Теоретическая часть
Методы, используемые при поиске и сортировке
Оценки времени исполнения
Приложение на Delphi, в котором представлена работа некоторых методов сортировки и поиска
Пример выполнения
Вопросы для самопроверки
Представление множеств и отношений в программах
Алгоритмы генерации множеств
Then
Варианты заданий
Теоретическая часть
Примеры выполнения
Вариантв заданий
Перевод даты рождения в двоичную систему
Вопросы для самопроверки
Вопросы для самопроверки
Процедура основного обработчика
Вопросы для самопроверки
Практическая часть
Дешифраторы
Навигация
Оценки времени исполнения
Основы дискретной математики
179431
знак
27
таблиц
82
изображения
1.2.3 Оценки времени исполнения
Для оценки эффективности алгоритмов можно использовать разные подходы. Самый бесхитростный – просто запустить каждый алгоритм на нескольких задачах и сравнить время исполнения. Другой способ – оценить время исполнения. Например, мы можем утверждать, что время поиска есть O(n) (читается так: о большое от n). Это означает, что при больших n время поиска не сильно больше, чем количество элементов. Когда используют обозначение O(), имеют в виду не точное время исполнения, а только его предел сверху, причем с точностью до постоянного множителя. Когда говорят, например, что алгоритму требуется время порядка O(n2), имеют в виду, что время исполнения задачи растет не быстрее, чем квадрат количества элементов. Чтобы почувствовать, что это такое, посмотрите таблицу 1.1, где приведены числа, иллюстрирующие скорость роста для нескольких разных функций. Скорость роста O(log2n) характеризует алгоритмы типа двоичного поиска.
Таблица 1.1 – Скорость роста нескольких функций O()
| n | log2 n | n log2 n | n1.25 | n2 |
| 1 | 0 | 0 | 1 | 1 |
| 16 | 4 | 64 | 32 | 256 |
| 256 | 8 | 2,048 | 1,024 | 65,536 |
| 4,096 | 12 | 49,152 | 32,768 | 16,777,216 |
| 65,536 | 16 | 1,048,565 | 1,048,476 | 4,294,967,296 |
| 1,048,476 | 20 | 20,969,520 | 33,554,432 | 1,099,301,922,576 |
| 16,775,616 | 24 | 402,614,784 | 1,073,613,825 | 281,421,292,179,456 |
Если считать, что числа в таблице 1.1 соответствуют микросекундам, то для задачи с 1048476 элементами алгоритму со временем работы O(log2 n) потребуется 20 микросекунд, алгоритму со временем работы O(n1.25) – порядка 33 секунд, алгоритму со временем работы O(n2) – более 12 дней. В нижеследующем тексте для каждого алгоритма приведены соответствующие O‑оценки. Более точные формулировки и доказательства можно найти в [12], [15].
Как мы видели, если массив отсортирован, то искать его элементы необходимо с помощью двоичного поиска. Однако не забудем, что массив должен быть отсортированным! В следующем разделе мы исследует разные способы сортировки массива. Оказывается, эта задача встречается достаточно часто и требует заметных вычислительных ресурсов, поэтому сортирующие алгоритмы исследованы вдоль и поперек, известны алгоритмы, эффективность которых достигла теоретического предела.
Связанные списки позволяют эффективно вставлять и удалять элементы, но поиск в них последователен и потому отнимает много времени. Имеются алгоритмы, позволяющие эффективно выполнять все три операции.
1.2.4 Сортировки
Сортировка вставками
Один из простейших способов отсортировать массив – сортировка вставками. В обычной жизни мы сталкиваемся с этим методом при игре в карты. Чтобы отсортировать имеющиеся у вас карты, вы вынимаете карту, сдвигаете оставшиеся карты, а затем вставляете карту на нужное место. Процесс повторяется до тех пор, пока хоть одна карта находится не на месте. Как среднее, так и худшее время для этого алгоритма – O(n2). Дальнейшую информацию можно получить в книге Кнута [4].
На рисунке 1.8 (a) мы вынимаем элемент 3. Затем элементы, расположенные выше, сдвигаем вниз – до тех пор, пока не найдем место, куда нужно вставить 3. Это процесс продолжается на рисунке 1.8 (b) для числа 1. Наконец, на рисунке 1.8 (c) мы завершаем сортировку, поместив 2 на нужное место.
