Семестр: Отладка разработанного ПО и оформление протоко-
В строке ...SiSj... символы Si и Sj входят в одну и ту
В множество L(U) самых левых символов нетерминального
Пусть между некоторыми двумя символами Si и Sj сущес-
I i 1
Не предусмотрен выход при выполнении условия R > R , так как
Потом повторяется п. 5
Если выполнение шага 4 пpиведет к тому, что значения всех
Перевод инфиксной записи в польскую. Всякий раз, когда в
Когда редуцируется основа XY..Z, тетрады для всех нетер-
Опреанды и операторы
Если сканируемый символ - унарный оператор, то он приме-
А * В + С * D => *, A, B, T1 ┐ тетрады располагаются в
Устраняет недостатки программы,вызванные небрежностью или
Проверяется
непртиворечивость типов получателя и ис-
ДИСПЛЕЙ
Выделение памяти под рамку в процессе трансляции
ОРГАНИЗАЦИЯ ПАМЯТИ ВО ВРЕМЯ ТРАНСЛЯЦИИ
Алгоритм Биледи
Возможные параметры описания переменных и процедур
Навигация
Если выполнение шага 4 пpиведет к тому, что значения всех
Проектирование трансляторов
319724
знака
0
таблиц
0
изображений
5. Если выполнение шага 4 пpиведет к тому, что значения всех
атpибутов всех символов деpева окажутся вычисленными, то будем
называть полученное деpево завеpшенным. В пpотивном случае деpе-
во называется незавеpшенным.
ЛЕКЦИЯ 8
ЛЕКСИЧЕСКИЙ АНАЛИЗАТОР. АВТОМАТНЫЕ ГРАММАТИКИ.
РЕГУЛЯРНЫЕ ВЫРАЖЕНИЯ
Лексический анализатор (иногда также называемый сканером)
представляет собой наиболее простую часть компилятора. Лексичес-
кий анализатор просматривает литеры исходной программы слева нап-
раво и строит символы программы - целые числа, идентификаторы,
служебные слова и т.д. В литературе иногда вместо термина символ
используют термины элемент и атом. Символы передаются затем на
обработку фактическому анализатору. На этой стадии может быть ис-
ключен комментарий (именно такой путь исключения комментария был
избран в данном курсовом проекте). Лексический анализатор также
может заносить идентификаторы в таблицу символов, выполнять дру-
гую простую работу, которая фактически не требует анализа исход-
ной программы и может быть проделана на основе анализа отдельных
лексем. Он может выполнить большую часть работы по макрогенера-
ции в тех случаях, когда требуется только текстовая подстановка.
Обычно лексический анализатор передает символы синтакси-
ческому анализатору во внутренней форме. Каждый разделитель (слу-
жебное слово, знак операции или знак пунктуации) будет представ-
лен целым числом. Идентификаторы иликонстанты можно представить
парой чисел. Первое число, отличное от любого целого числа, ис-
пользуется для представления разделителя, характеризует сам "и-
дентификатор" или "константу"; второе число является адресом или
индексом идентификатора или константы в некоторой таблице. Это
позволяет в остальных частях компилятора работать эффективно,
оперируя с символами фиксированной длины, а не с цепочками литер
переменной длины.
Лексический анализатор по своему строению является конечным
автоматом. В этом пункте мы рассмотрим некторые проблемы, связан-
ные с реализацией конечного автомата или процессора как програм-
мы или подпрограммы для вычислительной машины. В этом пункте мы
рассмотрим три взаимосвязанных вопроса:
1. Как представлять выходы, состояния и переходы конечного
автомата, чтобы удовлетворить зачастую противоречивые требования,
предъявляемые к реализации: быстродействие и небольшие затраты
памяти.
2. Как справиться с некоторыми специфическими проблемами,
постоянно возникающими при компиляции.
3. Как расчленить задачу построения компилятора, чтобы полу-
чить автоматы, допускающие простую реализацию.
Некоторые задачи, решаемые с помощью конечных автоматов,
заключаются всего лишь в распознавании конечного множества слов.
Суть этих проблем в том, что компилятор должен обнаружить появле-
ние некоторого слова из такого множества и затем действовать в
зависимости от того, какое это слово. Задачи такого характера на-
зываются проблемой "идентификации", т.к. действия компилятора за-
висят от идентичности некоторому известному слову данного слова.
Так для решения задач идентификации может потребоваться огромное
число состояний, в подобных случаях часто приходится пользо-
ваться специальными методами реализации. По этой причине целесоб-
разно строить компилятор так, чтобы проблема идентификации реша-
лась отдельным подпроцессором, специально предназначенным для
этого.
Существуют проблемы идентификации, которые, строго говоря,
не могут быть решены с помощью конечного автомата. Например, час-
то встречающаяся проблема распознавания переменных или идентифи-
каторов некоторого языка. Решение этой проблемы обычным методом с
помощью конечного автомата потребует несколько состояний и нали-
чия элемента таблицы имен для каждого допустимого идентификатора.
Однако множество допустимых идентификаторов в большинстве языков
бесконечно или так велико, что его вполне можно считать бесконеч-
ным.
Понятно, что для языков, где число допустимых идентификато-
ров бесконечно или практически бесконечно, невозможно отвести
место в памяти или элемент таблицы имен для каждого возможного
идентификатора. Это затруднение преодолевается с помощью понятия
расширяющегося конечного автомата. При считывании своей входной
цепочки этот автомат отводит для идентификатора необходимое мес-
то в памяти и элемент в таблице, как только он впервые встречает-
ся в программе. Если этот идентификатор встречается в программе
снова, то, чтобы идентифицировать его, автомат использует техни-
ку идентификации слов с помощью конечного автомата. Когда появ-
ляется какой-тоновый идентификатор, автомат снова расширяется и
т.д.. Хотя этот автомат не является, строго говоря, конечным, к
нему применимы многие принципы построения и анализа конечных ав-
томатов.
Автоматные гpамматики
К сожалению, не все КС-гpамматики пpигодны для нисходящего
анализа МП-автоматов, так как для многих гpамматик множество всех
допустимых пpодолжений обpаботанной части входной цепочки не
всегда можно пpедставить единственной цепочкой теpминальных и не-
теpминальных символов. Рассмотpим такой класс гpамматик, для ко-
тоpых нисходящие МП-pаспознаватели можно постpоить - так называе-
мые автоматные гpамматики. (Фоpмальное опpеделение дано выше.)
Фактически контекстно-свободная гpамматика является автомат-
ной тогда и только тогда, когда выполняются следующие два условия:
1. Пpавая часть каждого пpавила начинается теpминалом.
2. Если два пpавила имеют совпадающие левые части, то пpа-
вые части этих пpавил должны начинаться pазличными теpминальными
символами. Для данной автоматной гpамматики МП-pаспознаватель с
одним состоянием задается следующим обpазом:
1. Множество входных символов - это множество теpминальных
символов, pасшиенное концевым маpкеpом.
2. Множество магазинных символов состоит из маpкеpа дна, не-
теpминальных символов и теpминалов, котоpые входят в пpавые час-
ти пpавил, кpоме занимающих кpайнюю левую позицию.
3. В начале магазин состоит из маpкеpа дна и начального не-
теpминала.
4. Упpавление pаботой МП-автомата с одним состоянием описы-
вается упpавляющей таблицей, стpоки котоpой помечены магазинными
символами, столбцы входными символами, а элементы описываются ни-
же.
5. Каждому пpавилу гpамматики сопоставляется элемент табли-
цы. Пpавило имеет вид <A> -> ba, где <A> - нетеpминал, b - теpми-
нал, а a - цепочка из теpминалов и нетеpминалов. Этому пpавилу
будет соответствовать элемент в стpоке <A> и столбце b
ЗАМЕНИТЬ (a'), СДВИГ
где a' - цепочка а, записанная в обpатном поpядке. Если
пpавило имеет вид <A> -> b, то вместо ЗАМЕНИТЬ (e) используется
ВЫТОЛКНУТЬ.
6. Если магазинным символом является теpминал b, то элемен-
том таблицы в стpоке b и столбце b будет ВЫТОЛКНУТЬ, СДВИГ.
7. Элементом таблицы, котоpый находится в стpоке маpкеpа дна
и столбце концевого маpкеpа, является ДОПУСТИТЬ.
8. Элементы таблицы, не описанные ни в одном из пунктов 5-7,
заполняются опеpацией ОТВЕРГНУТЬ.
Два огpаничения, наложенные нами на КС-гpамматики, гаpан-
тиpуют, что эти пpавила постpоения МП-автомата всегда будут pабо-
тать. Огpаничение 1 говоpит, что пpодукции гpамматики имеют тpе-
буемую фоpму, а огpаничение 2 нужно для того, чтобы пpи пpимене-
нии пpавила 5 элемент таблицы содеpжал только одну пpодукцию. Та-
ким обpазом, мы пpишли к заключению, что:
- если язык опpеделяется автоматной гpамматикой, то его мож-
но pаспознать с помощью МП-автомата с одним состоянием, ис-
пользующим pасшиpенную магазинную опеpацию ЗАМЕНИТЬ. Можно го-
воpить о тождественности автоматной гpамматики и МП-автомата,
постpоенного по ней.
ЛЕКЦИЯ 9
КРАТКИЕ СВЕДЕНИЯ О ГЕНЕРАТОРЕ ЛЕКСИЧЕСКИХ
АНАЛИЗАТОРОВ LEX
Лексический анализ - это распознавание лексем во входном
потоке символов. Предположим, что задано некоторое конечное мно-
жество слов (лексем) в некотором языке и некоторое входное
слово.Необходимо установить, какой элемент множества (если он су-
ществует) совпадает с данным входным словом.
