Теоретическая часть
Методы, используемые при поиске и сортировке
Оценки времени исполнения
Приложение на Delphi, в котором представлена работа некоторых методов сортировки и поиска
Пример выполнения
Вопросы для самопроверки
Представление множеств и отношений в программах
Алгоритмы генерации множеств
Then
Варианты заданий
Теоретическая часть
Примеры выполнения
Вариантв заданий
Перевод даты рождения в двоичную систему
Вопросы для самопроверки
Вопросы для самопроверки
Процедура основного обработчика
Вопросы для самопроверки
Практическая часть
Дешифраторы
Навигация
Методы, используемые при поиске и сортировке
Основы дискретной математики
179431
знак
27
таблиц
82
изображения
1.2 Методы, используемые при поиске и сортировке
1.2.1 Основные понятия
Существуют различные алгоритмы сортировки данных. И понятно, что не существует универсального, наилучшего во всех отношениях алгоритма сортировки. Эффективность алгоритма зависит от множества факторов, среди которых можно выделить основные:
– числа сортируемых элементов;
– степени начальной отсортированности (диапазона и распределения значений сортируемых элементов);
– необходимости исключения или добавления элементов;
– доступа к сортируемым элементам (прямого или последовательного). Принципиальным для выбора метода сортировки является последний фактор [16].
Если данные могут быть расположены в оперативной памяти, то к любому элементу возможен прямой доступ. Удобной структурой данных в этом случае выступает массив сортируемых элементов. Если данные размещены на внешнем носителе в файле последовательного доступа, то к ним можно обращаться последовательно. В качестве структуры подобных данных можно взять файловый тип [9].
В этой связи выделяют сортировку двух классов объектов: массивов (внутренняя сортировка) и файлов (внешняя сортировка).
Процедура сортировки предполагает, что при наличии некоторой упорядочивающей функции F расположение элементов исходного множества меняется таким образом, что
![]()
![]() ,
,
где знак неравенства понимается в смысле того порядка, который установлен в сортируемом множестве.
Поиск и сортировка являются классическими задачами теории обработки данных, решают эти задачи с помощью множества различных алгоритмов. Рассмотрим наиболее популярные из них.
1.2.2 Поиск
Для определенности примем, что множество, в котором осуществляется поиск, задано как массив:
var a: array [0..N] of item;
где item – заданный структурированный тип данных, обладающий хотя бы одним полем (ключом), по которому необходимо проводить поиск.
Результатом поиска, как правило, служит элемент массива, равный эталону, или отсутствие такового.
Важно знать и про ассоциативную память. Это можно понимать как деление памяти на порции (называемые записями), и с каждой записью ассоциируется ключ. Ключ – это значение из некоторого вполне упорядоченного множества, а записи могут иметь произвольную природу и различные параметры. Доступ к данным осуществляется по значению ключа, которое обычно выбирается простым, компактным и удобным для работы.
Дерево сортировки – бинарное дерево, каждый узел которого содержит ключ и обладает следующим свойством: значения ключа во всех узлах левого поддерева меньше, а во всех узлах правого поддерева больше, чем значение ключа в узле.
Таблица расстановки.
Поиск, вставка и удаление, как известно, – основные операции при работе с данными [16]. Мы начнем с исследования того, как эти операции реализуются над самыми известными объектами – массивами и (связанными) списками.
Массивы
На рисунке 1.1 показан массив из семи элементов с числовыми значениями. Чтобы найти в нем нужное нам число, мы можем использовать линейный поиск (процедура представлена на псевдокоде, подобном языку Паскаль):
int function SequentialSearch (Array A, int Lb, int Ub, int Key);
begin
for i = Lb to Ub do
if A (i) = Key then
return i;
return –1;
end;
Максимальное число сравнений при таком поиске – 7; оно достигается в случае, когда нужное нам значение находится в элементе A[6]. Различают поиск в упорядоченном и неупорядоченном массивах. В неупорядоченном массиве, если нет никакой дополнительной информации об элементе поиска, его выполняют с помощью последовательного просмотра всего массива и называют линейным поиском. Рассмотрим программу, реализующую линейный поиск. Очевидно, что в любом случае существуют два условия окончания поиска: 1) элемент найден; 2) весь массив просмотрен, и элемент не найден. Приходим к программе:
While (a[i]<>x) and (i<n) do Inc(i);
If a[i]<>x then Write (‘Заданного элемента нет’)
Если известно, что данные отсортированы, можно применить двоичный поиск:
int function BinarySearch (Array A, int Lb, int Ub, int Key);
begin
do forever
M = (Lb + Ub)/2;
if (Key < A[M]) then
Ub = M – 1;
else if (Key > A[M]) then
Lb = M + 1;
else
return M;
if (Lb > Ub) then
return –1;
end;
Переменные Lb и Ub содержат, соответственно, верхнюю и нижнюю границы отрезка массива, где находится нужный нам элемент. Мы начинаем всегда с исследования среднего элемента отрезка. Если искомое значение меньше среднего элемента, мы переходим к поиску в верхней половине отрезка, где все элементы меньше только что проверенного. Другими словами, значением Ub становится равным (M – 1) и на следующей итерации мы работаем с половиной массива. Таким образом, в результате каждой проверки мы вдвое сужаем область поиска. Так, в нашем примере, после первой итерации область поиска – всего лишь три элемента, после второй остается всего лишь один элемент. Таким образом, если длина массива равна 6, нам достаточно трех итераций, чтобы найти нужное число.