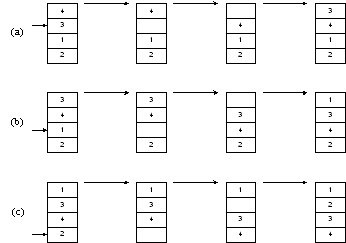
Рисунок 1.8 – Сортировка вставками
Если длина нашего массива равна n, нам нужно пройтись по n – 1 элементам. Каждый раз нам может понадобиться сдвинуть n – 1 других элементов. Вот почему этот метод требует довольно-таки много времени.
Сортировка вставками относится к числу методов сортировки по месту. Другими словами, ей не требуется вспомогательная память, мы сортируем элементы массива, используя только память, занимаемую самим массивом. Кроме того, она является устойчивой – если среди сортируемых ключей имеются одинаковые, после сортировки они остаются в исходном порядке.
Сортировка с помощью включения
Кто играл в карты, процедуру сортировки включениями осуществлял многократно. Как правило, после раздачи карт игрок, держа карты веером в руке, переставляет карты с места на место, стремясь их расположить по мастям и рангам, например, сначала все тузы, затем короли, дамы и т. д. Элементы (карты) мысленно делятся на уже «готовую последовательность» и неправильно расположенную последовательность. Теперь на каждом шаге, начиная с i = 2, из неправильно расположенной последовательности извлекается очередной элемент и перекладывается в готовую последовательность на нужное место.
for i:=2 to N do
begin
x:=a[i];
<включение х на соответствующее место готовой последовательности a[1],…, a[i]>
End
Поиск подходящего места можно осуществить одним из методов поиска в массиве, описанным выше. Затем х либо вставляется на свободное место, либо сдвигает вправо на один индекс всю левую сторону. Схематично представим алгоритм для конкретного примера:
Исходные элементы 23 34 12 13 9
i=2 23 34 12 13 9
i=3 12 23 34 13 9
i=4 12 13 23 34 9
i=5 9 12 13 23 34
В алгоритме поиск подходящего места осуществляется как бы просеиванием x: при движении по последовательности и сравнении с очередным a[j]. Затем х либо вставляется на свободное место, либо а[j] сдвигается вправо и процесс как бы «уходит» влево.
Сортировка с помощью прямого включения
Элементы массива, начиная со второго, последовательно берутся по одному и включаются на нужное место в уже упорядоченную часть массива, расположенную слева от текущего элемента а[i]. В отличие от стандартной ситуации включения элемента в заданную позицию массива, позиция включаемого элемента при этом неизвестна. Определим её, сравнивая в цикле поочерёдно a[i] с a [i‑1], а [i‑2],… до тех пор, пока не будет найден первый из элементов меньший или равный а[i], либо не будет достигнут левый конец массива. Поскольку операции сравнения и перемещения чередуются друг с другом, то этот способ часто называют просеиванием или погружением. Очевидно, что программа, реализующая описанный алгоритм, должна содержать цикл в цикле.
program sortirovka_l;
(*сортировка включением по линейному поиску*)
const N=5;
type item= integer;
var a: array [0..n] of item; i, j: integer; x: item;
begin (*задание искомого массива*)
for i:=1 to N do begin write ('введите элемент a [', i, ']=');
readln (a[i])
end;
for i:=1 to N do begin write (a[i], ' ');
end;
writeln;
(*алгоритм сортировки включением*)
for i:=2 to n do
begin
x:=a[i]; j:=i; a[0]:=x; (*барьер*)
while x<a [j-l] do
begin
a[j]:=a [j‑1]; j:=j‑1;
end;
a[j]:=x;
{for k:=1 to n do write (a[k], ' ') end; writeln;} end;
(*вывод отсортированного массива*)
for i:=1 to N do
begin
write (a[i], ' '); end;
readln; end.
В рассмотренном примере программы для анализа процедуры пошаговой сортировки можно рекомендовать использовать трассировку каждого прохода по массиву с целью визуализации его текущего состояния. В тексте программы в блоке непосредственного алгоритма сортировки в фигурных скобках находится строка, которая при удалении скобок выполнит требуемое (параметр k необходимо описать в разделе переменных – var k:integer).