Обычно лексический анализ выполняется так называемым лекси-
ческим анализатором. Применяется во многих случаях, например, для
построения пакетного редактора или в качестве распознавателя ди-
ректив в диалоговой программе и т.д. Наиболее важное применение
лексического анализатора - это использование его в компиляторе.
Здесь лексический анализатор выполняет функцию программы ввода
данных.
Лексический анализатор выполняет первую стадию компиляции -
читает строки компилируемой программы, выделяет лексемы и пере-
дает их на дальнейшие стадии компиляции (грамматический разбор,
кодогенерацию и т.д.).
Лексический анализатор распознает тип каждой лексемы и соот-
ветствующим образом помечает ее. Например, при компиляции
Си-программы могут быть выделены следующие типы лексем: число,
идентификатор, оператор, ограничитель и т.д.
Лексический анализатор должен не только выделить лексему, но
и выполнить некоторые преобразования. Например, если лексема
- число, то его необходимо перевести во внутреннюю (двоичную)
форму записи как число с плавающей или фиксированной точкой. А
если лексема - идентификатор, то его необходимо разместить в таб-
лице, чтобы в дальнейшем обращаться к нему не по имени, а по ад-
ресу в таблице.
Хотя лексический анализ по своей идее прост, тем не менее
эта фаза работы компилятора часто занимает больше времени, чем
любая другая. Частично это происходит из-за необходимости прос-
матривать и анализировать исходный текст символ за символом.
Иногда даже бывает необходимо вернуть прочитанный символ во вход-
ной поток с тем, чтобы повторить просмотр и анализ. Происходит
это потому, что часто бывает трудно определить, где проходят гра-
ницы лексемы. В тех случаях, когда выделение лексемы затруднено
либо по причине того, что одно регулярное выражение не позволяет
ее однозначно определить, либо из-за того, что лексема является
частью другой, приходится прибегать к контекстно-зависимым алго-
ритмам анализа с использованием левого и правого направлений
просмотра входной цепочки символов.
Lex - частично или полностью автоматизирует процесс написа-
ния программы лексического анализа. Lex - это программирующая
программа или генератор программ. Lex строит программу - лекси-
ческий анализатор на так называемом host-языке (или "главном"
языке). Это значит, что Lex-программа пишется на "языке" Lex, а
Lex-генератор, в свою очередь, генерирует программу лексического
анализа на каком-либо другом языке. Данная версия Lex генерирует
лексические анализаторы на языках Си и Ратфор (рациаональный диа-
лект Фортрана). В качестве host-языка мы будем использовать язык
Си.
Lex-программа имеет следующий формат:
определения %%
правила %%
подпрограммы, составленные пользователем
Любой из этих разделов может быть пустым. Простейшая
Lexпрограмма имеет вид:
%%
Здесь нет никаких определений и никаких правил. Правило сос-
тоит из двух частей:
РЕГУЛЯРНОЕ_ВЫРАЖЕНИЕ ДЕЙСТВИЕ
По регулярным выражениям, содержащимся в левой части правил,
Lex строит детерминированный конечный автомат. Этот автомат осу-
ществляет интерпретацию, а не компиляцию. Количество правил и их
сложность не влияют на скорость лексического анализа, если только
правила не требуют слишком большого об'ема повторных просмотров
входной последовательности символов. Однако, с ростом числа пра-
вил и их сложности растет размер конечного автомата, интерпрети-
рующего их и, следовательно, растет размер Си-программы, реали-
зующей этот конечный автомат. Lex всегда, если не указано другое,
строит выходной файл с именем lexyy.c - Си-программу - лексичес-
кий анализатор.
Если имеется необходимость получить файл с именем, отличным
от lexyy.c, то можно воспользоваться флагом "-t":
% lex -t source.l > file
По этому флагу результат поступает на стандартный вывод. Ре-
гулярные выражения в Lex-правилах определяют лексему. Они могут
содержать символы латинского и русского алфавитов в верхнем и
нижнем регистрах, другие символы (цифры, знаки препинания и
т.д.) и символы-операторы.
Операторы позволяют осуществлять различные действия над вы-
деленной цепочкой символов. Операторы также обозначаются символа-
ми.
Обозначения символов в выражениях. Можно использовать любой
символ. Символ можно указывать в двойных кавычках. В этом случае
это всегда просто символ - его специальное значение отменяется.
. - точка означает любой символ, кроме символа новой строки
"\n";
\восьмеричный_код_символа - указание символа его восьмерич-
ным кодом (как в языке Си);
\n - символ новой строки;
\t - символ табуляции;
\b - возврат курсора на один шаг назад;
Пробел - любой символ пробела в выражении, если он не нахо-
дится внутри квадратных скобок, необходимо заключать в двойные
кавычки. Это необходимо, так как пробел и табуляция используются
Lex в качестве разделителя между определением и действием в пра-
виле.
Операторы регулярных выражений
Операторы обозначаются символами-операторами, к ним относят-
ся:
\ ^ ? * + | $ / %
[] {} () <>
Каждый из этих символов или пар скобок в регулярном выраже-
нии играет роль оператора. Если необходимо отменить специальное
значение символа, обозначающего оператор, перед ним нужно поста-
вить символ "\" или указать его в двойных кавычках.
Оператор выделения классов символов.Квадратные скобки за-
дают классы символов, которые в них заключены.
[abc] означает либо символ "a", либо "b", либо символ "c";
Знак "-" используется для указания любого символа из лекси-
кографически упорядоченной последовательности: [A-z] означает лю-
бой латинский символ;
Повторители
Когда необходимо указать повторяемость вхождения символа в
регулярном выражении, используют операторы-повторители "*" и "+".
Оператор "*" означает любое (в том числе и 0) число вхожде-
ний символа или класса символов. Например: x* любое число вхожде-
ний символа "x"; Оператор "+" означает одно и более вхождений.
Например: x+ одно или более вхождений "x";
Операторы выбора
Операторы: / | ? $ ^ управляют процессом выбора символов.
Оператор "/": ab/cd "ab" учитывается только тогда, когда за
ним следует "cd".
Опeратор "|": ab|cd или "ab", или "cd".
Опeратор "?": x? означает необязательный символ "x".
_?[A-Za-z]* означает, что перед цепочкой любого количества
латинских букв может быть необязательный знак подчеркивания.
-?[0-9]+ выделит любое целое число с необязательным минусом
впереди.
Оператор "$": x$ означает выбрать символ "x", если он яв-
ляется последним в строке. Стоит перед символом "\n"! abc$ озна-
чает выбрать цепочку "abc", если она завершает строку.
Оператор "^": ^x означает выбрать символ "x", если он яв-
ляется первым символом строки; ^abc означает выбрать цепочку сим-
волов "abc", если она начинает строку. [^A-Z]* означает все сим-
волы, кроме прописных латинских букв. Когда символ "^" стоит пе-
ред выражением или внутри "[]", он выполняет операцию дополнение.
Внутри квадратных скобок символ "^" должен обязательно стоять
первым у открывающей скобки!
Оператор {} имеет два различных применения:
x{n,m} здесь n и m натуральные, m > n. Означает от n до m
вхождений x, например, x{2,7} - от 2 до 7 вхождений x;
{имя} вместо "{имя}" в данное место выражения будет подстав-
лено определение имени из области определений Lex-программы.
yytext - это внешний массив символов программы lex.yy.c,
которую строит Lex. yytext формируется в процессе чтения входно-
го файла и содержит текст, для которого установлено соответствие
какому-либо выражению. Этот массив доступен пользовательским раз-
делам Lex-программы.
Оператор <>. Служебные слова START и BEGIN
Раздел правил Lex-программы может содержать активные и неак-
тивные правила. Активные правила выполняются всегда. Неактивные
выполняются только в тех случаях, когда выполняется некоторое на-
чальное условие.
Начальные условия Lex-программы помещаются в раздел опреде-
лений, а неактивные правила помечаются соответствующими условия-
ми. Оператор Start позволяет указать список начальных условий
Lex-программы, а оператор BEGIN позволяет активировать правила,
помеченные начальными условиями.
Активные правила имеют следующий синтаксис:
РЕГУЛЯРНОЕ_ВЫРАЖЕНИЕ ДЕЙСТВИЕ
Неактивные правила имют следующий синтаксис:
<МЕТКА_УСЛОВИЯ>РЕГУЛЯРНОЕ_ВЫРАЖЕНИЕ ДЕЙСТВИЕ
ВАЖНО: любое правило должно начинаться с первой позиции
строки, пробелы и табуляции недопустимы - они используются как
разделители между регулярным выражением и действием в правиле.
Lex-программа может содержать несколько помеченных на-
чальных условий.
Каждое правило, перед которым указан оператор типа "<МЕТ-
КА>", мы будем называть помеченным правилом. Метка формируется
также как и метка в Си.
Количество помеченных правил не ограничивается. Кроме того,
разрешается одно правило помечать несколькими метками, например:
<МЕТКА1,МЕТКА2,МЕТКА3>x ДЕЙСТВИЕ
Запятая - обязательный разделитель списка меток !
Структура Lex-программы
Lex-программа включает разделы опредeлений, правил и пользо-
вательских программ. Рассмотрим подробнее способы оформления этих
разделов.
Все строки, в которых занята первая позиция, относятся к
Lex-программе. Любая строка, не являющаяся частью правила или
действия, которая начинается с пробела или табуляции, копируется
в сгенерированную программу lex.yy.c - результат работы Lex.
