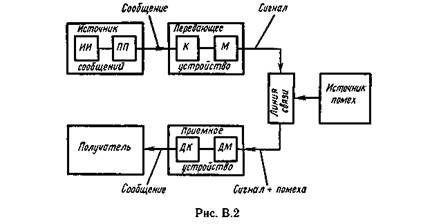
Понятие информации. Задачи и постулаты прикладной теории информации
Бит = 3,32 бит
Энтропия при непрерывном сообщении
Условная энтропия
Взаимная энтропия
Эффективное кодирование
Энтропия алфавита
Кодирование информации для канала с помехами
Связь корректирующей способности кода с кодовым расстоянием
Понятие качества корректирующего кода
Математическое введение к линейным кодам
Линейный код как пространство линейного векторного пространства
Составление таблицы опознавателей
Определение проверочных равенств
Мажоритарное декодирование групповых кодов
Технические средства кодирования и декодирования для групповых кодов
Построение циклических кодов
Выбор образующего многочлена по заданному объему кода и заданной корректирующей способности
Обнаружение и исправление независимых ошибок произвольной кратности
Технические средства кодирования и декодирования для циклических кодов
Кодирующие устройства
Декодирующие устройства
Навигация
Линейный код как пространство линейного векторного пространства
Теория информации
229704
знака
44
таблицы
52
изображения
4.7 Линейный код как пространство линейного векторного пространства
В рассмотренных алгебраических системах (группа, кольцо, поле) операции относились к единому классу математических объектов (элементов). Такие операции называют внутренними законами композиции элементов.
В теории кодирования широко используются модели, охватывающие два класса математических объектов (например, L и W). Помимо внутренних законов композиции в них задаются внешние законы композиции элементов, по которым любым двум элементам wÎW и аÎL ставится в соответствие элемент сÎL.
Линейным векторным пространством над полем элементов F (скаляров) называют множество элементов V (векторов), если для него выполняются следующие аксиомы:
1) множество V является коммутативной группой относительно операции сложения;
2) для любого вектора v изV и любого скаляра с из F определено произведение cv, которое содержится в V (замкнутость по отношению умножения на скаляр);
3) если u и v из V векторы, а с и d из F скаляры, то справедливо с(с+v)=cu+cv; (c+d)v=cv+dv (дистрибутивные законы);
4) если v-вектор, а с и d-скаляры, то (cd)v=c(dv) и 1*v=v
(ассоциативный закон для умножения на скаляр).
Выше было определено правило поразрядного сложения кодовых комбинаций, при котором вся их совокупность образует абелеву группу. Определим теперь операцию умножения последовательности из n элементов поля GF(P) (кодовой комбинации) на элемент поля ai GF(P)аналогично правилу умножения вектора на скаляр: ai(a1, a2, … , an)= (ai a1, ai a2, … , ai an)
(умножение элементов производится по правилам поля GF(P)).
Поскольку при выбранных операциях дистрибутивные законы и ассоциативный закон (п.п.3.4) выполняются, все множество n-разрядных кодовых комбинаций можно рассматривать как векторное линейное пространство над полем GF(2) (т.е. 0 и 1). Сложение производят поразрядно по модулю 2. При умножении вектора на один элемент поля (1) он не изменяется, а умножение на другой (0) превращает его в единичный элемент векторного пространства, обозначаемый символом 0=(0 0…0).
Если в линейном пространстве последовательностей из n элементов поля GF(P) дополнительно задать операцию умножения векторов, удовлетворяющую определенным условиям (ассоциативности, замкнутости, билинейности по отношению к умножению на скаляр), то вся совокупность n-разрядных кодовых комбинаций превращается в линейную коммутативную алгебру над полем коэффициентов GF(P).
Подмножество элементов векторного пространства, которое удовлетворяет аксиомам векторного пространства, называют подпространством.
Линейным кодом называют множество векторов, образующих подпространства векторного пространства всех n-разрядных кодовых комбинаций над полем GF(P).
В случае двоичного кодирования такого подпространства комбинаций над полем GF(2) образует любая совокупность двоичных кодовых комбинаций, являющаяся подгруппой группы всех n-разрядных двоичных кодовых комбинаций. Поэтому любой двоичный линейный код является групповым.
4.8 Построение двоичного группового кода
Построение конкретного корректирующего кода производят, исходя из требуемого объема кода Q, т. е. необходимого числа передаваемых команд или дискретных значений измеряемой величины и статистических данных о наиболее вероятных векторах ошибок в используемом канале связи.
Вектором ошибки называют n-разрядную двоичную последовательность, имеющую единицы в разрядах, подвергшихся искажению, и нули во всех остальных разрядах. Любую искаженную кодовую комбинацию можно рассматривать теперь как сумму (или разность) но модулю 2 исходной разрешенной кодовой комбинации и вектора ошибки.
Исходя из неравенства 2k– l![]() Q (нулевая комбинация часто не используется, так как не меняет состояния канала связи), определяем число информационных разрядов k, необходимое для передачи заданного числа команд обычным двоичным кодом.
Q (нулевая комбинация часто не используется, так как не меняет состояния канала связи), определяем число информационных разрядов k, необходимое для передачи заданного числа команд обычным двоичным кодом.
Каждой из 2k - 1 ненулевых комбинаций k -разрядного безызбыточного кода нам необходимо поставить в соответствие комбинацию из п символов. Значения символов в п – k проверочных разрядах такой комбинации устанавливаются в результате суммирования по модулю 2 значений символов в определенных информационных разрядах.