Вернемся к анализу метода прямого включения. Поскольку готовая последовательность уже упорядочена, то алгоритм улучшается при использовании алгоритма поиска делением пополам. Такой способ сортировки называют методом двоичного включения.
program sortirovka_2;
(*сортировка двоичным включением*)
const N=5;
type item= integer;
var a: array [0..n] of item; i, j, m, L, R: integer; x: item;
begin (*задание элементов массива*)
for i: – l to N do begin write ('введите элемент a [', i, ']= ');
readln (a[i]);
end;
for i:=1 to N do begin write (a[i], ' ');
end;
writeln;
(*алгоритм сортировки двоичным включением*)
for i:=2 to n do
begin
x:=a[i]; L:=l; R:^i;
while L<R do
begin
m:=(L+R) div 2; if a [m] <=x then L:=m+1 else R:=m;
end;
for j:=i downto R+l do a[j]:=a [j‑1];
a[R]:=x; end;
(* вывод отсортированного массива*)
for i: – l to N do
begin write (a[i], ' ');
end;
readln;
end.
Сортировка Шелла
Метод, предложенный Дональдом Л. Шеллом, является неустойчивой сортировкой по месту. Эффективность метода Шелла объясняется тем, что сдвигаемые элементы быстро попадают на нужные места. Среднее время для сортировки Шелла равняется O(n1.25), для худшего случая оценкой является O(n1.5). Дальнейшие ссылки см. в книге Кнута [4].
На рисунке 1.8 приведен пример сортировки вставками. Мы сначала вынимали 1, затем сдвигали 3 и 5 на одну позицию вниз, после чего вставляли 1. Таким образом, нам требовались два сдвига. В следующий раз нам требовалось два сдвига, чтобы вставить на нужное место 2. На весь процесс нам требовалось 2+2+1=5 сдвигов.
На рисунке 1.9 иллюстрируется сортировка Шелла. Мы начинаем, производя сортировку вставками с шагом 2. Сначала мы рассматриваем числа 3 и 1: извлекаем 2, сдвигаем 3 на 1 позицию с шагом 2, вставляем 2. Затем повторяем то же для чисел 5 и 2: извлекаем 2, сдвигаем вниз 5, вставляем 2 и т. д. Закончив сортировку с шагом 2, производим ее с шагом 1, т. е. выполняем обычную сортировку вставками. Всего при этом нам понадобится 1 + 1+ 1 = 3 сдвига. Таким образом, использовав вначале шаг, больший 1, мы добились меньшего числа сдвигов.
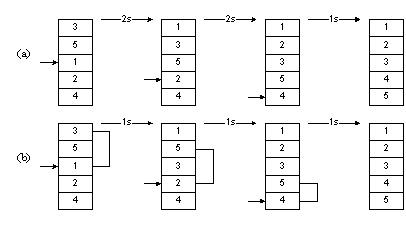
Рисунок 1.9 – Сортировка Шелла
Можно использовать самые разные схемы выбора шагов. Как правило, сначала мы сортируем массив с большим шагом, затем уменьшаем шаг и повторяем сортировку. В самом конце сортируем с шагом 1. Хотя этот метод легко объяснить, его формальный анализ довольно труден. В частности, теоретикам не удалось найти оптимальную схему выбора шагов. Кнут провел множество экспериментов и следующую формулу выбора шагов (h) для массива длины N.
Вот несколько первых значений h:
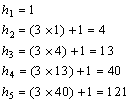 .
.
Чтобы отсортировать массив длиной 100, прежде всего, найдем номер s, для которого hs ³ 100. Согласно приведенным цифрам, s = 5. Нужное нам значение находится двумя строчками выше. Таким образом, последовательность шагов при сортировке будет такой: 13–4–1. Ну, конечно, нам не нужно хранить эту последовательность: очередное значение h находится из предыдущего.
Сортировка с помощью дерева
Улучшенный метод сортировки выбором с помощью дерева. Метод сортировки прямым выбором основан на поисках наименьшего элемента среди неготовой последовательности. Усилить метод можно запоминанием информации при сравнении пар элементов. Этого добиваются определением в каждой паре меньшего элемента за n/2 сравнений. Далее n/4 сравнений позволит выбрать меньший из пары уже выбранных меньших и т. д. Получается двоичное дерево сравнений после n‑1 сравнений, у которого в корневой вершине находится наименьший элемент, а любая вершина содержит меньший элемент из двух приходящих к ней вершин. Одним из алгоритмов, использующих структуру дерева, является сортировка с помощью пирамиды (Дж. Вильямс) [3]. Пирамида определяется как последовательность ключей hL…hR, такая, что
hi<=h2i и hi<=h2i+l, для i=L,…, R/2.
Другими словами, пирамиду можно определить как двоичное дерево заданной высоты h, обладающее тремя свойствами:
• каждая конечная вершина имеет высоту h или h‑1;
• каждая конечная вершина высоты h находится слева от любой конечной вершины высоты h‑1;
• значение любой вершины больше значения любой следующей за ней вершины.