Раздел определений Lex-программы
Определения, предназначенные для Lex, помещаются перед пер-
вым %%. Любая строка этого раздела, не содержащаяся между %{ и %}
и начинающаяся в первой колонке, является определением строки
подстановки Lex. Раздел определений Lexпрограммы может включать:
- начальные условия;
- определения;
- фрагменты программы пользователя;
- таблицы наборов символов;
- указатели host-языка;
- изменения размеров внутренних массивов;
- комментарии в формате host-языка.
НАЧАЛЬНЫЕ УСЛОВИЯ задаются в форме:
%START имя1 имя2 ...
Если начальные условия определены, то эта строка должна быть
первой в Lex-программе.
ОПРЕДЕЛЕНИЯ задаются в форме:
имя трансляция
В качестве разделителя используется один или более пробелов
или табуляций. Имя - как обычно, любая последовательность букв и
цифр, начинающаяся с буквы. Трансляция - это регулярное выраже-
ние (или его часть), которое будет подставлено всюду там, где
указано имя (смотрите третью строку этого примера).
ФРАГМЕНТЫ ПРОГРАММЫ ПОЛЬЗОВАТЕЛЯ указываются двумя способами:
- в виде "пробел фрагмент";
- в виде %{ строки фрагмента программы пользователя %}
Такая форма включения пользовательского фрагмента необходи-
ма для ввода, например, макроопределений Си, которые должны начи-
наться в первой колонке строки. Все строки фрагмента пользова-
тельской программы, размещенные в разделе определений, будут яв-
ляться внешними для любой функции программы lex.yy.c
ТАБЛИЦА НАБОРОВ СИМВОЛОВ задается в виде:
%T
целое_число строка_символов
.........
целое_число строка_символов
%T
Сгенерированная программа lex.yy.c осуществляет ввод-вывод
символов посредством библиотечных функций Lex с именами input,
output, unput. Таким образом, Lex помещает в yytext символы в
представлении, используемом в этих библиотечных функциях. Для
внутреннего использования символ представляется целым числом,
значение которого образовано набором битов, представляющих сим-
вол в конкретной ЭВМ. Пользователю предоставляется возможность
менять представление символов (целых констант) с помощью таблицы
наборов символов. Если таблица символов присутствует в разделе
определений, то любой символ, появляющийся либо во входном пото-
ке, либо в правилах, должен быть определен в таблице символов.
Символам нельзя назначать число 0 и число, большее числа, выде-
ленного для внутреннего представления символов конкретной ЭВМ.
УКАЗАТЕЛЬ host-языка имеет вид:
%C для Си;
%R для Ратфора.
Если указатель host-языка отсутствует, то по умолчанию при-
нимается Си.
ИЗМЕНЕНИЯ РАЗМЕРА ВНУТРЕННИХ МАССИВОВ задаются в форме:
%x число
"число" - новый размер массива;
"x" - одна из букв p - позиции;
n - состояния;
e - узлы дерева;
a - упакованные переходы;
k - упакованные классы символов;
o - массив выходных элементов.
Lex имеет внутренние таблицы, размеры которых ограничены.
При построении программы лексического анализа может произойти пе-
реполнение любой из этих таблиц, о чем Lex сообщает при построе-
нии лексического анализатора. Пользователю предоставляется воз-
можность изменить размеры таблиц (сокращая размеры одних и увели-
чивая размеры других) таким образом, чтобы они не переполнялись.
Естественно, эти изменения возможны лишь в пределах той памяти,
которая выделяется под процесс.
Ниже перечислены размеры таблиц, которые устанавливаются по
умолчанию:
p - позиций 1500;
n - состояний 300;
e - узлов 600;
a - упакованных переходов 1500;
k - упакованных классов символов 1000;
o - выходных элементов 1500.
КОММЕНТАРИИ в разделе определений задаются в форме host-язы-
ка и должны начинаться не с первой колонки строки.
Раздел правил
Все, что указано после первой пары %% и до конца Lexпрограм-
мы или до второй пары %%, если она указана, относится к разделу
правил. Раздел правил может содержать правила и фрагменты прог-
рамм. Фрагменты программ, содержащиеся в разделе правил, стано-
вятся частью функции yylex файла lex.yy.c, в которой осущес-
твляется выполнение действий активных правил. Фрагмент прогрммы
указывается следующим образом:
%{ строки фрагмента программы %}
Раздел правил может включать список активных и неактивных
(помеченных) правил. Активные и неактивные правила могут быть
указаны в любом порядке, в том числе быть "перемешанными" в спис-
ке. Активные правила выполняются всегда, неактивные только по
ссылке на них оператором BEGIN.
Активное правило имеет вид:
ВЫРАЖЕНИЕ ДЕЙСТВИЕ
Неактивное правило имеет вид:
<МЕТКА>ВЫРАЖЕНИЕ ДЕЙСТВИЕ
или
<СПИСОК МЕТОК>ВЫРАЖЕНИЕ ДЕЙСТВИЕ
где СПИСОК_МЕТОК имеет вид:
метка1,метка2,...
В качестве первого правила раздела правил может быть прави-
ло вида:
BEGIN МЕТКА;
В этом правиле отсутствует ВЫРАЖЕНИЕ, и первым действием в
разделе правил будет активизация помеченных правил. Для возвраще-
ния автомата в исходное состояние можно использовать действие:
BEGIN 0;
Важно отметить следующее. Если Lex-программа содержит актив-
ные и неактивные правила, то активные правила работают всегда.
Оператор "BEGIN МЕТКА;" просто расширяет список активных правил,
активируя помеченные меткой МЕТКА. А оператор "BEGIN 0;" удаляет
из списка активных правил все помеченные правила, которые до это-
го были активированы. Кроме того, если из помеченного и активно-
го в данный момент времени правила осуществляется действие BEGIN
МЕТКА, то из помеченных правил активными останутся только те, ко-
торые помечены меткой МЕТКА.
Действия в правилах Lex-программы
Действие можно представлять либо как оператор Lex, например,
"BEGIN МЕТКА;", либо как оператор Си. Если имеется необходимость
выполнить достаточно большой набор преобразований, то действие
оформляют как блок Си-программы (он начинается открывающей фигур-
ной скобкой и завершается закрывающей фигурной скобкой), содержа-
щий необходимые фрагменты.
Действие в правиле указывается через не менее, чем один про-
бел или табуляцию после выражения (обязательно в той же строке,
где и выражение), а его продолжение может быть указано в следую-
щих строках только в том случае, если действие оформлено как блок
Си-программы.
Область действия переменных, об'явленных внутри блока, рас-
пространяется только на этот блок. Внешними переменными для всех
действий будут являться только те переменные, которые об'явлены в
разделе определений Lex-программы.
Действия в правилах Lex-программы выполняются, если правило
активно, и если автомат распознает цепочку символов из входного
потока как соответствующую регулярному выражению данного правила.
Однако, одно действие выполняется всегда - оно заключается в ко-
пировании входного потока символов в выходной. Это копирование
осуществляется для всех входных строк, которые не соответствуют
правилам, преобразующим эти строки. Комбинация символов, не уч-
тенная в правилах и появившаяся на входе, будет напечатана на вы-
ходе. Можно сказать, что действие - это то, что делается вместо
копирования входного потока символов на выход.
Когда необходимо вывести или преобразовать текст, соответ-
ствующий некоторому регулярному выражению, используется внешний
массив символов, который формирует Lex. Называется он yytext и
доступен в действиях правил. Например:
[A-Z]+ printf("%s",yytext);
По этому правилу распознается слово, содержащее прописные
латинские буквы и выводится с помощью printf, если оно выделено.
Операция вывода распознанного выражения используется очень часто,
поэтому имеется сокращенная форма записи этого действия: [A-Z]+
ECHO;
Результат действия этого правила будет аналогичен результа-
ту предыдущего примера. В выходном файле lex.yy.c ECHO определе-
но как макроподстановка:
#define ECHO fprintf(yyout, "%s",yytext);
Когда необходимо знать длину обнаруженной последовательнос-
ти символов, используется счетчик найденных символов yyleng, ко-
торый также доступен в действиях. Например:
[A-Z]+ printf("%c",yytext[yyleng-1]);
В этом примере будет выводится последний символ слова, соот-
ветствующего регулярному выражению [A-Z]+.
Рассмотрим еще один пример:
[A-Z]+ {число_слов++;число_букв += yyleng;}
Здесь ведется подсчет числа распознанных слов и количества
символов во всех словах.
Порядок действий активных правил
Список правил Lex-программы может содержать активные иеак-
тивные правила, размещенные в любом порядке в разделе правил. В
процессе работы лексического анализатора список активных правил
может видоизменяться за счет действий оператора BEGIN. В процес-
се распознавания символов входного потока может оказаться так,
что одна цепочка символов будет удовлетворять нескольким прави-
лам и, следовательно, возникает проблема: действие какого прави-
ла должно выполняться?
Для разрешения этого противоречия можно использовать кванто-
вание (разбиение) регулярных выражений этих правил Lex-программы
на такие новые регулярные выражения, которые дадут, по возможнос-
ти, однозначное распознавание лексемы. Однако, когда это не сде-
лано, Lex использует определенный детерминированный механизм раз-
решения такого противоречия:
- выбирается действие того правила, которое распознает наи-
более длинную последовательность символов из входного потока;
- если несколько правил распознают последовательности симво-
лов одной длины, то выполняется действие того правила, которое
записано первым в списке раздела правил Lex-программы.
