Семестр: Отладка разработанного ПО и оформление протоко-
В строке ...SiSj... символы Si и Sj входят в одну и ту
В множество L(U) самых левых символов нетерминального
Пусть между некоторыми двумя символами Si и Sj сущес-
I i 1
Не предусмотрен выход при выполнении условия R > R , так как
Потом повторяется п. 5
Если выполнение шага 4 пpиведет к тому, что значения всех
Перевод инфиксной записи в польскую. Всякий раз, когда в
Когда редуцируется основа XY..Z, тетрады для всех нетер-
Опреанды и операторы
Если сканируемый символ - унарный оператор, то он приме-
А * В + С * D => *, A, B, T1 ┐ тетрады располагаются в
Устраняет недостатки программы,вызванные небрежностью или
Проверяется
непртиворечивость типов получателя и ис-
ДИСПЛЕЙ
Выделение памяти под рамку в процессе трансляции
ОРГАНИЗАЦИЯ ПАМЯТИ ВО ВРЕМЯ ТРАНСЛЯЦИИ
Алгоритм Биледи
Возможные параметры описания переменных и процедур
Навигация
Проверяется непртиворечивость типов получателя и ис-
Проектирование трансляторов
319724
знака
0
таблиц
0
изображений
1. Проверяется непртиворечивость типов получателя и ис-
точника. Так как получатель представляет собой адрес, источ-
ник должен давать что-нибудь приемлемое для присваивания это-
му адресу. В зависимости от реализуемого языка типы
получателя и источника можно определенным образом изменять до
выполнения присваивания. Например, если тип источника - целое
число, то его можно сначала преобразовать в вещественное, а
затем присвоить адрес, имеющему тип вещественного числа.
2. Там, где это необходимо, проверяются правила области
действия. В Алголе 68 источник не может иметь меньшую область
действия, чем получатель. Например, в
begin ref real xx;
begin real x;
xx := x
end
присваивание недопустимо, и это может быть обнаружено во вре-
мя компиляции, если в таблице символов или в нижнем стеке
имеется информация об области действия. Однако в процессе
компиляции нельзя обнаружить все нарушения правил области
действия, и в некоторых случаях для проверки этой области
приходится создавть код во время прогона.
3. Генерируется код для присваивания, имеющий форму
ASSIGN type,S,D
где S - адрес источника, а D - адрес получателя.
4. Если язык ориентирован на выражения ( то есть само
присвоение имеет значение ), статические характеристики этого
значения помещаются в нижний стек.
II. Условные зависимости
Почти все языки содержат условное выражение или опера-
тор, аналогичный следующему:
if B then C else D fi
При генерации кода для такой условной зависимости во
время компиляции выполняются три действия. Грамматика с вклю-
ченными действиями:
CONDITIONAL -> if B <A1> then C <A2> else D <A3> fi
Действия А1, А2 и А3 означают (next - значение номера
следующей метки, присваиваемое компилятором):
А1. Проверить тип В, применяя любые необходимые преобра-
зования (приведения) типа для получения логического значения.
Выдать код для перехода к L<next>, если В есть "ложь":
JUMPF L<next>,<address of B>
Поместить в стек значение next ( обычно для этого служит
стек знаков операций ). Увеличить next на 1. (Угловые скобки
(<,>), в которые заключаются "next" и "address of B", исполь-
зуются для обозначения значений этих величин, и их не следует
путать со скобками, в которые заключаются действия в порожда-
ющих правилах грамматики.)
А2. Генерировать код для перехода через ветвь else (
т.е. перехода к концу условной зависимости )
GOTO L<next>
Удалить из стека номер метки ( помещенный в стек дейс-
твием А1 ), назвать i, генерировать код для размещения метки
SETLEBEL L<i>
Поместить в стек значение next. Увеличить next на 1.
А3. Удалить из стека номер метки (j). Генерировать код
для размещения метки
SETLABEL L<j>
Если условная зависимость сама является выражением ( а
не оператором ), компилятор должен знать, где хранить его
значение, независимо от того, какая часть вычисляется - then
или else. Это можно сделать, специфицируя адрес, который ука-
зывает на данное значение, или пересылая значение, заданное
частью then либо частью else, по указанному адресу.
Аналогично можно обращаться с вложенными условными выра-
жениями или операторами.
