С * D => *, A, B, T1 ┐ тетрады располагаются в
Устраняет недостатки программы,вызванные небрежностью или
Проверяется
непртиворечивость типов получателя и ис-
ДИСПЛЕЙ
Выделение памяти под рамку в процессе трансляции
ОРГАНИЗАЦИЯ ПАМЯТИ ВО ВРЕМЯ ТРАНСЛЯЦИИ
Алгоритм Биледи
Возможные параметры описания переменных и процедур
Навигация
В множество L(U) самых левых символов нетерминального
Проектирование трансляторов
319724
знака
0
таблиц
0
изображений
4. В множество L(U) самых левых символов нетерминального
символа U входят все символы S такие, что существует порождение:
U -> Sz,
где z - некоторая строка (возможно, пустая).
Это определения может быть записано в виде:
Л(U) = { S | существует строка z, такая, что (U -> Sz) }.
5. В множество R(U) самых правых символов нетерминального
символа U входят все символы S такие, что существует порождение:
U -> zS,
где z - некоторая строка (возможно, пустая).
Это определения может быть записано в виде:
R(U) = { S | существует строка z, такая, что (U -> zS) }.
Данные выше формальные определения отношений предшествова-
ния и множеств самых левых и самых правых символов хорошо отра-
жают содержательную сторону определяемых понятий, но для их на-
хождения с помощью ЭВМ целесообразно использовать следующие ре-
курсивные определения (символ ] означает существование, символ /\
- "И", символ \/ - "ИЛИ", символ ф - правило):
1а. Si = Sj ::= ] ф (ф: U ::= xSiSjy).
2а. Si < Sj ::= ] ф ((ф: U ::= xSiUly) /\ Sj С L(Ul)).
3а. Si > Sj ::= ] ф ((ф: U ::= xUkSjy) /\ Si С R(Uk)) \/
(] ф ((ф: U ::= xUkUly) /\ Si С R(Uk)) /\
Sj С L(Ul)).
4a. L(U)= S | ]z (U ::= Sz) \/ ]z, U1 (U ::= U1z /\ S С L(U1)).
5a. R(U)= S | ]z (U ::= zS) \/ ]z, U1 (U ::= zU1 /\ S С R(U1)).
Всюду ф C P.
Определения 1а-5а дают эффективный алгоритм нахождения мно-
жеств L(U) и R(U) и отношений предшествования.
Рассмотрим алгоритм нахождение множества самых левых симво-
лов для символов, принадлежащих Vn.
Шаг 1: проверяем, является ли i-ый символ самым левым в
l-том синтаксическом правиле. Если да, то записываем Si в табли-
цу самых левых символов нетерминального символа Ul (при условии,
что он туда еще не записан);
Шаг 2: проверяем, не является ли символ Ul, для которого Si
- самый левый, самым левым символом Uk. Если да, то записываем
символы Ul и Si в таблицу самых левых символов нетерминального
символа Uk (при условии, что они туда еще не записаны).
Осуществляем просмотр всех синтаксических правил, изменяя
индекс l и k (два индекса для того, чтобы различать нетерми-
нальные символы в левой (k) и правой (l) частях правила); индекс
i указывает номер символа в синтаксическом правиле. Блок-схема
алгоритма показана на рис. 2.
┌─────┐
│ 1 │
└──┬──┘
│
┌──┴──┐
│ 2 ├──────────┐
└──┬──┘ │
│ │
нет / \ │
┌─────< 3 > │
│ \ / │
│ │да │
│ ┌──┴──┐ │
│ │ 4 │ │
│ └──┬──┘ │
└───────┤ │<
┌──┴──┐ / \ > ┌─────┐
│ 5 │ <13 >────┤ВЫХОД│
└──┬──┘ \ / └─────┘
┌────────────┤ │
│ / \ нет ┌──┴──┐
│ < 6 >────┐ │ 12 │
│ \ / │ └──┬──┘
│ да│ │ │да
┌──┴──┐ ┌──┴──┐ │нет / \
│ 9 │ │ 7 │ ├────<11 >
└──┬──┘ └──┬──┘ │ \ /
│ ├──────┘ │
│ < / \ > ┌──┴──┐
└──────────< 8 >────────┤ 10 │
\ / └─────┘
Рис. 2. Блок-схема алгоритма нахождения самых левых символов
Обозначения к алгоритму:
1. l = 1.