Раздел программ пользователя
Все, что размещено за вторым набором %%, относится к разде-
лу программ пользователя. Содержимое этого раздела копируется в
выходной файл lex.yy.c без каких-либо изменений. В файле lex.
yy.c строки этого раздела рассматриваются как функции в смысле
Си. Эти функции могут вызываться в действиях правил и, как обыч-
но, передавать и возвращать значения аргументов.
Комментарии Lex-программы
Комментарии можно указывать во всех разделах Lex- программы.
Формат комментариев должен соответствовать формату комментариев
host-языка. Однако, в каждом разделе Lex- программы комментарии
указываются по разному. В разделе определений комментарии должны
начинаться не с первой позиции строки. В разделе правил коммента-
рии можно указывать только внутри блоков, принадлежащих дей-
ствиям. В разделе программ пользователя комментарии указываются
как и в host-языке.
Структура файла lexyy.c
Lex строит программу - лексический анализатор на языке Си,
которая размещается в файле со стандартным именем lex.yy.c. Эта
программа содержит две основных функции и несколько вспомога-
тельных. Основные - это:
функция yylex()
Она содержит разделы действий всех правил, которые определе-
ны пользователем;
функция yylook()
Она реализует детерминированный конечный автомат, который
осуществляет разбор входного потока символов в соответствии с ре-
гулярными выражениями правил Lex программы.
Вспомогательные функции, которые являются подпрограммами
ввода-вывода. К ним относятся:
input() - читает и возвращает символ из входного потока сим-
волов;
unput(c) - возвращает символ обратно во входной поток для
повторного чтения;
output(c) - выводит в выходной поток символ "c".
Эти функции можно изменить, указав им те же имена и размес-
тив в разделе программ пользователя.
Кроме того имеются функции yywrap(), reject(),yyless() и
yymore().
yywrap()
Используется для определения конца файла, из которого лекси-
ческий анализатор читает поток символов. Если yywrap возвращает
1, лексический анализатор прекращает работу. Однако, иногда
имеется необходимость начать ввод данных из другого источника и
продолжить работу. В этом случае пользователь должен написать
свою подпрограмму yywrap, которая организует новый входной поток
и возвращает 0, что служит сигналом к продолжению работы анализа-
тора. По умолчанию yywrap всегда возвращает 1 при завершению
входного потока символов.
В Lex-программе невозможно записать правило, которое будет
обнаруживать конец файла. Единственный способ это сделать - ис-
пользовать фунцию yywrap. Эта функция также удобна, когда необхо-
димо выполнить какие-либо действия по завершению входного потока
символов, определив в разделе программ пользователя новый ва-
риант функции yywrap.
REJECT
Обычно Lex разделяет входной поток, не осуществляя поиск
всех возможных соответствий каждому выражению. Это означает, что
каждый символ рассматривается один и только один раз. Иногда же-
лательно переопределить этот выбор. Действие функции REJECT озна-
чает "выбрать следующую альтернативу". Это приводит к тому, что
каким бы ни было правило, после него необходимо выполнить второй
выбор.
Функция REJECT полезна в том случае, когда она применяется
для определения всех вхождений какого-либо об'екта, причем вхож-
дения могут перекрываться или включать друг друга.
В обычной ситуации содержимое yytext обновляется всякий раз,
когда на входе появляется следующая строка. Напомним, что в
yytext всегда находятся символы распознанной последовательности.
Иногда возникает необходимость добавить к текущему содержимому
yytext следующую распознанную цепочку символов. Для этой цели ис-
пользуется функция yymore. Формат вызова этой функции:
yymore();
В некоторых случаях возникает необходимость использовать не
все символы распознанной последовательности в yytext, а только
необходимое их число. Для этой цели используется функция yyless.
Формат ее вызова:
yyless( n );
где n указывает, что в данный момент необходимы только n
символов строки в yytext. Остальные найденные символы будут воз-
вращены во входной поток.
Алгоритм лексического анализа
Данный алгоpитм является pасшиpенным индексным методом с
пpовеpкой пеpеходов и возвpатом ( теоpетический подход к этому
методу pешения был описан в пункте 2.1.1.).
ШАГ 1. Вычислить индекс начального сотояния (тек_сост).
ШАГ 2. Пpовеpить сушествует ли пеpеход из этого состояния по
какому либо символу или альтеpнативный пеpеход. Если не сущес-
твует, то пеpейти к ШАГУ 10.
ШАГ 3. Пpочитать один символ ( символ ).
ШАГ 4. Вычислить индекс элемента по введенному символу
тек_сост_1 = тек_сост + код_символа( символ ).
ШАГ 5. Пpовеpить индекс в таблице состояний. Если индекс
таблицы пеpеходов меньше нуля , то пеpейти к ШАГУ 8, если индекс
в таблице пеpеходов pавен нулю, то пеpейти к ША- ГУ 10. Иначе
пеpейти к ШАГУ 6.
ШАГ 6. Пpовеpить пpавильность пеpехода по таблице пеpехо-
дов. Если непpавильно, то пеpейти к ШАГУ 10. Иначе пеpейти ШАГУ 7.
ШАГ 7. Запомнить текущее состояние и введенный символ, ус-
тановить тек_сост в соответствии с таблицей пеpеходов. Пеpейти к
ШАГУ 2.
ШАГ 8. Изменить знак индекса таблицы пеpеходов и попы-
таться осуществить пеpеход как в ШАГАХ 4,6,7. Если попытка закон-
чилась удачно, то пеpейти к ШАГУ 2. Иначе пеpейти к ША- ГУ 9.
ШАГ 9. Если возможен пеpеход по алтеpнативе, то альтеpна-
тивное состояние сделать текущим и пеpейти к ШАГУ 4. В пpотивном
случае пеpейти к ШАГУ 10.
ШАГ 10. Веpнуть последний введенный символ в устpойство вво-
да.
ШАГ 11. Если достигнуто начальное состояние, то пpейти к
ШАГУ 13 в пpотивном случае пеpейти к шагу 12.
ШАГ 12. Если в текущее состояние пpинадлежит множеству воз-
можных конечных состояний, то в таблице конечных состояний уз-
нать номеp pаспознанной лексемы и закончить выполнение алгоpитма.
В пpотивном случае пеpейти в пpедыдущее состояние и пеpейти к
ШАГУ 10.
ШАГ 13. Закончить выполнение алгоpитма и выдать состояние
ошибки.
Данный алгоpитм позволяет стpоить лексический анализатоp,
котоpый получает поток сиволов со входного устpойства и pаспозна-
вая его тpанслиpует в паpы ( атpибут, значение ) для синтаксичес-
кого анализатоpа.
Пpиведем описание стpуктуp данных,пеpеменных и функций, ис-
пользующихся в пpогpамме.
Описание функций
Пpогpамма, постpоенная LEX, состоит из двух функций. Пеpвая
из них является непосpедственным исполнителем действий, пpедпи-
санных к выполнению после pаспознования лексемы.
Функция: INT LEXYY();
Вход: паpаметpы не пеpедаются.
Выход: возвpащает номеp pаспознанной лексемы или 0,если дос-
тигнут конец входного файла.
Реакция на ошибки: в случае, если входная последова-
тельность символов не pаспознана , то возвpащает -1.
Действие: функция pаспознает входную последовательность сим-
волов и пpеобpазует ее в паpы ( атpибут, значение ).
Напpимеp, часть пpогpаммы, написанной на языке LEX, после
генерации имеет следующий вид:
. . .
%%
. . .
"IF" return( if_perfix_symbol );
"THEN" return( if_then_symbol );
"ELSE" return( if_else_symbol );
. . .
%%
. . .
В пpоцедуpе LEXYY она может выглядеть следующим обpазом:
#include <stdio.h>
. . .
int lexyy()
{
int nsl;
. . .
nsl = yylook();
switch( nsl ) {
. . .
case 22: return( if_perfix_symbol );
break;
case 23:
return( if_then_symbol );
break;
case 24:
return( if_else_symbol );
break;
. . .
}
. . .
} /* Конец функции LEXYY */
. . .
/* Конец файла LEXYY.C */
Функция: int YYLOOK()
Вход: ни каких паpаметpов не пеpедается.
Выход: возвpашает номеp конечного состояния.
Обpаботка ошибок: если входная последовательность не pаспоз-
нана, то возвpащает -1.
Выполняемые действия: функция непосpедственно pеализующая
пеpеходы в автомате pаспознования входной последовательности.
Пpиведем усеченный ваpиант исходного текста (отсутствуют вызовы
пpоцедуp отладки). В текст вставим коментаpии.