III. Описания идентификаторов
Допустим, что типы всех идентификаторов полностью выяс-
нены в предыдущем проходе и помещены в таблицу символов. Ад-
реса распределяются во время прохода, гененрирующего код.
Рассмотрим описание
somemode x
еречислим действия, выполняемые во время компиляции:
1. В таблице символов производится поиск записи, соот-
ветствующей x.
2. Текущее значение указателя стека идентификаторов дает
адрес, который нужно выделить для x. Этот адрес
(idstack, current block number, idstack pointer)
включается в таблицу символов, а указатель стека идентифика-
торов увеличивается на статический размер значения, соответс-
твующего х. (В Алголе 68, если вид х начинается с ref, обьем
памяти должен выделяться для значения, на которое ссылается
х, а не для самого х; это обозначается с помощью адреса дру-
гого типа. )
3. Если х имеет динамическую часть, например в случае
массива, то генерируется код для размещения динамической па-
мяти во время прогона.
IV. Вход и выход из блока
При входе в блок ( последовательное предложение с описа-
ниями в Алгол 68 ) предположим, что во время предыдущего про-
хода получена определенная информация. Она состоит из таблиц
видов и символов, дающих типы или виды всех идентификаторов и
т.п. Тогда при входе в блок нужно выполнить следующие основ-
ные действия:
1. Прочитать в таблице символов информацию, касающуюся
блока, и связать ее с информацией включающих блоков таким об-
разом, чтобы можно было выполнить "внешние" поиски определяю-
щих реализаций идентификаторов и т.д.
2. Поместить в стек (idstack pointer). Поместить в стек
(wostack pointer). Поместить в стек (block number). Все эти
значения ссылаются на включающий блок и могут потребоваться
вновь после того, как будет покинуть блок, в который только
что осуществлен вход:
idstack pointer := 0
wostack pointer := 0
3. Генерировать код для исправления DISPLAY
BLOCK ENTRY block number
4. Увеличить номер уровня блока на 1. Увеличить наиболь-
ший использованный до сих пор номер блока на 1 и присвоить
это значение номеру блока.
5. Прочитать информацию о виде и добавить ее в таблицу
видов ( если в языке имеются такие "сложные" виды, как в Ал-
голе 68 ).
При выходе из блока требуется:
1. Обновить таблицу блоков, задав размер стека идентифи-
каторов и т.п. для покинутого блока.
2. Исключить информацию в виде таблицы символов для по-
кинутого блока.
3. Генерировать код для изменения дисплея
BLOCK EXIT block number
4. Удалить из стека (block number). Удалить из стека
(wostack pointer). Удалить из стека (idstack pointer). Умень-
шить номер уровня на 1.
5. Поместить результат (при необходимости) в рамку стека
вызывающего блока.
ЛЕКЦИЯ 16
КОНТЕКСТНЫЕ УСЛОВИЯ ЯЗЫКОВ ПРОГРАММИРОВАНИЯ
КОНТЕКСТНЫЕ УСЛОВИЯ 1-ОГО И 2-ОГО ТИПА
1. Условия, связанные с описанием правил идентификаторов
В каждом блоке без внутренних блоков идентификатор нельзя
описывать более одного раза.
Для процедур и функций ни один идентификатор не должен вхо-
дить более одного раза в список формальных параметров в совокуп-
ности спецификаций.
2. Правила соответствия между определяющими и использующими
вхождениями идентификаторов.
.
Правила поиска часто называют алгоритмами идентификации.
Проверим одно контекстное условие:
1. Рассмотрим min блок.
2. Ищем определяющее вхождение идентификатора в рассмотрен-
ном блоке. Если оно найдено, то процедура идентификации законче-
на.
Иначе - шаг 3.
3. Ищем min блок, который мы рассмотрели в шаге 2. Если та-
кой блок найден, рассмотрим его и переходим к шагу 2. Иначе,
процедура закончена.
Это мы проверяем одно контекстное условие.
Однако, задача идентификации сложнее, т.к. обычно рассмат-
ривается группа контекстных условий.
1. Каждый идентификатор, входящий в совокупность специфика-
ций, должен также входить в список формальных параметров.
2. Каждый идентификатор, входящий в список значений, должен
входить в совокупность спецификаций.
3. Идентификаторы, входящие в тело процедуры, могут быть
описаны в блоке, вне этого блока или могут быть включены в
список формальных параметров.
Список спецификаций - заголовок (имя) функции, описание ти-
па функции.