Поскольку множество 2k комбинаций информационных символов (включая нулевую) образует подгруппу группы всех n-разрядных комбинаций, то и множество 2k n-разрядных комбинаций, полученных по указанному правилу, тоже является подгруппой группы n-разрядных кодовых комбинаций. Это множество разрешенных кодовых комбинаций и будет групповым кодом.
Нам надлежит определить число проверочных разрядов и номера информационных разрядов, входящих в каждое из равенств для определения символов в проверочных разрядах.
Разложим группу 2n всех n-разрядных комбинаций на смежные классы по подгруппе 2k разрешенных n-разрядных кодовых комбинаций, проверочные разряды в которых еще не заполнены. Помимо самой подгруппы кода в разложении насчитывается 2n-k – 1 смежных классов. Элементы каждого класса представляют собой суммы по модулю 2 комбинаций кода и образующих элементов данного класса. Если за образующие элементы каждого класса принять те наиболее вероятные для заданного канала связи вектора ошибок, которые должны быть исправлены, то в каждом смежном классе сгруппируются кодовые комбинации, получающиеся в результате воздействия на все разрешенные комбинации определенного вектора ошибки. Для исправления любой полученной на выходе канала связи кодовой комбинации теперь достаточно определить, к какому классу смежности она относится. Складывая ее затем (по модулю 2) с образующим элементом этого смежного класса, получаем истинную комбинацию кода.
Ясно, что из общего числа 2n – 1 возможных ошибок групповой код может исправить всего 2n-k – 1 разновидностей ошибок по числу смежных классов.
Чтобы иметь возможность получить информацию о том, к какому смежному классу относится полученная комбинация, каждому смежному классу должна быть поставлена в соответствие некоторая контрольная последовательность символов, называемая опознавателем (синдромом).
Каждый символ опознавателя определяют в результате проверки на приемной стороне справедливости одного из равенств, которые мы составим для определения значений проверочных символов при кодировании.
Ранее указывалось, что в двоичном линейном коде значения проверочных символов подбирают так, чтобы сумма по модулю 2 всех символов (включая проверочный), входящих в каждое из равенств, равнялась нулю. В таком случае число единиц среди этих символов четное. Поэтому операции определения символов опознавателя называют проверками на четность. При отсутствии ошибок в результате всех проверок на четность образуется опознаватель, состоящий из одних нулей. Если проверочное равенство не удовлетворяется, то в соответствующем разряде опознавателя появляется единица. Исправление ошибок возможно лишь при наличии взаимно однозначного соответствия между множеством опознавателей и множеством смежных классов, а следовательно, и множеством подлежащих исправлению векторов ошибок.
Таким образом, количество подлежащих исправлению ошибок является определяющим для выбора числа избыточных символов п – k . Их должно быть достаточно для того, чтобы обеспечить необходимое число опознавателей. Если, например, необходимо исправить все одиночные независимые ошибки, то исправлению подлежат п ошибок:
000…01
000…10
……….
010…00
100…00
Различных ненулевых опознавателей должно быть не менее п. Необходимое число проверочных разрядов, следовательно, должно определяться из соотношения
2n-k-1 ![]() n или 2n-k-1
n или 2n-k-1 ![]()
![]()
Если необходимо исправить не только все единичные, но и все двойные независимые ошибки, соответствующее неравенство принимает вид
2n-k-l![]()
![]() +
+![]()
В общем случае для исправления всех независимых ошибок кратности до s включительно получаем
2n-k-l![]()
![]() +
+![]() +…+
+…+![]()
Стоит подчеркнуть, что в приведенных соотношениях указывается теоретический предел минимально возможного числа проверочных символов, который далеко не во всех случаях можно реализовать практически. Часто проверочных символов требуется больше, чем следует из соответствующего равенства.
Одна из причин этого выяснится при рассмотрении процесса сопоставления каждой подлежащей исправлению ошибки с ее опознавателем.
Похожие работы
... порядок чередования букв формируется согласно правилам, заданным верхними иерархическими уровнями текста, то есть не «снизу вверх», а «сверху вниз». Что же касается используемой теорией информации вероятностной функции энтропии, то она может быть использована в качестве точного математического инструмента только на нижних уровнях иерархии текста, поскольку только на этих уровнях удается найти ...
... , 1968. - 340 с.]. В связи с этим логично было бы далее предположить, что она не предполагает строго количественного эквивалента, подобно энергии или материи. Но парадокс классической теории информации именно в том и состоит, что в её основе лежит предположение Р.Хартли, согласно которому информация допускает количественную оценку [Hartley R.V.L. Transmission of Information // BSTJ.- 1928. - V.7 - ...
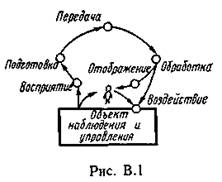
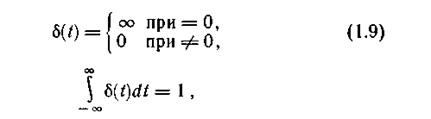
... связано с приложением теории в технике связи - рассмотрением проблемы разработки конкретных методов и средств кодирования сообщений, то совокупность излагаемых вопросов называют теорией информации и кодирования или прикладной теорией информации. Другая точка зрения состоит в том, что глобальной проблемой теории информации следует считать разработку принципов оптимизации системы связи в целом. В ...
... с явлениями, которых, может быть, никогда не было и никогда не будет. Память каждого объекта всегда ограничена, а большая часть поступающей информации так и остается невостребованной. При этом общее ее количество (с точки зрения переносящих ее информационных кодов), безусловно, превышает возможности полного ее запоминания. Для предотвращения переполнения памяти и соответственно потери возможности ...
0 комментариев