2. i = 1 - номер символа в синтаксическом правиле.
3. ] P: Ul ::= Si z - является ли i-ый символ самым левым
в синтаксическом правиле l.
4. Si записать в L(Ul): (L(Ul) = L (Ul) U Si).
5. k = 1.
6. ] P: Uk ::= Ul z - является ли Ul самым левым символом Uk
при условии, что Si C L(Ul).
7. L (Uk) = L (Uk) U Ul U Si - дополнить символами Ul и Si
мн-во L(Ul)
8. k < l (k, l - номера синтаксических правил),
проверка окончания цепочки.
9. k = k + 1.
10. i = i + 1.
11. Si = ; - завершилось ли синтаксическое правило.
12. l = l + 1.
13. l <= (L - общее число грамматических правил в грамматике).
Допущения к алгоритму:
- синтаксические правила отделены друг от друга ";"
- левая часть не отделяется от правой, и левая часть (т.е.
контекстно-свободная грамматика) всегда состоит из одного символа.
Аналогично можно построить множество самых правых символов.
Теперь перейдем к нахождению матрицы предшествования.
Блок-схема алгоритма построения матрицы предшествования, ис-
пользующая определения 1а-3а, представлена на рис. 3. Используют-
ся следующие условные обозначения:
i, j - индексы определяют номер символа в списке символов
языка.
M[i,j] - элемент матрицы предшествования;
l, k - номера синтаксических правил языка.
┌─────┐
│ 1 │
└──┬──┘
│
┌──┴──┐
│ 2 ├─────────────────────────┐
└──┬──┘ │
│ │
┌─────┐ / \ │
│ 4 │────< 3 >─────────────────┐ │
└─────┘ \ / │ │
│ │ │
┌──┴──┐ │ │
│ 5 │ │ │
└──┬──┘ │ │
├────────┐ │ │
/ \ да / \ │ │ │
┌──────────< 7 >────< 6 > │ │ │
│ \ / \ / │ │ │
│ │нет │нет │ │ │
│┌─────┐ │ / \ ┌──┴──┐ │ │
└┤ 8 ├─────┴──────< 9 >───┤ 10 │ │ │
└─────┘ \ / < └─────┘ │ │
│> │ │
┌──┴──┐ │ │
│ 11 │ │ │
└──┬──┘ │ │
├────────┐ │ │
┌─────┐ да / \ да / \ │ │ │
│ 14 ├───<13 >────<12 > │ │ │
└──┬──┘ \ / \ / │ │ │
└────────┴────────┤ │ │ │
/ \ ┌──┴──┐ │ │
<15 >───┤ 16 │ │ │
\ / < └─────┘ │ │
│ │ ┌──┴──┐
┌──┴──┐ │ │ 29 │
│ 17 │ │ └──┬──┘
└──┬──┘ ┌──┴──┐ │
├─────────────┐ │ 30 │ / \ > ┌─────┐
┌──┴──┐ │ └──┬──┘ <28 >───┤ВЫХОД│
│ 18 │ │ │ \ / └─────┘
└──┬──┘ │ │ ┌───┘
│ │ │ │>
нет / \ ┌──┴──┐ │ / \
┌──────────────────< 19 > │ 26 │ └──<27 >
│ \ / └──┬──┘ < \ /
│ │ │< │
│┌─────┐да / \ да / \ / \ │
││ 22 ├───<21 >────<20 > <25 >────────┘
│└──┬──┘ \ / \ / \ / >
│ │ │нет │ │
│ │ │ / \ < ┌─────┐ │
└───┴────────┴──────<23 >───┤ 24 │ │
\ / └─────┘ │
│> │
└─────────────┘
Рис. 3. Блок-схема алгоритма построения матрицы предшествования
для контекстно-свободных грамматик
Обозначения к алгоритму 1:
1. i = 1 (номер символа в алфавите языка).
2. j = 1.
3. ] P: U ::= x Si Sj - проверка наличия отношения = и
нахождение элемента матрицы с этим
отношением.
4. М [i,j]= =.
5. k = 1 (k,l - номера синтаксических правил).
6. Si C L (Uk) - находят элементы матрицы.
7. ] P: U ::= x Si Ux y имеющие отношение <.
8. М [i,j] = <.
9. k < j.
10. k = k + 1.
11. k = 1.
12. Si C L(Uk) находят элементы матрицы.
13. ] P: U ::= x Uk Sj y соответствующие отношению >
14. М [i,j] = >.