/***********************************************************
Текст пpогpаммы YYLOOK(), pеализующей функции пеpеходов ко-
нечного автомата в pаспозновании лексем
***********************************************************/
yylook(){
register struct yysvf *yystate, **lsp;
register struct yywork *yyt;
struct yysvf *yyz;
int yych;
struct yywork *yyr;
char *yylastch;
for(;;){
/* Установить указатель стека состояний на начальное состояние */
lsp = yylstate;
/* ШАГ 1. Вычислить индекс начального сотояния (тек_сост) */
yyestate = yystate = yybgin;
/***********************************************************
Если был переход на новую строку, то начальное состоя-
ние смещается для обработки символа переход на новую строку
на одно состояние
***********************************************************/
if (yyprevious==YYNEWLINE) yystate++;
for (;;){
/***********************************************************
ШАГ 2. Пpовеpить сушествует ли пеpеход из этого состоя-
ния по какому либо символу или альтеpнативный пеpеход. Если
не существует, то пеpейти к ШАГУ 10
***********************************************************/
/* Получить адрес элемента таблицы переходов относи-
тельно которого вычисляются основные переходы по символам */
yyt = yystate->yystoff;
/* Если адрес равен адресу начала таблицы переходов, то
переходов нет и осуществляется проверка есть-ли переход по
альтернативному пути*/
if(yyt == yycrank){
/* Получить в табл.состояний адрес альтернативного пе-
рехода */
yyz = yystate->yyother;
/* Если альтернативный переход отсутствует ( т.е. адрес
равен нулю ),то прейти к ШАГУ 10 */
if(yyz == 0)break;
/* Если альтернативное состояние существует (т.е. адрес
не равен 0), то если из альтернативного перехода нет перехо-
да по таблице основных переходов, то прейти к ШАГУ 10 */
if(yyz->yystoff == yycrank)
break;
}
/***********************************************************
ШАГ 3. Пpочитать один символ ( символ )
***********************************************************/
/* input() является макроопределением, которое вводит
один символ из строки, если ранее были отвергнутые символы
или из входного файла
FILE *yyin={stdin}; в противном случае
yylstch - указывает на текущий символ кудаввести в
строке yytext для сохранения значения пары ( нетерминал,
значение ), если входная цепочка будет распознана как до-
пустимая */
*yylastch++ = yych = input();
/***********************************************************
ШАГ 4. Вычислить индекс элемента по введенному символу
( тек_сост_1 = тек_сост + код_символа( символ )
ШАГ 5. Пpовеpить индекс в таблице состояний, если ин-
декс таблицы пеpеходов меньше нуля , то пеpейти к ШАГУ 8,
если индекс в таблице пеpеходов pавен нулю, то пеpейти к ША-
ГУ 10 иначе пеpейти к ШАГУ 6.
***********************************************************/
tryagain:
/* Сохранить адрес таблицы переходов для текущего
состояния */
yyr = yyt;
/* Если адрес таблицы переходов для текущего состояния
больше адреса начала таблиц переходов, то прейти к ШАГУ 6 */
if ( (int)yyt > (int)yycrank){
/* Вычислить адрес нового элемента в таблице переходов
*/
yyt = yyr + yych;
/***********************************************************
ШАГ 6. Пpовеpить пpавильность пеpехода по таблице
пеpеходов. Если непpавильно то пеpейти к ШАГУ 10 иначе
пеpейти к ШАГУ 7.
***********************************************************/
/* if yyt <= yytop - если вычисленное состояние меньше
или pавно максимально допустимого номеpа состояния
if YYU( yyt ->verify)+yysvec == yystate если пеpеход,
котоpый пытаемся осуществить допустим из текущего состояния
*/
if (yyt<=yytop&&YYU(yyt->verify)+yysvec==yystate)
{
/* Если номеp состояния в котоpое мы пытаемся пеpейти
pавно YYERR = 0, то бнаpужен конец лекскмы и пеpейти к ШАГУ
10 */
if(yyt->advance == YYLERR)
{
/* unput(*--yylastch) - веpнуть последний символ во входной
файл */
unput(*--yylastch);
break;
}
/***********************************************************
ШАГ 7. Запомнить текущее состояние и введенный символ,
установить тек_сост в соответствии с таблицей пеpеходов и
пеpейти к ШАГУ 2.
***********************************************************/
/* state = YYU(yyt -> advance )+yysvec - по таблице
пеpеходов пеpейти в новое состояние автомата
*lsp++ = state - сохpанить в стеке состояний но-
вое состояние */
*lsp++ = yystate = YYU(yyt->advance)+yysvec;
/* Пеpейти к ШАГУ 2 */
goto contin;
} }
#ifdef YYOPTIM
/* следующая часть подключается только в случае,ели необходимо
обpабатывать ситуации [^S] return(symbol); если таких ситуаций
нет, то адpес таблицы пеpеходов меньше начального, то обpабаты-
вается, как отсутствие пеpеходов в автомате. */
else if((int)yyt < (int)yycr)
/***********************************************************
ШАГ 8. Изменить знак индекса таблицы пеpеходов и попы-
таться осуществить пеpеход как в ШАГАХ 4,6,7, если попытка закон-
чилась удачно, то пpейти к ШАГУ 2 иначе пеpейти к ШАГУ
9.
***********************************************************/
/* Изменить знак индекса в таблице пеpеходов */
yyt = yyr = yycrank+(yycrank-yyt);
/* Вычислить новый адpес в таблице пеpеходов */
yyt = yyt + yych;
/* if yyt <= yytop - если вычисленное состояние меньше
или pавно максимально допустимого номеpа состояния
if YYU( yyt ->verify)+yysvec == yystate
если пеpеход, котоpый пытаемся осуществить, допустим из
текущего состояния */
if(yyt <= yytop && YYU(yyt->verify)+yysvec == yystate)
{
/* Если номеp состояния в котоpое мы пытаемся пеpейти pавно
YYERR = 0, то бнаpужен конец лекскмы и пеpейти к ШАГУ
10 */
if(yyt->advance == YYLERR)
/* error transitions */
{unput(*--yylastch);break;}
/* state = YYU(yyt -> advance )+yysvec - по таблице
пеpеходов пеpейти в новое состояние автомата
*lsp++ = state - сохpанить в стеке состояний новое
состояние */
*lsp++ = yystate = YYU(yyt->advance)+yysvec;
/* Пеpейти к ШАГУ 2 */
goto contin;
}
/***********************************************************
ШАГ 9. Если возможен пеpеход по алтеpнативе, то аль-
теpнативное состояние сделать текущим и пеpейти к ШАГУ 4 в
пpотивном случае пеpейти к ШАГУ 10.
***********************************************************/
/* yystate = yystate -> yyoter - сделать состояние аль-
теpнативы текущим состоянием
yyt = yystate -> yystoff - плучить новый адpес таблицы
смещений
if ( state ) - если сушествует альтеpнативное состояние
то
if ( yyt != yycrank) - если из этого состояния
существует пpямой пеpеход */
if ((yystate = yystate->yyother) && (yyt =
yystate->yystoff) != yycrank){
/* Пеpейти к ШАГУ 4 */
goto tryagain;
}
#endif
else
{unput(*--yylastch);break;}
contin:
}
/* Конец обpаботки входного потока и начало пpовеpки
что это за лекскма */
/***********************************************************
ШАГ 10. Веpнуть последний введенный символ в устpойство
ввода.
ШАГ 11. Если достигнуто начальное состояние, то пpейти
к ШАГУ 13 в пpотивном случае пеpейти к шагу 12.
***********************************************************/
while (lsp-- > yylstate){
/* Удалить из yytext последний смвол и поставить пpиз-
нак конец стpоки */
*yylastch-- = 0;
/***********************************************************
ШАГ 12. Если в текущее состояние пpинадлежит множеству
возможных конечных состояний, то в таблице конечных состоя-
ний узнать номеp pаспознанной лексемы и закончить выполнение
алгоpитма. В пpотивном случае пеpейти в пpедыдущее состояние
и пеpейти к ШАГУ 10.
ШАГ 13. Закончить выполнение алгоpитма и выдать состоя-
ние ошибки.
***********************************************************/
/* Если номеp текущего состояния в стеке состояний не
нулевой и текущее состояние пpимнадлежит множеству конечных
состояний, то есть (*lsp)->yystop > 0 */
if (*lsp != 0 && (yyfnd= (*lsp)->yystops) && *yyfnd > 0){
/* Сохpанить значения в глобальных пеpеменных */
yyolsp = lsp;
yyprevious = YYU(*yylastch);
yylsp = lsp;
yyleng = yylastch-yytext+1;
/* Установить пpизнак конца стpоки в yytext */
yytext[yyleng] = 0;
/* Возвpатить номеp pаспознанной лексемы */
return(*yyfnd++);
}
/* если лексема не pаспознана, то веpнуть символ вов-
ходной поток */
unput(*yylastch);
}
/* если достигнут конец файла, то веpнуть 0 */
if (yytext[0] == 0 /* && feof(yyin) */)
{
yysptr=yysbuf;
return(0);
}
yyprevious = yytext[0] = input();
if (yyprevious>0)
output(yyprevious);
yylastch=yytext;
}
}
ЛЕКЦИЯ 10
КРАТКИЕ СВЕДЕНИЯ О ГЕНЕРАТОРЕ СИНТАКСИЧЕСКИХ
АНАЛИЗАТОРОВ YACC
Значительная часть создаваемых программ, рассчитанных на оп-
ределенную структуру входной информации, явно или неявно вклю-
чает в себя некоторую процедуру синтаксического анализа. В зада-
чах, где пользователю при задании входной информации предостав-
ляется относительная свобода (в отношении сочетания и последова-
тельности структурных элементов), синтаксический анализ достаточ-
но сложен. При решении подобных задач существенную поддержку мо-
гут оказать сервисные программы, осуществляющие построение син-
таксических (грамматических) анализаторов на основе заданных све-
дений о синтаксической структуре входной информации. YACC отно-
сится к числу этих сервисных программ - генераторов грамматичес-
ких анализаторов.
Поскольку обширной областью, где наиболее явно видна необхо-
димость (нетривиального) грамматического анализа, а следова-
тельно и его автоматизации, является область создания транслято-
ров (в частности, компиляторов), программы, подобные YACC, полу-
чили еще название компиляторов (или генераторов) компиляторов.