Рассмотрим пример пирамиды, составленной по массиву 27 9 14 8 5 11 7 2 3.
У пирамиды n=9 вершин, их значения можно разместить в массиве а, но таким образом, что следующие за вершиной из a[i] помещаются в a[2i] и a [2i+l]. Заметим, что а[6]=11, а[7]=7, а они следуют за элементом а[3]=14 (рисунок 1.10).

Рисунок 1.10 – Пирамида
Очевидно, что если 2i > n, тогда за вершиной a[i] не следуют другие вершины, и она является конечной вершиной пирамиды.
Процесс построения пирамиды для заданного массива можно разбить на четыре этапа:
1) меняя местами а[1] и а[n], получаем 3 9 14 8 5 11 7 2 27;
2) уменьшаем n на 1, т. е. n=n‑1, что эквивалентно удалению вершины 27 из дерева;
3) преобразуем дерево в другую пирамиду перестановкой
нового корня с большей из двух новых, непосредственно следующих за ним вершин, до тех пор, пока он не станет больше, чем обе вершины, непосредственно за ним следующие;
4) повторяем шаги 1, 2, 3 до тех пор, пока не получим n=1.
Для алгоритма сортировки нужна процедура преобразования произвольного массива в пирамиду (шаг 3). В ней необходимо предусмотреть последовательный просмотр массива справа налево с проверкой одновременно двух условий: больше ли а[n], чем a[2i] и a [2i+l].
Полный текст программы приведен ниже.
program sortirovka_5;
(*улучшенная сортировка выбором – сортировка с помощью дерева*)
const N=8;
type item= integer;
var a: array [1..n] of item; k, L, R: integer; x: item;
procedure sift (L, R:integer);
var i, j: integer; x, y: item;
begin i:=L; j:=2*L; x:=a[L]; if (j<R) and (a[j]<a [j+1]) then j:=j+1;
while (j<=R) and (x<a[j]) do begin y:=a[i]; a[i]:=a[j];
a[j]:=y; a[i]:=a[j]; i:=j; j:=2*j;
if (j<R) and (a[j]<a [j+1]) then j:=j+1;
end;
end;
begin
(*задание искомого массива*)
for k:=1 to N do begin write ('Bведите элемент a [', k, ']=');
readln (a[k]);
end;
for k:=1 to N do begin write (a[k], ' ');
end;
writeln;
(*алгоритм сортировки с помощью дерева*)
(*построение пирамиды*)
L:=(n div 2) +1; R:=n; while L>1 do begin L:=L‑1; SIFT (L, R);
end;
(*сортировка*)
while R>1 do begin x:=a[l]; a[l]:=a[R]; a[R]:=x; R:=R‑1; SIET (1, R);
end;
(*вывод отсортированного массива*) for k:=1 to N do begin write (a[k], ' ');
end;
readln;
end.
Сортировка с помощью обменов
1‑ый вариант. Соседние элементы массива сравниваются и при необходимости меняются местами до тех пор, пока массив не будет полностью упорядочен. Повторные проходы массива сдвигают каждый раз наименьший элемент оставшейся части массива к левому его концу. Метод широко известен под названием «пузырьковая сортировка» потому, что большие элементы массива, подобно пузырькам, «всплывают» на соответствующую позицию. Основной фрагмент программы содержит два вложенных цикла, причём внутренний цикл удобнее выбрать с шагом, равным -1 [8]:
for i: =2 to n do
for j:=n downto i do
if a [j‑1]>a[j] then
begin {обмен}x:=a [j‑1]; a [j‑1]:=a[j]; a[j]:=xend;
2‑ой вариант. Пузырьковая сортировка является не самой эффективной, особенно для последовательностей, у которых «всплывающие» элементы находятся в крайней правой стороне. В улучшенной (быстрой) пузырьковой сортировке предлагается производить перестановки на большие расстояния, причем двигаться с двух сторон. Идея алгоритма заключается в сравнении элементов, из которых один берется слева (i = 1), другой – справа (j = n). Если a[i] <= a[j], то устанавливают j = j – 1 и проводят следующее сравнение. Далее уменьшают j до тех пор, пока a[i] > a[j]. В противном случае меняем их местами и устанавливаем i = i + 1. Увеличение i продолжаем до тех пор, пока не получим a[i] > a[j]. После следующего обмена опять уменьшаем j. Чередуя уменьшение j и увеличение i, продолжаем этот процесс с обоих концов до тех пор, пока не станет i = j. После этого этапа возникает ситуация, когда первый элемент занимает ему предназначенное место, слева от него младшие элементы, а справа – старшие [8].