Список значений - те параметры, кот. меняются при изменении
функции, т.е. результат.
КОНТЕКСТНЫЕ УСЛОВИЯ ТРЕТЬЕГО ТИПА
Они регламентируют:
1) Соответствие видов величин, входящих в синтаксические
конструкции программ.
2) Задание допустимых соотношений между формальными парамет-
рами в процессах и формальными описаниями соответствующих проце-
дур.
3) Сравнение индексов переменных в использующем и определяю-
щем вхождениях идентификаторов.
4) Сравнение размерности массива в используемом и определяю-
щем вхождении идентификатора.
КОНТЕКСТНЫЕ УСЛОВИЯ ЧЕТВЕРТОГО ТИПА
Некоторые логические ограничения, которые относятся к реа-
лизации той или иной версии транслятора.
Массив может быть с неограниченным размером.
ЛЕКЦИЯ 17
ПРОГРАММНЫЕ ГРАММАТИКИ
Правила вывода этих грамматик имеют тот же вид, что и у
классических, однако в отличии от последних на каждом шаге выво-
да правила, кот. могут быть применены, зависит не только от це-
почек вывода, но и от того, какие правила применялись на преды-
дущих шагах.
Gp = { Vт, Vn, P, I, S }
G - конечное множество целых положительных чисел
(множество меток)
** **
r) Ф -> psi │ W1 │ W2 │, W1, W2 - некоторое подмножество меток
│ * * *
метка,соотв. Ф,psi ( Vт U Vn )
выводу
* - соответствующий класс грамматическим правилам
** - обозначается некоторое подмножество
В терм. порожденной грамматике сформируем использование
данного грамматического файла.
w - промежуточная цепочка.
Если w содержит вхождения по цепочке Ф, то левое вхождение
Ф в цепочке заменяем на psi.
После чего к полученной цепочке вывода применяется правило,
помеченное метками из множества W1.
Если w не содержит вхождения строки Ф, то строка w не моди-
фицируется, и к ней применяется некоторое правило, полученное
меткой из множества W2.
Язык, порожденный этой грамматикой, содержит только терми-
нальные символы.
В зависимости от ограничений на классическую часть различа-
ют:
1) контекстно-свободные,
2) контекстно-зависимые,
3) укорачивающие грамматики.
Имеют место теории, которые доказывают, что программные кон-
текстно-свободной грамматики более мощные, чем просто контек-
стные-свободные грамматики, в то время как зависимые контек-
стно-свободные грамматики совпадают с программно контекстно-сво-
бодными грамматиками.
Когда применяются программные грамматики процесс трансляций
выполняется в 2 этапа:
1) Порождается промежуточная форма программы.
Имеет место некоторый промежуточный язык, в котором некото-
рые синтаксические конструкции отсутствуют (например, внутр.
блоки), а те, которые представлены - состоят из терминальных
символов-двойников, соответствующим терминальным символам прог-
раммы.
2) Промежуточная форма программы проверяется на предмет
соотношения контекстных условий и выполняется замена симво-
лов-двойников на терминальные символы программы.
Все терминальные символы в т.ч. и двойники должны использо-
ваться в различных модификациях.
После первого этапа выполняется проверка контекстных усло-
вий (2 этап).
Каждая проверка заключается в следующем:
- сначала выделяются конструкции, участвующие в проверке;
- выделение производится путем модификации символов, из ко-
торых эта конструкция состоит (присвоение индекса);
- далее производится сравнение выделенных конструкций;
способ зависит от конкретного контекстного условия (сравнение
может производиться на сравнение и не сравнение, т.д.)
Если результаты положительные, то производится вывод неко-
торых построенных конструкций.
На выходе все двойники заменяются на терминальные символы
(соответствующие).
КОНТЕКСТНЫЕ УСЛОВИЯ ДЛЯ ПРОГРАММНЫХ ГРАММАТИК
1. В каждом блоке без внутренних блоков каждый идентифика-
тор должен быть описан не более одного раза (это условие приме-
няется и для меток).
2. По каждому использующему вхождению идентификатора или
целого, представляющего метку, в данном или объемлющем блоках
должно быть описание этого идентификатора.
3. Все переменные в левых частях при присваивании должны
быть одного типа.
4. Количество индексов у переменных с индексами должно сов-
падать с числом пар граничащих массивов.
5. Количество и типы фактических параметров в операторах
процедур должны совпадать с количеством и типом форм. парамет-
ров, приведенных в описаниях процедур.