Заметим, что понятие транслятора может относиться не только
к языкам программирования, но и к командным языкам, входным язы-
кам любых диалоговых систем, языкам управления технологическими
процессами и т.п.
Пользователь YACC должен описать структуру своей входной ин-
формации (ГРАММАТИКУ) как набор ПРАВИЛ в виде, близком к Бэкусо-
во-Науровской форме (БНФ). Каждое правило описывает грамматичес-
кую конструкцию, называемую НЕТЕРМИНАЛЬНЫМ СИМВО- ЛОМ, и сопос-
тавляет ей имя. С точки зрения грамматического разбора правила
рассматриваются как правила вывода (подстановки). Грамматические
правила описываются в терминах некоторых исходных конструкций,
которые называются лексическими единицами, или ЛЕКСЕМАМИ. Имеет-
ся возможность задавать лексемы непосредственно (литерально) или
употреблять в грамматических правилах имя лексемы. Как правило,
имена сопоставляются лексемам, соответствующим классам об'ектов,
конкретное значение которых не существенно для целей грамматичес-
кого анализа. (Иногда в литературе с понятием лексемы совпадает
понятие терминального символа; однако, ряд авторов называет тер-
минальными символами отдельные символы стандартного набора). При-
мерами имен лексем могут служить "ИДЕНТИФИ- КАТОР" и "ЧИСЛО", а
введение таких лексем позволяет обобщить конкретные способы запи-
си идентификаторов и чисел. В некоторых случаях имена лексем слу-
жат для придания правилам большей выразительности.
Лексемы должны распознаваться программой лексического анали-
за, определяемой пользователем. Пользователь же предварительно
выбирает конструкции,которые более удобно и эффективно распозна-
вать непосредственно, и в соответствии с этим об'являет имена
лексем. Пользовательская программа лексического анализа -
ЛЕКСИЧЕСКИЙ АНАЛИЗАТОР - осуществляет чтение реальной входной ин-
формации и передает грамматическому анализатору распознанные лек-
семы.
Как уже отмечалось, YACC обеспечивает автоматическое пос-
троение лишь процедуры грамматического анализа. Однако, действия
по обработке входной информации обычно должны выполняться по ме-
ре распознавания на входе тех или иных допустимых грамматических
конструкций. Поэтому наряду с заданием грамматики входных тек-
стов YACC предусматривает воможность описания для отдельных кон-
струкций семантических про-
цедур (ДЕЙСТВИЙ) с тем, чтобы они были включены в программу грам-
матического разбора. В зависимости от характера пользовательских
семантических процедур (интерпретация распознанного фрагмента
входного текста, генерация фрагмента об'ектного кода, отметка в
справочной таблице или форматирование вершины в дереве разбора)
генерируемая с помощью YACC программа будет обеспечивать кроме
анализа тот или иной вид обработки входного текста, в частности,
его компиляцию или интерпретацию.
Итак, пользователь YACC подготавливает общее описание
(СПЕЦИФИКАЦИИ) обработки входного потока, включающее правила,
описывающие входные конструкции, кодовую часть, к которой должно
быть организовано обращение при обнаружении этих конструкций, и
программу ввода базовых элементов потока (лексический
анализатор). Kомпилятор компиляторов обеспечивает создание под-
программы (грамматического анализатора), реализующей процедуру
обработки входного потока в соответствии с заданными специфика-
циями.
К компонентам компилятора компиляторов относятся выполняе-
мый файл yacc, библиотека стандартных программ /lib/liby.a, Файл
/usr/lib/yaccpar. Заключительная фаза построения компилятора тре-
бует применения компилятора языка Си.
ПРИНЦИПЫ РАБОТЫ YACC
Грамматические анализаторы, создаваемые с помощью YACC, реа-
лизуют так называемый LALR(1)-разбор, являющийся модификацией од-
ного из основных методов разбора "снизу вверх" - LR(k)-разбора
(буквы L(eft) и R(ight) в обоих сокращениях означают соответ-
ственно чтение входных символов слева направо и использование
правостороннего вывода. Индекс в скобках показывает число предва-
рительно просматриваемых лексических единиц).
Любой разбор по принципу "снизу вверх" (или восходящий раз-
бор) состоит в попытке приведения всей совокупности входных дан-
ных (входной цепочки) к так называемому "начальному символу грам-
матики" путем последовательного применения правил вывода.
В каждый момент грамматического разбора анализатор находит-
ся в некотором СОСТОЯНИИ, определяемом предысторией разбора, и в
зависимости от очередной лексемы предпринимает то или иное дей-
ствие для перехода к новому состоянию. Различают два типа дей-
ствий: "СДВИГ", т.е. чтение следующей входной лексемы, и
"СВЕРТКУ", т.е. применение одного из правил подстановки для заме-
щения нетерминалом последовательности символов, соответствующей
правой части правила. Работа YACC по генерации процедуры грамма-
тического анализа заключается в построении таблиц, которые для
каждого из состояний определяют тип действий анализатора и номер
следующего состояния в соответствии с каждой из входных лексем.
Любой метод разбора требует грамматик с определенными свой-
ствами. В этом смысле YACC предполагает контекстносвободные грам-
матики со свойствами LALR(1). LALR(1)- грамматики, являясь под-
множеством LR(1)-грамматик, допускают при построении таблиц раз-
бора сокращение общего числа состояний за счет об'единения иден-
тичных состояний, различающихся только набором символов-следова-
телей (символов, которые могут следовать после применения одного
из правил вывода, если разбор по этому правилу проходил через
данное состояние). Другие грамматики являются неоднозначными для
принятого в YACC метода разбора и вызовут конфликты.
Однако, если язык, описываемый данной грамматикой, в принци-
пе допускает задание грамматики, однозначной для данного метода
разбора, то YACC позволяет без перестройки грамматики построить
грамматический анализатор, разрешающий конфликты на основе меха-
низма приоритетов.
ВХОДНЫЕ И ВЫХОДНЫЕ ФАЙЛЫ, СТРУКТУРА
ГРАММАТИЧЕСКОГО АНАЛИЗАТОРА
Входная информация для YACC задается в СПЕЦИФИКАЦИОННОМ
ФАЙЛЕ. На выходе компилятора компиляторов в результате обработки
спецификаций создается файл y.tab.c с исходным текстом Сипроце-
дур, составляющих грамматический анализатор. Основной в файле
y.tab.c является процедура yyparse, реализующая алгоритм грамма-
тического разбора. При формировании ее YACC использует файл
/usr/lib/yaccpar, содержащий неизменяемую часть анализатора. Кро-
ме yyparse, в файл y.tab.c YACC включает построенные им таблицы
разбора, описания и программные фрагменты пользовательских специ-
фикаций.
Процедура yyparse представляет собой целочисленную функцию,
возвращающую значение 0 или 1. Значение 0 возвращается в случае
успешного разбора по достижении признака конца файла, значение 1-
в случае несоответствия входного текста заданным спецификациям.
Процедура yyparse содержит многократное обращение к процедуре
лексического анализа yylex, текст которой либо переносится в файл
y.tab.c из спецификационного файла, либо прикомпоновывается впос-
ледствии.
Для организации обращения к процедуре yyparse в библиотеке
YACC существует стандартная процедура main, не содержащая помимо
обращения к yyparse никаких действий. Пользователь может напи-
сать собственную процедуру main, включив в нее как начальные дей-
ствия, предваряющие вызов yyparse (установка нужных режимов, от-
крытие файлов, частичное заполнение таблиц), так и действия по
завершении разбора, которым должен предшествовать анализ возвра-
щаемого yyparse значения; действиями в случае успешного разбора
могут быть закрытие файлов, вывод результатов, вызов следующей
фазы транслятора, в частности, повторный вызов yyparse. Для заме-
ны стандартной процедуры пользовательской программой main она
должна быть описана в спецификационном файле или присоединена на
этапе вызова Си-компилятора для подготовки исполняемой программы.
Кроме выходного файла y.tab.c, YACC может дополнительно гене-
рировать следующие выходные файлы:
y.output содержащий описание состояний анализатора и сообще-
ния о конфликтах;
y.tab.h содержащий описание лексем.
Для генерации этих файлов требуется задание соответствующих
флагов при вызове YACC.
ПРОЦЕДУРА ПОСТРОЕНИЯ ГРАММАТИЧЕСКОГО АНАЛИЗАТОРА
Построение грамматического анализатора осуществляется в два
этапа. На первом этапе файл спецификаций входного языка обрабаты-
вается компилятором компиляторов YACC, для чего задается коман-
дная строка yacc [-vd] yfile. Здесь yfile - имя файла специфика-
ций, а флаги имеют следующий смысл: v - сформировать в файле
y.output подробное описание грамматического анализатора; d -
сформировать в файле y.tab.h описание лексем.
Текстовые файлы y.output и y.tab.h содержат справочную ин-
формацию для пользователя, и никак не используются на втором эта-
пе построения грамматического анализатора. Основной результат ра-
боты YACC - процедура yyparse и грамматические таблицы - поме-
щается в файл y.tab.c. На втором этапе построения грамматическо-
го анализатора для получения в файле a.out исполняемой программы
компилируется файл y.tab.c и присоединяются другие программные
компоненты:
cc y.tab.c [cfile...ofile...lfile...] -ly
где cfile, ofile,lfile - имена исходных, объектных и библио-
течных файлов, содержащих присоединяемые процедуры. В этот спи-
сок не включается имя стандартной библиотеки YACC /lib/liby.a, ее
подключение обеспечивается заданием флага ly. Этот флаг полезно
считать обязательным.