15. k < j.
16. k = k + 1.
17. k = 1.
18. l = 1.
19. Si C L(Uk) находят
20. Si C L(Ul) элементы матрицы,
21. ] P: U ::= x Uk Ul y соответствующие отношению >
22. М [i,j] = >.
23. l > j.
24. l = l + 1.
25. k < j.
26. k = k + 1.
27. j < I (I - мощность словаря языка).
28. i < I.
29. i = i + 1.
30. j = j + 1.
Блок 3 проверяет условие 1а и находит элементы матрицы, рав-
ные =, блок 4 записывает значение элемента в матрицу.
Блоки 6 и 7 проверяют условие 2а и находят элементы матрицы,
равные <.
Блок 8 записывает значение элемента в матрицу.
Блоки 12, 13, 19, 20 и 21 проверяют условия 3а и находят
элементы, равные >, блоки 14 и 22 записывают значения этих эле-
ментов в матрицу.
Остальные этапы выполнения алгоритма видны из блок-схемы.
Данный алгоритм не ограничивается нахождением только одного
отношения предшествования между любыми двумя символами Si и Sj, а
записывает в матрицу все отношения предшествования, которые меж-
ду ними существуют. Такая матрица не может использоваться в алго-
ритме анализа программы, так как не ясно, какое из отношений
предшествования между двумя символами брать для нахождения грани-
цы в каждом отдельном случае.
Но введением дополнительных нетерминальных символов и изме-
нением синтаксических правил, которые не меняют правил написания
программ на языке программирования, т. е. эквивалентным преобра-
зованием грамматик, можно добиться того, чтобы между каждой па-
рой символов существовало не более одного отношения предшествова-
ния.
Единого алгоритма, преобразующего любую КС-грамматику в
грамматику типа 2 по классификации Хомского, отвечающую двум до-
полнительным ограничениям:
- однозначности отношений предшествования;
- отсутствие двух грамматических правил с одинаковыми правы-
ми частями
НЕ СУЩЕСТВУЕТ.
Но, построив матрицу предшествований и выяснив неоднознач-
ность отношений между некоторыми символами, эту неоднозначность
можно устранить введением дополнительных нетерминальных символов
и некоторым изменением синтаксических правил.
Рассмотрим несколько алгоритмов, позволяющих преобразовать
КС-грамматику в грамматику типа 2 с учетом указанных ограничений:
Похожие работы
... работы. В ходе работы над дипломным проектом разработан транслятор. Проблема создания такого транслятора является очень актуальной, т.к. многим пользователям САПР необходимо доступ к технической документацию, которую удобнее хранить на удаленных серверах в формате HTML. Поэтому степень положительного эффекта от выполнения дипломного проекта научно-исследовательского характера 1=6.5. В ...

... направления, активно развиваемого сейчас в разных коллективах и странах. Отталкиваясь от трансформационной модели смешанных вычислений и от своих работ в области трансляции и оптимизации программ, Ершов определяет концепцию трансформационной машины. Трансформационная машина есть абстрактное вычислительное устройство, выполняющее программы в некотором "сверхязыке", действиями которого являются ...
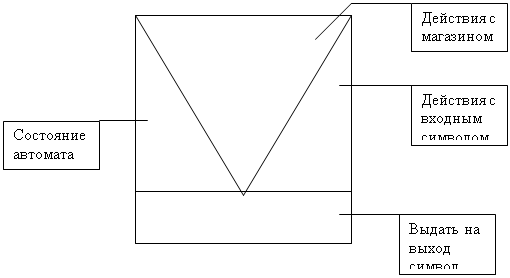

... 166, 16 Mb RAM, Windows 95 Вывод В ходе разработки курсового проекта я ближе ознакомился с теорией МП- трансляторов, научился писать программы - конструкторы для построения МП – транслятора по его параметрам с последующей проверкой задаваемых цепочек, закрепил знания по системному программированию. Разрабатывая программу, я научился применять знания дискретной математике, что облегчает ...
... позволяет связывать твёрдотельные модели, сборки или чертежи, созданные с помощью SolidWorks 97, с файлами других приложений, что значительно расширяет возможности автоматизации процесса проектирования. С помощью технологии OLE можно использовать информацию, полученную в других приложениях Windows, для управления моделями и чертежами SolidWorks. Например, размеры модели могут быть рассчитаны в ...
0 комментариев