6. Фактический параметр, который соответствует формальному
параметру, вызываемому по наименованию и встреч. в левой части,
обязан быть переменной (а не выражением).
7. Идентификаторы,входящие в выражение для границ в описа-
ниях массивов, должны быть описаны в одном из объемлющих блоков.
ЛЕКЦИЯ 18
ГРАММАТИКИ ВАН ВЕЙНГААРДЕНА
ОПРЕДЕЛЕНИЕ: Грамматика ван Вейгаардена - это две связанные
грамматики, которые называются метаграмматикой или грамматикой
метаязыка и строгой грамматикой ( грамматикой ) языка:
Gv = < Gm, Gst >.
Gm = < Vs, Vm, Pm, M >
Vs - конечное множество малых синтаксических знаков ( в
русском издании "Пересмотренного сообщения об Алголе" множество
маленьких букв русского алфавита ).
Vl - конечное множество больших синтаксических знаков ( в
русском издании "Пересмотренного сообщения об Алголе" множество
больших букв русского алфавита ).
Vm - конечное множество метапонятий:
Vm с Vl+;
Vh - конечное множество гиперпонятий:
Vh с ( Vm U Vs )*;
Ah - конечное множество гиперальтернатив:
Ah с Vh ( {,} Vh )*
( гиперпонятия в гиперальтернативах отделяются запятыми ).
Ph - конечное множество гиперправил:
Ph с Vh {:} Ah ( {;} Ah )* {.}
( гиперальтернативы в гиперправилах отделяются точкой с
запятой, в конце гиперправила ставится точка ).
Правила в метаграмматике ( гиперправила ) также называются
формами или схемами.
Pm - конечное множество правил метапорождений:
Pm с Vm {::} Vh ( {;} Vh )* {.}
M - начальный символ грамматики ван Вейгаардена.
M с Vm
L ( Gm ) - ( в общем случае бесконечное ) множество терми-
нальных метапорождений метапонятия M: L ( Gm ) с Vs*
Пусть метапонятие MM имеет одно или более вхождений в ги-
перправило h. Согласованной заменой метапонятия MM в гиперправи-
ле h назовем замену всех его вхождений одним и тем же терминаль-
ным порождением Tm с L ( Gm ).
Правило порождения получается из гиперправила путем согласо-
ванной замены всех входящих в него метапонятий.
Понятием называется непустое ( протопонятие ), если для него
может быть получено правило порождения. Множество понятий как
раз является бесконечным множеством нетерминалов Vn грамматики.
Gst = < Vt, Vn, P, S >
Vt - конечное множество терминалов;
Vn - множество нетерминалов;
P - множество правил;
S - начальный символ грамматики
Множество правил порождения P определяется тем, что
P с Vn {:} A ( {;} A )* {.},
где Vn с Vs+ - множество понятий,
A с F ( {,} F )* - множество альтернатив,
F = 0 U Vt u Vn U B
0 - пустое множество;
B - множество тупиковых протопонятий.
Для тупикового протопонятия никакое правило порождения не
может быть выведено. Возможности тупиков используются в системе
предикатов для учета контекстных условий.
Предикат - это протопонятие имеющее одну из форм: where а (
если верно что а ) или unless а ( если неверно что а ).
Предикат выполняется ( используется правило под ним для по-
рождения ), если для него выводимо правило порождения, и в этом
случае его терминальное порождение всегда пусто, либо такой вы-
вод заводит в тупик, и в этом случае предикат не выполняется.
Таким образом, с правилом связывается контекст его примене-
ния.