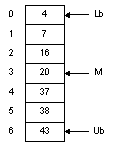
Рисунок 1.1 – Массив
Двоичный поиск – очень мощный метод. Если, например, длина массива равна 1023, после первого сравнения область сужается до 511 элементов, а после второй – до 255. Легко посчитать, что для поиска в массиве из 1023 элементов достаточно 10 сравнений.
Кроме поиска нам необходимо бывает вставлять и удалять элементы. К сожалению, массив плохо приспособлен для выполнения этих операций. Например, чтобы вставить число 18 в массив на рисунке 1.1, нам понадобится сдвинуть элементы A[3]… A[6] вниз – лишь после этого мы сможем записать число 18 в элемент A[3]. Аналогичная проблема возникает при удалении элементов. Для повышения эффективности операций вставки / удаления предложены связанные списки.
Иначе двоичный поиск (бинарный поиск) называют поиском делением пополам. В большинстве случаев процедура поиска применяется к упорядоченным данным (телефонный справочник, библиотечные каталоги и пр.).
Односвязные списки
На рисунке 1.2 те же числа, что и раньше, хранятся в виде связанного списка; слово «связанный» часто опускают. Предполагая, что X и P являются указателями, число 18 можно вставить в такой список следующим образом:
X->Next = P->Next;
P->Next = X;
Списки позволяют осуществить вставку и удаление очень эффективно. Поинтересуемся, однако, как найти место, куда мы будем вставлять новый элемент, т. е. каким образом присвоить нужное значение указателю P. Увы, для поиска нужной точки придется пройтись по элементам списка. Таким образом, переход к спискам позволяет уменьшить время вставки / удаления элемента за счет увеличения времени поиска.
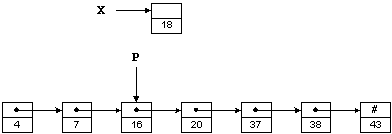
Рисунок 1. 2 – Односвязный список
Поиск в бинарных деревьях
Мы использовали двоичный поиск для поиска данных в массиве. Этот метод чрезвычайно эффективен, поскольку каждая итерация вдвое уменьшает число элементов, среди которых нам нужно продолжать поиск. Однако операции вставки и удаления элементов не столь эффективны. Двоичные деревья позволяют сохранить эффективность всех трех операций – если работа идет со «случайными» данными. В этом случае время поиска оценивается как O (lg n). Наихудший случай – когда вставляются упорядоченные данные. В этом случае оценка время поиска – O(n).
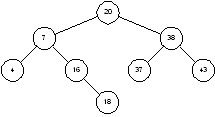
Двоичное дерево – это дерево, у которого каждый узел имеет не более двух наследников. Пример бинарного дерева приведен на рисунке 1.5. Предполагая, что Key содержит значение, хранимое в данном узле, мы можем сказать, что бинарное дерево обладает следующим свойством: у всех узлов, расположенных слева от данного узла, значение соответствующего поля меньше, чем Key, у всех узлов, расположенных справа от него, – больше. Вершину дерева называют его корнем. Узлы, у которых отсутствуют оба наследника, называются листьями. Корень дерева на рисунке 1.3 содержит число 20, а листья – 4, 16, 37 и 43. Высота дерева – это длина наидлиннейшего из путей от корня к листьям. В нашем примере высота дерева равна 2.
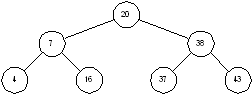
Рисунок 1.3 – Двоичное дерево
Чтобы найти в дереве какое-то значение, мы стартуем из корня и движемся вниз. Например, для поиска числа 16, мы замечаем, что 16 < 20, и потому идем влево. При втором сравнении имеем 16 > 7, так что мы движемся вправо. Третья попытка успешна – мы находим элемент с ключом, равным 16.