Далее подобную процедуру можно применить к левой и правой частям массива и т. д. Очевидно, что характер алгоритма рекурсивный. Для запоминания ведущих левого и правого элементов в программе необходимо использовать стек.
Характерной чертой алгоритмов сортировки с помощью обмена является обмен местами двух элементов массива после их сравнения друг с другом. В так называемой «пузырьковой сортировке» проводят несколько проходов по массиву, в каждом из которых повторяется одна и та же процедура: сравнение двух последовательно стоящих элементов и их обмен местами в порядке меньшинства (старшинства). Подобная процедура сдвигает наименьшие элементы к левому концу массива.
program sortirovka_6;
(*сортировка прямым обменом – пузырьковая сортировка*)
const N=5;
type item= integer;
var a: array [1..n] of item; i, j: integer; x: item;
begin (*задание искомого массива*)
for i:=1 to N do begin write ('введи элемент a [', i, ']= ');
readln (a[i]);
end;
for i:=1 to N do begin write (a[i], ' ');
end;
writeln;
(*алгоритм пузырьковой сортировки*)
for i:=2 to n do for j:=n downto i do begin
if a [j‑1]>a[j] then begin x:=a [j‑1]; a [j‑1]:=a[j]; a[j]:=x;
end;
end;
(*вывод отсортированного массива*)
for i:=1 to N do begin write (a[i], ' ');
end;
readln;
end.
Представленную программу можно легко улучшить, если учесть, что если после очередного прохода перестановок не было, то последовательность элементов уже упорядочена, т. е. продолжать проходы не имеет смысла. Если чередовать направление последовательных просмотров, алгоритм улучшается. Такой алгоритм называют «шейкерной» сортировкой.
program sortirovka_7;
(*сортировка прямым обменом – шейкерная сортировка*)
const N=5;
type item= integer;
var a: array [1..n] of item; i, j, k, L, R: integer; x: item;
begin (*задание искомого массива*)
for i: =1 to N do begin write ('введи элемент а [', i, '] = ');
readln (a[i]);
end;
for i:=1 to N do begin write (a[i], ' ');
end;
writeln;
(*алгоритм шейкерной сортировки*)
L: =2; R:=n; k:=n;
repeat
for j:=R downto L do begin
if a [j-l]>a[j] then begin x:=a [j‑1]; a [j‑1]:=a[j];
a[j]:=x; k:=-j
end;
end;
L:=k+1;
for j:=L to R do begin
if a [j-l]>a[j] then begin x:=a [j-l]
a [j-l]:=a[j]; a[j]:=x; k:=j
end;
end;
R:=k‑1; until L>R;
(*вывод отсортированного массива*)
for i:=l to N do
begin write (a[i], ' ');
end;
readln;
end.
Быстрая сортировка
Хотя идея Шелла значительно улучшает сортировку вставками, резервы еще остаются. Один из наиболее известных алгоритмов сортировки – быстрая сортировка, предложенная Ч. Хоаром. Метод и в самом деле очень быстр, недаром по-английски его так и величают QuickSort [6].
Этому методу требуется O (n log2n) в среднем и O(n2) в худшем случае. К счастью, если принять адекватные предосторожности, наихудший случай крайне маловероятен. Быстрый поиск не является устойчивым. Кроме того, ему требуется стек, т. е. он не является и методом сортировки на месте.
Алгоритм разбивает сортируемый массив на разделы, затем рекурсивно сортирует каждый раздел. В функции Partition один из элементов массива выбирается в качестве центрального. Ключи, меньшие центрального, следует расположить слева от него, те, которые больше – справа.
int function Partition (Array A, int Lb, int Ub);
begin
select a pivot from A[Lb]… A[Ub];
reorder A[Lb]… A[Ub] such that:
all values to the left of the pivot are £ pivot
all values to the right of the pivot are ³ pivot
return pivot position;
end;
procedure QuickSort (Array A, int Lb, int Ub);
begin
if Lb < Ub then
M = Partition (A, Lb, Ub);
QuickSort (A, Lb, M – 1);
QuickSort (A, M + 1, Ub);
end;
На рисунке 1.11 (а) в качестве центрального выбран элемент 3. Индексы начинают изменяться с концов массива. Индекс i начинается слева и используется для выбора элементов, которые больше центрального, индекс j начинается справа и используется для выбора элементов, которые меньше центрального. Эти элементы меняются местами – см. рисунок 1.11 (b). Процедура QuickSort рекурсивно сортирует два подмассива, в результате получается массив, представленный на рисунке 1.11 (c).