Рассмотрим грамматику ван-Вейнгардена, описывающую синтаксис
оператора присваивания PASCAL-подобного языка и контролирующую
следующие контекстные условия (3-го рода по классификации Брат-
чикова)
1. Арифметическое выражение может состоять из выражений при-
надлежащих лишь арифметическим типам
2. Логическое выражение может состоять из выражений лишь ло-
гических типов
3. Не допускается смешивать в арифметических выражения раз-
личные типы
4. Переменной можно присваивать значение того же либо струк-
турно эквивалентного типа
Грамматика 1-го уровня
Нетерминальные символы метаграмматики
TYPE тип
ATYPE арифметический тип
PTYPE указательный тип ( указатель на нечто)
Правила метапорождения
TYPE ::= ATYPE | PTYPE | bool
PTYPE ::= pointer TYPE
ATYPE ::= int | float
Грамматика 2-го уровня
Реализация контексных условий основана на том что имена
терминальных и нетерминальных символов порождаемой граматики не-
сут в себе информацию о типе соответствующих объектов
Нетерминальные символы порождаемой грамматики
ass оператор присваивания
le TYPE левая часть оператора присваивания (выражение типа TYPE)
e TYPE правая часть оператора присваивания (lvalue типа TYPE)
e<n> TYPE выражения различных уровней приоритета
t TYPE терм (константа, переменная или выражение в скобках)
mulop операция *,/
addop +,-
compop <,>,>=,<=
boolop AND,OR
ass := le TYPE, ':=', e TYPE
le TYPE := id TYPE ; '^',le pointer TYPE
e1 ATYPE := e1 ATYPE, mulop, t ATYPE;t ATYPE
e2 ATYPE := e2 ATYPE, addop, e1 ATYPE; e1 ATYPE
t ATYPE := symbol id ATYPE; symbol const ATYPE; '(', e2 ATYPE, ')'
e3 bool := e3 ATYPE,compop ,e2 ATYPE ; symbol id bool ;symbol const bool
e4 bool := e4 bool ,boolop, e3; e3
e TYPE := e2 TYPE ; e4 TYPE
mulop := '*';'/'
addop := '+';'-'
compop := '<' ;'>';'<=';'>=';'='
boolop := 'AND' ;'OR'
Задача построения (конечной) контекстно-свободной грамма-
тики по грамматике ван-Вейнгардена решается путем разбиения бес-
конечных множеств терминальных и нетерминальных символов исход-
ной грамматики на конечное число классов, каждый из которых бу-
дет соответствовать терминалу либо нетеминалу строящейся грамма-
тики. Каждому классу соответствует цепочка символов метаграмма-
тики, из которой он выводится.
Нетерминалы КС-грамматики
ASS соответствует ass
LE ->le TYPE
E -> e
EN -> enTYPE
T -> t TYPE
MULOP ->mulop
ADDOP ->addop
COMPOP ->compop
BOOLOP ->boolop
Выполнив указанные выше замены в продукциях 2-го уровня (и
отбросив продукции грамматики 1-го уровня), получим
ASS := LE ':='E TYPE
LE := id | ^ LE
E1 := E1 MULOP T | T
E2 := E2 ADDOP E1 | E1
T :=id | const | (E2)
E3 :=E3 COMPOP E2 | id | const
E4 :=E4 BOOLOP E3 | E3
E := E2 | E4
MULOP := '*' | '/'
ADDOP := '+' |'-'
COMPOP := '<' ;'>';'<=';'>=';'='
BOOLOP := 'AND' ;'OR'
В заключение хотелось бы отметить различия в синтаксисе за-
писи правил КСграмматики и грамматики ван Вейнгардена. В первой
разделителями символов и метасимволов являются пробелы, раздели-
телями альтернатив являются знаки '|'. Терминальные символы за-
писываются малыми латинскими буквами, нетерминальные симво-
лы-большими. При записи грамматик ван Вейнгардена разделителями
символов являются запятые, разделителями альтернатив являются
точки с запятыми. Терминальные символы порождаемой грамматики
представляются цепочками терминалов метаграмматики, начинающими-
ся с терминала symbol.
ЛЕКЦИЯ 19
ПРИМЕР ГРАММАТИКИ ВАН ВЕЙНГААРДЕНА
Грамматикой ван Вейнгаардена описываются конструкции присваи-
вания вида ( например , преобразование типов в языке СИ) :
Пусть int i,j;
char c,ch;
т.е. описываем переменные i и j как целые,а c и ch как символь-
ные.Необходимо отметить , что для построения правильной конс-
трукции, выражающей присвоение переменной одного вида переменной
другого вида , в языке СИ необходимо в правой части перед соот-
ветствующим идентификатором нужно указать тип к которому должна
быть приведена переменная из правой части. Разумеется, этот тип
- тип переменной в левой части выражения . Если же имеет место
присвоение типа (2) ,т.е. типы переменных правой и левой частей
совпадают,то тип в правой части не указывается.