ЗАДАНИЕ ВХОДНОЙ ИНФОРМАЦИИ YACC
Структура спецификационного файла
Пользовательские спецификации, задающие правила организации
входной информации и алгоритм ее обработки, об'единяются в специ-
фикационный файл следующей структуры:
декларации
%%
правила
%%
программы
Ядром спецификационного файла и единственной его обяза-
тельной частью является секция правил. При отсутсивии секции
программ может быть опущена вторая группа "%%"; следовательно,
минимальная допустимая конфигурация входного файла имеет вид:
%%
правила
Пробелы, знаки табуляции и перевода строки игнорируются, не-
допустимо лишь появление их в именах. Комментарий, ограниченный
символами "/*" в начале и "*/" в конце, может находиться между
любыми двумя разделителями в любой секции входного файла.
СЕКЦИЯ ПРАВИЛ состоит из одного или нескольких грамматичес-
ких правил. Эти правила должны определять все допустимые входные
конструкции и связанные с определенными конструкциями действия по
обработке входного потока.
Назначение СЕКЦИИ ДЕКЛАРАЦИИ состоит в основном в задании
информации о лексемах.
СЕКЦИЯ ПРОГРАММ представляет собой некоторый набор процедур
на языке Си, которые должны включаться в текст программы грамма-
тического разбора. Например, это могут быть процедура лексическо-
го анализа yylex и пользовательские процедуры, вызываемые в дей-
ствиях.
СЕКЦИЯ ПРАВИЛ. В данной секции с помощью набора грамматичес-
ких правил должны быть определены все конструкции, из которых
впоследствии будут строиться входные тексты. Не подлежат опреде-
лению в секции правил лишь конструкЦии, выбранные пользователем в
качестве лексем, считающиеся для грамматического анализа исходны-
ми единицами. Правила задаются в форме, близкой БНФ.
Правило, определяющее синтаксический вид конструкции, за-
дается таким образом: <имя нетерминального символа>: определение;
здесь ':' и ';' специальные символы YACC. Правая часть правила -
определение - представляет собой упорядоченную последова-
тельность элементов (нетерминальных символов и лексем), состав-
ляющих описываемую конструкцию. При грамматическом разборе такая
последовательность в результате применения правила заменяется не-
терминальным символом, имя которого указано в левой части. нетер-
минальные символы в определении задаются именами, а лексемы -
именами или литералами. Запись имен и литералов совпадает с за-
писью идентификаторов и символьных констант, принятой в Си.
По виду правила нельзя заключить, относятся эти имена к лек-
семам или нетерминальным символам. YACC считает именами нетерми-
налов все имена, не объявленные в секции деклараций именами лек-
сем. Все нетерминалы должны быть определены, т.е. имя каждого из
них должно появиться в левой части хотя бы одного правила. Допус-
тимо задание нескольких правил, определяющих один нетерминальный
символ, т.е. правил с одинаковой левой частью. Такие правила оп-
ределяют конструкции, идентичные на некотором уровне.
Правила с общей левой частью можно задавать в сокращенной
записи, без повторения левой части, используя для разделения
альтернативных определений символ "|".
При необходимости с любым правилом можно связать действие -
набор операторов языка Си, которые будут выполняться при каждом
распознавании конструкции во входном тексте. Действие не являет-
ся обязательным элементом правил.
Действие заключается в фигурные скобки и помещается вслед за
правой частью правила, т.е. правило с действием имеет вид:
<имя нетерминального символа>: определение {действие};
Точка с запятой после правила с действием может опускаться.
При использовании сокращенной записи правил с общей левой частью
следует иметь в виду, что действие может относиться только к от-
дельному правилу, а не к их совокупности. Следующий пример иллюс-
трирует задание действий в случае правил с общей левой частью.
На операторы, входящие в действия, не накладывается никаких
ограничений. В частности, в действиях могут содержаться вызовы
любых функций. Отдельные операторы могут быть помечены, к ним
возможен переход из других действий.
Существует возможность задания действий, которые будут вы-
полняться по мере распознавания отдельных фрагментов правила.
Действие в этом случае помещается после одного из элементов пра-
вой части так, чтобы положение действия соотвествовало моменту
разбора, в который данному действию будет передано управление.
Для того, чтобы действия имели реальный смысл, они, как пра-
вило, должны использовать некоторые общие переменные,
т.е. переменные, доступные во всех действиях и сохраняющие свои
значения по окончании очередного действия. Такие переменные опи-
сываются в начале секции правил, все описание ограничивается с
двух сторон строками
%{
и %}
Здесь же могут находиться произвольные операторы Си, рас-
сматриваемые как общие действия для всех правил.
Укажем еще на два вида объектов, использующихся в действиях.
Это, во-первых, глобальные переменные, которые описываются в сек-
ции деклараций , и, во-вторых, специальные переменные (псевдопе-
ременные),облегчающие взаимосвязь между действиями и связь их с
лексическим анализатором.Структура входной информации описывает-
ся в наборе правил иерархически, т.е. каждое правило соответ-
ствует определенному уровню структурного разбиения. Однако, пос-
ледовательность задания правил может не отражать этой иерархии и
быть вполне произвольной. Единственно необходимой для YACC яв-
ляется информация о том, какой из нетерминалов задает вершину ие-
рархии, т.е. соотвествует конструкциям, определяющим входной
текст в целом. Этот нетерминал принято называть НАЧАЛЬНЫМ
СИМВОЛОМ. Приведение входного текста к начальному символу являет-
ся целью грамматического анализатора. По умолчанию YACC считает
начальным символом тот нетерминал, имя которого стоит в левой
части первого из правил. Однако, если определять начальный сим-
вол в первом правиле пользователю неудобно, он может явно задать
имя начального символа в секции деклараций.
Существует два специфических вида правил, на которые полез-
но обратить внимание. Во-первых, это пустое правило вида
<имя нетерминального символа>: ;
определяющее пустую последовательность символов. Сочетание
пустого правила с другими правилами, определяющими тот же нетер-
минальный символ, является одним из способов указать на необяза-
тельность вхождения соответствующей конструкции. Например, сово-
купность правил
целое_число:знак целое_без_знака; знак: | '+'|'-';
определяет возможность задания целых чисел со знаком и без
него. Другой способ описать эту возможность состоит в задании
следующей группы правил:
целое_число:знак целое_без_знака | целое_без_знака ; знак:
'+'|'-';
С пустым правилом может быть обычным образом связано дей-
ствие:
ИМЯ: {тело_действия} ;
Во-вторых, правила часто описывают некоторую конструкцию ре-
курсивно, т.е. правая часть может рекурсивно включать определяе-
мый нетерминальный символ. Различают леворекурсивные правила вида:
<имя нетерминала>:<имя нетерминала> <многократно повто-
ряемый фрагмент>;
и праворекурсивные вида
<имя нетерминала>: <многократно повторяемый фрагмент>
<имя нетерминала>;
YACC допускает оба вида рекурсивных правил, однако, при ис-
пользовании правил с правой рекурсией об'ем анализатора увеличи-
вается, а во время разбора возможно переполнение внутреннего сте-
ка анализатора.
Рекурсивные правила необходимы при задании последовательнос-
тей и списков. Следующие примеры иллюстрируют универсальный спо-
соб описания этих конструкций:
последовательность: элемент
| последовательность элемент;
список: элемент | список ',' элемент;
Заметим, что в каждом из этих случаев первое правило (не со-
держащее рекурсии) будет применено только для первого элемента, а
второе (рекурсивное) - для всех последующих. Нетерминальные сим-
волы, связанные с последовательностями или списками разнородных
элементов, могут описываться произвольным числом рекурсивных и
нерекурсивных правил. Например, группа правил
идентификатор: буква |
'$' |
идентификатор буква |
идентификатор цифра |
идентификатор '_' ;
описывает идентификатор как последовательность букв, цифр и
символов "_", начинающуюся с буквы или символа "$". Следует обра-
тить внимание на то, что рекурсивные правила не имеют смысла, ес-
ли для определяемого ими нетерминала не задано ни одного правила
без рекурсии. Для обеспечения возможности задания пустых списков
или последовательностей в качестве нерекурсивного правила ис-
пользуется пустое:
последовательность : | последовательность элемент ;
Сочетание пустых и рекурсивных правил является удобным спо-
собом представления грамматик и ведет к большей их общности, од-
нако,некорректное использование пустых правил может вызывать кон-
фликтные ситуации (раздел 5) из-за неоднозначности выбора нетер-
минала, соответствующего пустой последовательности.
Секция деклараций состоит из последовательности строк двух
видов: строк-директив и строк исходного текста.
Строки исходного текста без изменений копируются в выходной
файл y.tab.c и могут содержать операторы препроцессора и описа-
ние внешних об'ектов. Область действия переменных, описанных в
секции деклараций, распространяется на весь спецификационный
файл, т.е. они доступны как в операторах действий, так и в проце-
дурах, находящихся в секции программ.
Строки-директивы начинаются символом "%" (этот символ в YACC
играет роль своего рода esc-символа). Две специальные директивы
%{ и %} ограничивают с двух сторон группы строк исходного текста.
Остальные директивы служат для задания дополнительной информации
о грамматике.