В процессе сортировки может потребоваться передвинуть центральный элемент. Если нам повезет, выбранный элемент окажется медианой значений массива, т. е. разделит его пополам. Предположим на минутку, что это и в самом деле так. Поскольку на каждом шаге мы делим массив пополам, а функция Partition, в конце концов, просмотрит все n элементов, время работы алгоритма есть O (n log2n).
В качестве центрального функция Partition может попросту брать первый элемент (A[Lb]). Все остальные элементы массива мы сравниваем с центральным и передвигаем либо влево от него, либо вправо. Есть, однако, один случай, который безжалостно разрушает эту прекрасную простоту. Предположим, что наш массив с самого начала отсортирован. Функция Partition всегда будет получать в качестве центрального минимальный элемент и потому разделит массив наихудшим способом: в левом разделе окажется один элемент, соответственно, в правом останется Ub – Lb элементов.
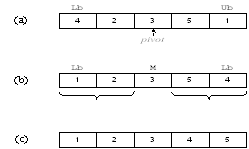
Рисунок 1.11 – Пример работы алгоритма Quicksort
Таким образом, каждый рекурсивный вызов процедуры quicksort всего лишь уменьшит длину сортируемого массива на 1. В результате для выполнения сортировки понадобится n рекурсивных вызовов, что приводит к времени работы алгоритма порядка O(n2). Один из способов побороть эту проблему – случайно выбирать центральный элемент. Это сделает наихудший случай чрезвычайно маловероятным.
Сортировка с помощью прямого выбора
При сортировке этим методом выбирается наименьший элемент массива и меняется местами с первым. Затем выбирается наименьший среди оставшихся n – 1 элементов и меняется местами со вторым и т. д. до тех пор, пока не останется один самый больший элемент. Основной фрагмент программы может выглядеть так [11]:
for i:=l to n‑1 do
begin
k: =i;
x:=a[i];
for j:=i+1 to n do
if a[j]<x then begin k:=j; x:=a[k] end;a[k]:=a[i]; a[i]: =xend;
k – величина, хранящая индекс элемента, участвующего в операции обмена.
Сортировка файлов
Главная особенность методов сортировки последовательных файлов в том, что при их обработке в каждый момент непосредственно доступна одна компонента (на которую указывает указатель). Чаще процесс сортировки протекает не в оперативной памяти, как в случае с массивами, а с элементами на внешних носителях («винчестере», дискете и т. п.).
Понять особенности сортировки последовательных файлов на внешних носителях позволит следующий пример [9].
Предположим, что нам необходимо упорядочить содержимое файла с последовательным доступом по какому-либо ключу. Для простоты изучения и анализа сортировки условимся, что файл формируем мы сами, используя, как и в предыдущем разделе, некоторый массив данных. Его же будем использовать и для просмотра содержимого файла после сортировки. В предлагаемом ниже алгоритме необходимо сформировать вспомогательный файл, который позволит осуществить следующую процедуру сортировки. Сначала выбираем из исходного файла первый элемент в качестве ведущего, затем извлекаем второй и сравниваем с ведущим. Если он оказался меньше, чем ведущий, то помещаем его во вспомогательный файл, в противном случае во вспомогательный файл помещается ведущий элемент, а его замещает второй элемент исходного файла. Первый проход заканчивается, когда аналогичная процедура коснется всех последовательных элементов исходного файла. Ведущий элемент заносится во вспомогательный файл последним. Теперь необходимо поменять местами исходный и вспомогательный файлы. После nil проходов в исходном файле данные будут размещены в упорядоченном виде.