(1) c= (char) i;
(2) ch=c;
(3) ch= (char) j+c;
(4) i=(int) ch;
(5) c= (char) 20;
Для данных выражений типы правых частей не везде совпадают с
типами соответствующих им левых частей. Необходимо произвести
преобразование типа левой части к типу идентификатора в правой
части.
assign : е TYPE l,'=', e TYPE mod. /*Задание
конструкций присваивания*/
e TYPE l : id./*В левой части конструкции может быть
только идентификатор*/
/*Правая часть конструции может быть предс-
тавлена: */
e TYPE mod: e TYPE r ; /* выражением типа правой
части-(1)*/
TYPE nomber; /*числовым типом*/
'(',TYPE,')',e TYPE1 r;/*конструкцией вида
(тип)выражение_типа_отличного_от_типа_ле-
вой_части -(4)*/
'(',TYPE,')',TYPE1 nomber. /*конструкцией
вида ( тип) номер,имеющий тип,отличный от
типа левой части конструкции -(5) */
e TYPE r : e TYPE l,operation, e TYPE1 l;/* выражение
в правой части может быть представлен
типом, аналогичным типу левой части (2),
операцией - (3),выражением типа ,отличного
от типа левой части. */
TYPE : int symbol;/* в данном примере могут ис-
пользоваться данные цело-
численного или символьного
сhar symbol. типов */
Где :
е- expression -выражение,
TYPE- тип,
l- left -левый,
r- right - правый,
mod- modern -новый(англ.),тогда
e TYPE l -выражение, тип которого может встретиться в
левой части выражения,
e TYPE r -обозначает выражение , тип которого может
встретиться в правой части ( простое ) ,
e TYRE mod-обозначает выражение , тип которго может
встретиться в правой части ( составное или
простое, т.е., может быть состоять только
из выражения типа правой части или из приве-
денного к нему, или из суммы приведенной к
нужному типу и типа левой части переменных.
РАСПРЕДЕЛЕНИЕ ПАМЯТИ ВО ВРЕМЯ ТРАНСЛЯЦИИ
Похожие работы
... работы. В ходе работы над дипломным проектом разработан транслятор. Проблема создания такого транслятора является очень актуальной, т.к. многим пользователям САПР необходимо доступ к технической документацию, которую удобнее хранить на удаленных серверах в формате HTML. Поэтому степень положительного эффекта от выполнения дипломного проекта научно-исследовательского характера 1=6.5. В ...

... направления, активно развиваемого сейчас в разных коллективах и странах. Отталкиваясь от трансформационной модели смешанных вычислений и от своих работ в области трансляции и оптимизации программ, Ершов определяет концепцию трансформационной машины. Трансформационная машина есть абстрактное вычислительное устройство, выполняющее программы в некотором "сверхязыке", действиями которого являются ...
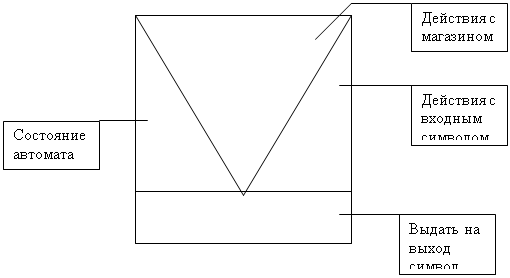
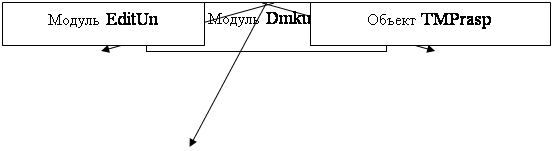
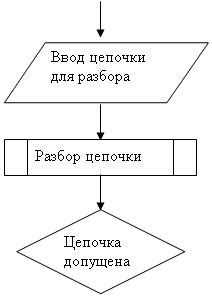

... 166, 16 Mb RAM, Windows 95 Вывод В ходе разработки курсового проекта я ближе ознакомился с теорией МП- трансляторов, научился писать программы - конструкторы для построения МП – транслятора по его параметрам с последующей проверкой задаваемых цепочек, закрепил знания по системному программированию. Разрабатывая программу, я научился применять знания дискретной математике, что облегчает ...
... позволяет связывать твёрдотельные модели, сборки или чертежи, созданные с помощью SolidWorks 97, с файлами других приложений, что значительно расширяет возможности автоматизации процесса проектирования. С помощью технологии OLE можно использовать информацию, полученную в других приложениях Windows, для управления моделями и чертежами SolidWorks. Например, размеры модели могут быть рассчитаны в ...
0 комментариев