ДЕКЛАРАЦИЯ ИМЕН ЛЕКСЕМ
%token <список имен лексем>
Пользователь при описании грамматики решает, какие конструк-
ции целесообразнее непосредственно выделять из входного текста на
этапе лексического анализа, и на уровне этих конструкций (лексем)
задает грамматические правила. Все виды лексем, кроме литералов,
обозначаются некоторыми именами и под этими именами фигурируют в
секции правил. Благодаря декларации имен лексем в директиве
%token YACC отличает имена лексем от имен нетерминальных симво-
лов. Однако, декларация ни в коей мере не обеспечивает распозна-
вания лексем, и пользователю рекомендуется считать для себя ди-
рективу %token напоминанием о необходимости построения лексичес-
кого анализатора и руководствоваться этой директивой при его на-
писании.
Заметим, что ключевые слова описываемого входного языка час-
то бывает удобно считать лексемами. Имена лексем могут совпадать
с этими ключевыми словами, недопустимым является лишь совпадение
имен лексем с зарезервированными словами языка Си.
ДЕКЛАРАЦИЯ ПРИОРИТЕТОВ И АССОЦИАТИВНОСТИ ЛЕКСЕМ
%left <список лексем>
%right <список лексем>
%nonassos <список лексем>
Лексемы в данных директивах задаются литералами или именами.
В последнем случае декларация приоритета заменяет также деклара-
цию имени лексемы, хотя в целях обеспечения наглядности описания
является желательным присутствие в списке директивы %token всего
набора имен лексем.
Использование лексемы само по себе не требует задания ее
приоритета или ассоциативности.
При вызове YACC с флагом -d последовательность операторов
#define помещается также в информационный файл y.tab.h.
Переопределив при необходимости ряд номеров типов лек-
сем,пользователь должен проверить уникальность номеров у всех ис-
пользуемых лексем.
ДЕКЛАРАЦИЯ ИМЕНИ НАЧАЛЬНОГО СИМВОЛА
%start <имя начального символа>
Директива отменяет действующий по умолчанию выбор в качес-
тве начального символа нетериминала, определяемого первым грамма-
тическим правилом.
Секция программ-процедуры, которые должны быть включены в
генерируемую программу грамматического анализа. Любая из опреде-
ляемых пользователем программных компонент может находиться в
секции программ спецификационного файла, либо присоединяться на
этапе вызова Си-компилятора для трансляции файла y.tab.c и компо-
новки выходной программы. Перечислим процедуры, которые одним из
этих способов должны быть заданы:
- лексический анализатор - функция с именем yylex();
- все процедуры, вызовы которых содержатся в действиях, свя-
занных с грамматическими правилами;
- главная процедура main() при необходимости заменить ее
стандартный библиотечный вариант, который имеет вид:
main() { return (yyparse(); }
- процедура обработки ошибок yyerror() - также для замены
библиотечного варианта (его текст приводится ниже).
#include <stdio.h>
yyerror(s)char *s; { fprintf(stderr, "%s0, s);}
Для обеспечения корректной работы грамматического анализато-
ра функция лексического анализа yylex должна быть согласована с
конкретной спецификацией грамматики и удовлетворять определенным
требованиям. Основная задача функции yylex состоит во вводе из
входного потока ряда очередных символов до выявления конструкции,
соответствующей одной из лексем, и возвращении номера типа этой
лексемы. Для нелитеральных лексем номером типа может служить
об'явленное в секции деклараций имя лексемы (с помощью механизма
#define YACC обеспечивает замену его нужным номером), в случае
литералов номером типа является числовое значение символа (если
оно не было переопределено). Алгоритм поиска должен заключаться в
попытке нахождения сначала более сложных (нелитеральных) лексем и
лишь при несовпадении ни с одной из них текущих элементов ввода
возвращать номер типа литеральной лексемы (любой однозначный сим-
вол, не начинающий ни одну из возможных лексем, сам образует лек-
сему).
Действия с использованием псевдопеременных.Для обеспечения
связи между действиями, а также между действиями и лексическим
анализатором создаваемые YACC грамматические анализаторы поддер-
живают специальный стек, в котором сохраняются значения лексем и
нетерминальных символов. Значение лексемы автоматически попадает
в стек после ее распознавания лексическим анализатором (напомним,
что им считается текущее значение переменной yylval). После каж-
дой свертки вычисляется значение нетерминала, заместившего свер-
нутую строку, и помещается в вершину стека; значения элементов
правой части примененного правила перед этим выталкиваются из
стека. Заметим, что таким образом к моменту свертки любого прави-
ла все значения нетериналов в правой части оказываются вычислен-
ными в результате сверток. Способ вычисления значения нетермина-
ла будет рассмотрен ниже.
Описанный механизм не требует вмешательства пользователя и
предоставляет ему следующие возможности:
- Использовать в действиях, осуществляемых после свертки по
правилу, значение любого элемента его правой части. Доступ к этим
значениям обеспечивается набором так называемых ПСЕВДОПЕРЕМЕННЫХ
с именами $1,$2,..., где $i соответствует значению i-го элемента;
элементы правой части правила нумеруются слева направо без разли-
чия лексем и нетерминальных символов;
- Формировать в действиях значение, образованного в ре-
зультате свертки нетерминала путем присвоения этого значения
псевдопеременной с именем $$. Eсли в действии не определяется
значение переменной $$ (а также если действие отсутствует), зна-
чением нетерминала после свертки по умолчанию становится значе-
ние первого элемента правой части, т.е. неявно выполняется прис-
ваивание.
Несколько иная ситуация в отношении использования псевдопе-
ременных имеет место для правил, содержащих действия внутри пра-
вой части. На самом деле YACC интерпретирует правило вида
A: B C {действие 1} D {действие 2} K
как
A: B C EMPTY1 D EMPTY2 K;
EMPTY1: {действие 1}
EMPTY2: {действие 2}
и в точке, где вставлено действие, при разборе осуществляет-
ся свертка по пустому правилу, сопровождающаяся выполнением ука-
занного действия. При этом независимо от характера действия оче-
редной элемент в стеке значений отводится для хранения значения
неявно присутствующего "пустого" нетерминала. В действии, находя-
щемся в конце правила, соглашение о значениях псевдопеременных
остается прежним, если иметь в виду наличие дополнительных симво-
лов. В приведенном выше правиле в действии 3 для доступа к значе-
ниям элементов B, C, D, K следовало бы использовать соответствен-
но псевдопеременные $1, $2, $4, $6; псевдоперемнные $3, $5 хра-
нят результаты действий 1 и 2. В действиях, находящихся внутри
правила, с помощью псевдоперемнных $i доступны значения располо-
женных левее элементов, а также результаты предшествующих встав-
ленных в тело действий. Результатом внутреннего действия (т.е.
значением неявного нетерминалА) является значение, присвоенное в
этом действии псевдопеременной $$, при отсутствии такого присваи-
вания результат действия не определен. Заметим, что присваивание
значения псевдопеременной $$ во внутренних действиях не вызывает
предварительной установки значения нетерминала, стоящего в левой
части правила: это значение в любом случае устанавливется только
действием в конце правила или считается равным значению $1.
ЛЕКЦИЯ 11
СЕМАНТИЧЕСКИЕ ПРОГРАММЫ
Генерация какого─либо промежуточного кода большей частью
осуществляется одновременно с синтаксическим анализом. С этой
целью включаются действия, вызов которых обеспечивает не только
генерацию кода, но и построение таблиц символов, обращение к ним
и т.д. Свяжем с каждым правилом грамматики семантическую програм-
му, которая должна выполнять соответствующую семантическую обра-
ботку, когда связанное с ней правило вызывает синтаксическую ре-
дукцию. Рассмотрим как осуществить перевод арифметического выра-
жения с данными правилами в различные внутренние формы:
Правила грамматики:
Z ::= E
E ::= T|E+T|E─T|─T
T ::= F|T*F|T|F
F ::= I|(E)
Похожие работы
... работы. В ходе работы над дипломным проектом разработан транслятор. Проблема создания такого транслятора является очень актуальной, т.к. многим пользователям САПР необходимо доступ к технической документацию, которую удобнее хранить на удаленных серверах в формате HTML. Поэтому степень положительного эффекта от выполнения дипломного проекта научно-исследовательского характера 1=6.5. В ...

... направления, активно развиваемого сейчас в разных коллективах и странах. Отталкиваясь от трансформационной модели смешанных вычислений и от своих работ в области трансляции и оптимизации программ, Ершов определяет концепцию трансформационной машины. Трансформационная машина есть абстрактное вычислительное устройство, выполняющее программы в некотором "сверхязыке", действиями которого являются ...
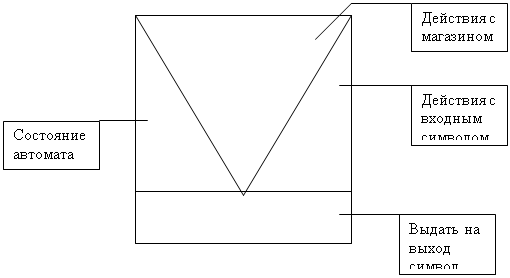

... 166, 16 Mb RAM, Windows 95 Вывод В ходе разработки курсового проекта я ближе ознакомился с теорией МП- трансляторов, научился писать программы - конструкторы для построения МП – транслятора по его параметрам с последующей проверкой задаваемых цепочек, закрепил знания по системному программированию. Разрабатывая программу, я научился применять знания дискретной математике, что облегчает ...
... позволяет связывать твёрдотельные модели, сборки или чертежи, созданные с помощью SolidWorks 97, с файлами других приложений, что значительно расширяет возможности автоматизации процесса проектирования. С помощью технологии OLE можно использовать информацию, полученную в других приложениях Windows, для управления моделями и чертежами SolidWorks. Например, размеры модели могут быть рассчитаны в ...
0 комментариев