program sortirovka_faila_1;
{сортировка последовательного файла}
const n=8; type item= integer;
var a: array [1..n] of item;
i, k: integer; x, y: item;
fl, f2: text; {file of item};
begin
{задание искомого массива}
for i:=1 to N do begin write ('введи элемент а ['i, '] = ');
readln (a[i]);
end;
writeln; assign (fl, 'datl.dat'); rewrite(fl);
assign (f2, 'dat2.dat'); rewrite(f2);
{формирование последовательного файла}
for i:=1 to N do begin writeln (fl, a[i]);
end;
{алгоритм сортировки с использованием вспомогательного файла}
for k:=1 to (n div 2) do
begin {извлечение из исходного файла и запись во вспомогательный}
reset(fl); readln (fl, x);
for i:=2 to n do begin readln (fl, y);
if x>y then writeln (f2, y) else begin writeln (f2, x); x:=y;
end;
end;
writeln (f2, x);
{извлечение из вспомогательного файла и запись в исходный}
rewrite(fl); reset(f2); readln (f2, x);
for i:=2 to n do begin readln (f2, y);
if x>y then writeln (fl, y) else begin writeln (fl, x); x:=y;
end;
end;
writeln (fl, x); rewrite(f2); end;
(вывод результата)
reset(fl);
for i:=1 to N do readln (fl, a[i]);
for i:=1 to N do begin write (a[i], ' ');
end;
close(fl); close(f2); readln;
end.
По сути можно в программе обойтись без массива а [1..n]. В качестве упражнения попытайтесь создать программу, в которой не используются массивы.
Многие методы сортировки последовательных файлов основаны на процедуре слияния, означающей объединение двух (или более) последовательностей в одну, упорядоченную с помощью повторяющегося выбора элементов (доступных в данный момент). В дальнейшем (чтобы не осуществлять многократного обращения к внешней памяти), будем рассматривать вместо файла массив данных, обращение к которому можно осуществлять строго последовательно. В этом смысле массив представляется как последовательность элементов, имеющая два конца, с которых можно считывать данные. При слиянии можно брать элементы с двух концов массива, что эквивалентно считыванию элементов из двух входных файлов.
Идея слияния заключается в том, что исходная последовательность разбивается на две половины, которые сливаются вновь в одну упорядоченными парами, образованными двумя элементами, последовательно извлекаемыми из этих двух подпоследовательностей. Вновь повторяем деление и слияние, но упорядочивая пары, затем четверки и т. д. Для реализации подобного алгоритма необходимы два массива, которые поочередно (как и в предыдущем примере) меняются ролями в качестве исходного и вспомогательного.
Если объединить эти два массива в один, разумеется, двойного размера, то программа упрощается. Пусть индексы i и j фиксируют два входных элемента с концов исходного массива, k и L – два выходных, соответствующих концам вспомогательного массива. Направлением пересылки (сменой ролей массивов) удобно управлять с помощью булевской переменной, которая меняет свое значение после каждого прохода, когда элементы a1…, an движутся на место ani….a2n и наоборот. Необходимо еще учесть изменяющийся на каждом проходе размер объединяемых упорядоченных групп элементов. Перед каждым последующим проходом размер удваивается. Если считать, что количество элементов в исходной последовательности не является степенью двойки (для процедуры разделения это существенно), то необходимо придумать стратегию разбиения на группы, размеры которых q и r могут не совпадать с ведущим размером очередного прохода. В окончательном виде алгоритм сортировки слиянием представлен ниже.
program sortirovka__faila_2;
{сортировка последовательного файла слиянием}
const N=8;
type item= integer;
var a: array [1..2*n] of item;
i, j, k, L, t, h, m, p, q, r: integer; f: boolean;
begin
{задание искомого массива}
for i:=1 to N do begin write ('введи элемент а [', i, '] = ');
readln (a[i]);
end;
writeln;
{сортировка слиянием}
f:=true; p:=1;
repeat
h:=1; m:=n; if f then begin
i:=1; j:=n; k:=n+1; L:=2*n
end
else begin k:=1; L:=n; i:=n+1; j:=2*n
end;
repeat
if m>=p then q:=p else q:=m; m:=m-q;
if m>=p then r:=p else r:=m; m:=m-r;
while (q< >0) and (r<>0) do
begin
if a[i}<a[j] then
begin a[k]:=a[i]; k:=k+h; i:=i+1; q:=q‑1
end
else
begin a[k]:=a[j]; k:=k+h; j:=j‑1; r:=r‑1
end;
end;
while r>0 do
begin a[k]:=a[j]; k:=k+h; j:=j‑1; r:=r‑1;
end;
while q>0 do begin
a[k]:=a[i]; k: – k+h; i:=i+1; q:=q‑1;
end;
h:=-h; t:=k; k:=L; L:=t;
until m=0;
f:=not(f); p:=2*p;
until p>=n;
if not(f) then for i:=1 to n do a[i]:=a [i+n];
{вывод результата}
for i:=1 to N do begin write (a[i], ' ');
end;
readln;
end.
Рассмотренные два предыдущих примера иллюстрируют большие проблемы сортировки внешних файлов, если в них часты изменения элементов, например, удаления, добавления, корректировки существующих.