Каждое сравнение вдвое уменьшает количество оставшихся элементов. В этом отношении алгоритм похож на двоичный поиск в массиве. Однако, все это верно только в случаях, когда наше дерево сбалансировано. На рисунке 1.4 показано другое дерево, содержащее те же элементы. Несмотря на то, что это дерево тоже бинарное, поиск в нем похож, скорее, на поиск в односвязном списке, время поиска увеличивается пропорционально числу запоминаемых элементов.
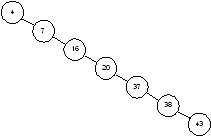
Рисунок 1.4 – Несбалансированное бинарное дерево
Вставка и удаление
Чтобы лучше понять, как дерево становится несбалансированным, посмотрим на процесс вставки пристальнее. Чтобы вставить 18 в дерево на рисунке 1.3 мы ищем это число. Поиск приводит нас в узел 16, где благополучно завершается. Поскольку 18 > 16, мы попросту добавляет узел 18 в качестве правого потомка узла 16 (рисунок 1.5).
Теперь мы видим, как возникает несбалансированность дерева. Если данные поступают в возрастающем порядке, каждый новый узел добавляется справа от последнего вставленного. Это приводит к одному длинному списку. Обратите внимание: чем более «случайны» поступающие данные, тем более сбалансированным получается дерево.
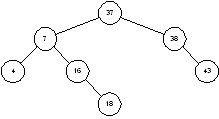
Удаления производятся примерно так же – необходимо только позаботиться о сохранении структуры дерева. Например, если из дерева на рисунке 1.5 удаляется узел 20, его сначала нужно заменить на узел 37. Это даст дерево, изображенное на рисунок 1.6. Рассуждения здесь примерно следующие. Нам нужно найти потомка узла 20, справа от которого расположены узлы с большими значениями. Таким образом, нам нужно выбрать узел с наименьшим значением, расположенный справа от узла 20. Чтобы найти его, нам и нужно сначала спуститься на шаг вправо (попадаем в узел 38), а затем на шаг влево (узел 37); эти двухшаговые спуски продолжаются, пока мы не придем в концевой узел, лист дерева.
|
Рисунок 1.5 – Бинарное дерево после добавления узла 18 |
Рисунок 1.6 – Бинарное дерево после удаления узла 20 |
Разделенные списки
Разделенные списки – это связные списки, которые позволяют вам прыгнуть (skip) к нужному элементу. Это позволяет преодолеть ограничения последовательного поиска, являющегося основным источником неэффективного поиска в списках. В то же время вставка и удаление остаются сравнительно эффективными. Оценка среднего времени поиска в таких списках есть O (lg n). Для наихудшего случая оценкой является O(n), но худший случай крайне маловероятен.
Идея, лежащая в основе разделенных списков, очень напоминает метод, используемый при поиске имен в адресной книжке. Чтобы найти имя, вы помечаете буквой страницу, откуда начинаются имена, начинающиеся с этой буквы. На рисунке 1.6, например, самый верхний список представляет обычный односвязный список. Добавив один «уровень» ссылок, мы ускорим поиск. Сначала мы пойдем по ссылкам уровня 1, затем, когда дойдем до нужного отрезка списка, пойдем по ссылкам нулевого уровня.
Эта простая идея может быть расширена – мы можем добавить нужное число уровней. Внизу на рисунке 1.6 мы видим второй уровень, который позволяет двигаться еще быстрее первого. При поиске элемента мы двигаемся по этому уровню, пока не дойдем до нужного отрезка списка. Затем мы еще уменьшаем интервал неопределенности, двигаясь по ссылкам 1‑го уровня. Лишь после этого мы проходим по ссылкам 0‑го уровня.
Вставляя узел, нам понадобится определить количество исходящих от него ссылок. Эта проблема легче всего решается с использованием случайного механизма: при добавлении нового узла мы «бросаем монету», чтобы определить, нужно ли добавлять еще слой. Например, мы можем добавлять очередные слои до тех пор, пока выпадает «решка». Если реализован только один уровень, мы имеем дело фактически с обычным списком и время поиска есть O(n). Однако если имеется достаточное число уровней, разделенный список можно считать деревом с корнем на высшем уровне, а для дерева время поиска есть O (lg n).
Поскольку реализация разделенных списков включает в себя случайный процесс, для времени поиска в них устанавливаются вероятностные границы. При обычных условиях эти границы довольно узки. Например, когда мы ищем элемент в списке из 1000 узлов, вероятность того, что время поиска окажется в 5 раз больше среднего, можно оценить как 1/ 1,000,000,000,000,000,000 (рисунок 1.7).