В подобных ситуациях эффективными становятся алгоритмы, в которых обрабатываемые элементы представляются в виде структур данных, удобных для поиска и сортировки. В качестве структур данных можно отметить, в частности, линейные списки, очереди, стеки, деревья и т. п. О них было рассказано в предыдущем разделе.
1.3 Практическая часть
1.3.1 Содержание отчёта по практической работе
1 Задание по варианту.
2 Теоретическая часть (краткое описание используемого метода и необходимые пояснения для понимания функционирования приложения на Delphi).
3 Блок-схема для процедуры, реализующей основной алгоритм.
4 Код программы.
5 Результаты расчёта.
Примечание: а) подбор исходных данных выполнить самостоятельно; б) если в варианте не указан метод, то выбрать наиболее подходящий для решения поставленной задачи (предварительно согласовать с преподавателем).
Похожие работы
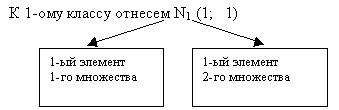
... Е и множество и мы рассматриваем все его подмножества, то множество Е называется униварсельным. Пример: Если за Е взять множество книг то его подмножества: художественные книги, книги по математике, физики, физики … Если универсальное множество состоит из n элементов, то число подмножеств = 2n. Если , состоящее из элементов E, не принадлежащих А, называется дополненным. Множество можно задать: ...
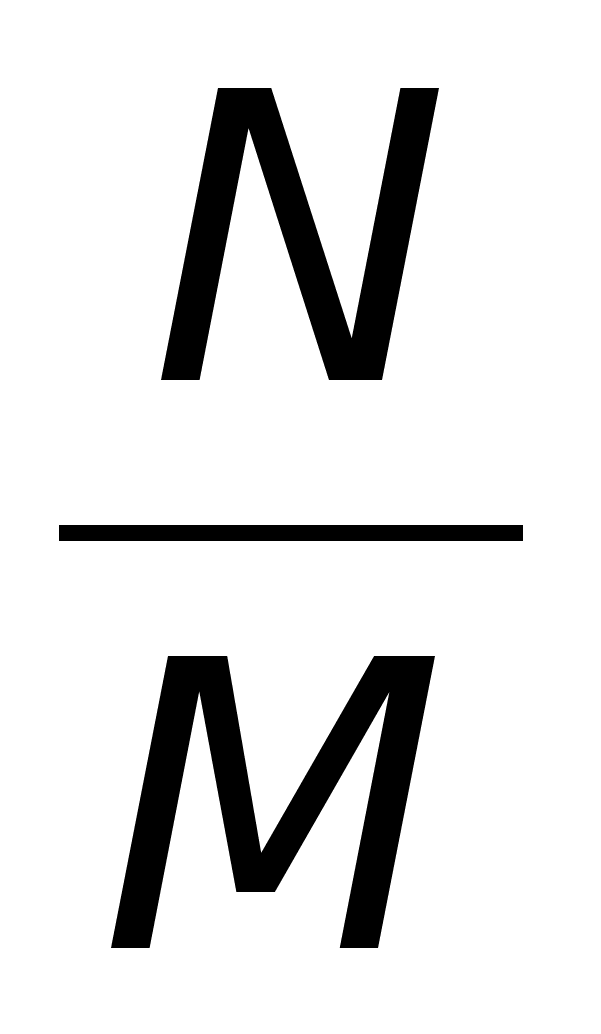
в и формальных систем является центральной в дисциплине. В настоящие время от нее возникли ответвления, например, разработка алгоритмических языков программирования.Одной из важнейших проблем в дискретной математики является проблема сложности вычислений.Теория сложности вычислений помогает оценить расход времени и памяти при решении задач на ЭВМ. Теория сложности позволяет выделить объективно ...
... которой были разработаны в последней четверти 19 века Георгом Кантором. Цель контрольной работы – ознакомится с основными понятиями и методами решения по дискретной математике, уметь применить полученные знания при решении практического задания. Задание 1 Представить с помощью кругов Эйлера множественное выражение . Используя законы и свойства алгебры множеств, упростить заданное ...
элементы теории нечетких множеств можно применять для решения экономических задач в условиях неопределённости. 1. применение Логических функций 1.1 Применение методов дискретной математики в экономике При исследовании, анализе и решении управленческих проблем, моделировании объектов исследования и анализа широко используются методы формализированного представления, являющегося предметом ...
0 комментариев