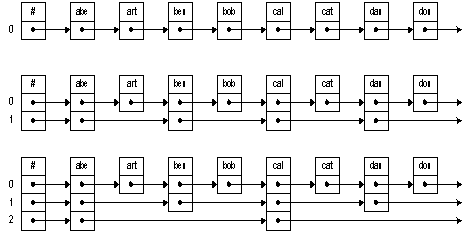
Рисунок 1.7 – Устройство разделенного списка
Похожие работы
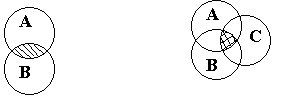
... Е и множество и мы рассматриваем все его подмножества, то множество Е называется униварсельным. Пример: Если за Е взять множество книг то его подмножества: художественные книги, книги по математике, физики, физики … Если универсальное множество состоит из n элементов, то число подмножеств = 2n. Если , состоящее из элементов E, не принадлежащих А, называется дополненным. Множество можно задать: ...
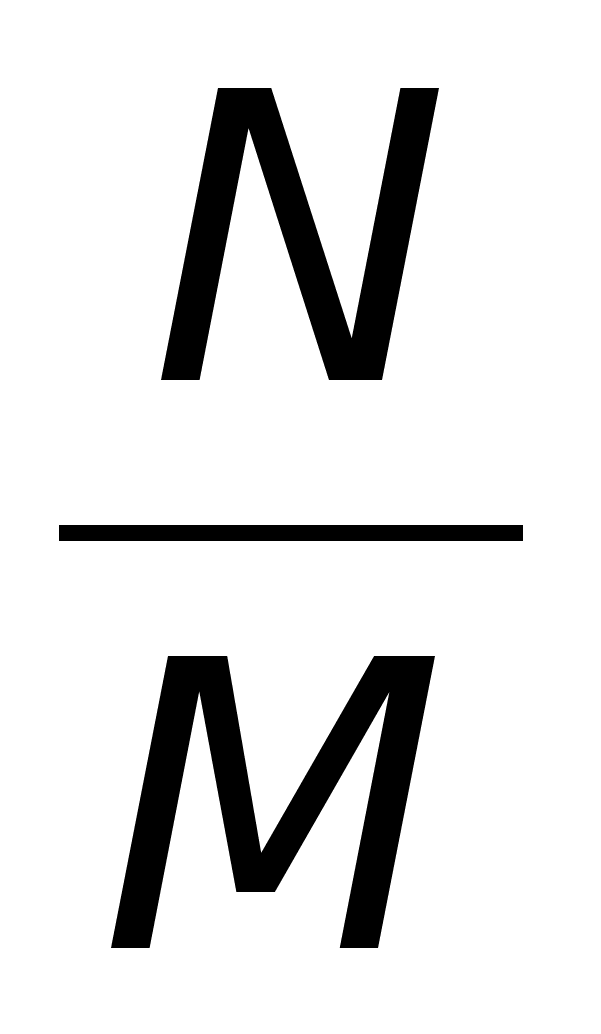
в и формальных систем является центральной в дисциплине. В настоящие время от нее возникли ответвления, например, разработка алгоритмических языков программирования.Одной из важнейших проблем в дискретной математики является проблема сложности вычислений.Теория сложности вычислений помогает оценить расход времени и памяти при решении задач на ЭВМ. Теория сложности позволяет выделить объективно ...
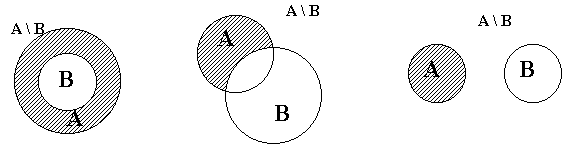
... которой были разработаны в последней четверти 19 века Георгом Кантором. Цель контрольной работы – ознакомится с основными понятиями и методами решения по дискретной математике, уметь применить полученные знания при решении практического задания. Задание 1 Представить с помощью кругов Эйлера множественное выражение . Используя законы и свойства алгебры множеств, упростить заданное ...
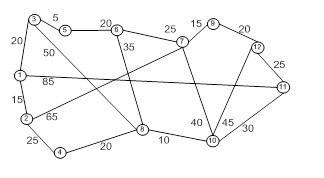
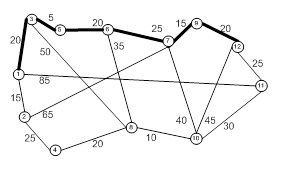
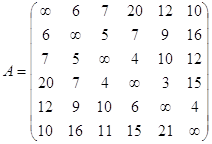
элементы теории нечетких множеств можно применять для решения экономических задач в условиях неопределённости. 1. применение Логических функций 1.1 Применение методов дискретной математики в экономике При исследовании, анализе и решении управленческих проблем, моделировании объектов исследования и анализа широко используются методы формализированного представления, являющегося предметом ...
0 комментариев