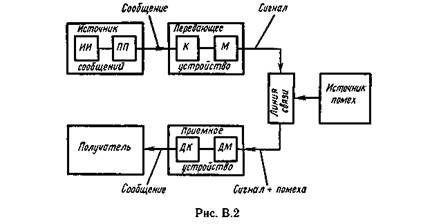
Понятие информации. Задачи и постулаты прикладной теории информации
Бит = 3,32 бит
Энтропия при непрерывном сообщении
Условная энтропия
Взаимная энтропия
Эффективное кодирование
Энтропия алфавита
Кодирование информации для канала с помехами
Связь корректирующей способности кода с кодовым расстоянием
Понятие качества корректирующего кода
Математическое введение к линейным кодам
Линейный код как пространство линейного векторного пространства
Составление таблицы опознавателей
Определение проверочных равенств
Мажоритарное декодирование групповых кодов
Технические средства кодирования и декодирования для групповых кодов
Построение циклических кодов
Выбор образующего многочлена по заданному объему кода и заданной корректирующей способности
Обнаружение и исправление независимых ошибок произвольной кратности
Технические средства кодирования и декодирования для циклических кодов
Кодирующие устройства
Декодирующие устройства
Навигация
Декодирующие устройства
Теория информации
229704
знака
44
таблицы
52
изображения
4.11.3 Декодирующие устройства
Декодирование комбинаций циклического кода можно проводить различными методами. Существуют методы, основанные на использовании рекуррентных соотношений, на мажоритарном принципе, на вычислении остатка от деления принятой комбинации на образующий многочлен кода и др. Целесообразность применения каждого из них зависит от конкретных характеристик используемого кода.
Рассмотрим сначала устройства декодирования, в которых для обнаружения и исправления ошибок производится деление произвольного многочлена f(x), соответствующего принятой комбинации, на образующий многочлен кода g0(x). В этом случае при декодировании могут использоваться те же регистры сдвига, что и при кодировании.
Таблица 4.18.
| Номер такта | Состояние ячеек регистра | Выход | |||
| 1 | 2 | 3 | 4 | ||
| 1 2 3 4 5 6 7 | 1 0 1 1 - - - | 0 1 0 1 1 - - - | 0 0 1 0 1 1 - - | 1 0 0 1 0 1 1 - | 1 01 001 1001 01001 101001 1101001 |
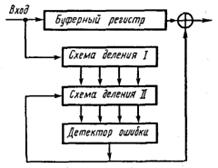
Рис. 4.17.
Декодирующие устройства для кодов, обнаруживающих ошибки, по существу ничем не отличаются от схем кодирующих устройств. В них добавляется лишь буферный регистр для хранения принятого сообщения на время проведения операции деления. Если остатка не обнаружено (случай отсутствия ошибки), то информация с буферного регистра считывается в дешифратор сообщения. Если остаток обнаружен (случай наличия ошибки), то информация в буферном регистре уничтожается и на передающую сторону посылается импульс запроса повторной передачи.
В случае исправления ошибок схема несколько усложняется. Информацию о разрядах, в которых произошла ошибка, несет, как и ранее, остаток. Схема декодирующего устройства представлена на рис. 4.17.
Символы подлежащей декодированию кодовой комбинации, возможно, содержащей ошибку, последовательно, начиная со старшего разряда, вводятся в n-разрядный буферный регистр сдвига и одновременно в схему деления, где за n тактов определяется остаток, который в случае непрерывной передачи сразу же переписывается в регистр второй аналогичной схемы деления.
Начиная с (n + 1)-го такта в буферный регистр и первую схему деления начинают поступать символы следующей кодовой комбинации. Одновременно на каждом такте буферный регистр покидает один символ, а в регистре второй схемы деления появляется новый остаток (синдром). Детектор ошибок, контролирующий состояния ячеек этого регистра, представляет собой комбинаторно-логическую схему, построенную с таким расчетом, чтобы она отмечала все те синдромы («выделенные синдромы»), которые появляются в схеме деления, когда каждый из ошибочных символов занимает крайнюю правую ячейку в буферном регистре. При последующем сдвиге детектор формирует сигнал «1», который, воздействуя на сумматор коррекции, исправляет искаженный символ.
Одновременно по цепи обратной связи с выхода детектора подается сигнал «1» на входной сумматор регистра второй схемы деления. Этот сигнал изменяет выделенный синдром так, чтобы он снова соответствовал более простому типу ошибки, которую еще подлежит исправить. Продолжая сдвиги, обнаружим и другие выделенные синдромы. После исправления последней ошибки все ячейки декодирующего регистра должны оказаться в нулевом состоянии. Если в результате автономных сдвигов состояние регистра не окажется нулевым, это означает, что произошла неисправимая ошибка.
Для декодирования кодовых комбинаций, разнесенных во времени, достаточно одной схемы деления, осуществляющей декодирование за 2n тактов.
Сложность детектора ошибок зависит от числа выделенных синдромом. Простейшие детекторы получаются при реализации кодов, рассчитанных на исправление единичных ошибок.
Выделенный синдром появляется в схеме деления раньше всего в случае, когда ошибка имеет место в старшем разряде кодовой комбинации, так как он первым достигает крайней правой ячейки буферного регистра. Поскольку неискаженная кодовая комбинация делится на g0(x) без остатка, то для определения выделенного синдрома достаточно разделить на g0(x) вектор ошибки с единицей в старшем разряде. Остаток, получающийся на n-м такте, и является искомым выделенным синдромом.
В зависимости от номера искаженного разряда после первых тактов будем получать различные остатки (опознаватели соответствующих векторов ошибок). Вследствие этого выделенный синдром будет появляться в регистре схемы деления через различное число последующих тактов, обеспечивая исправление искаженного символа.
В качестве схем деления в декодирующем устройстве могут быть использованы как схемы, определяющие остаток за n тактов (см. рис. 4.11), так и схемы, определяющие остаток за k тактов (рис. 4.13). При использовании схемы деления за k тактов векторам одиночных ошибок ξ(х) будут соответствовать другие остатки на n-м такте, являющиеся результатом деления на образующий многочлен кода векторов ξ(х)хт, а на ξ(x). Поэтому выделенные синдромы, а следовательно, и детекторы ошибок для указанных схем будут различны.
Пример 40. Рассмотрим процесс исправления единичной ошибки при использовании кода (7,4) с образующим многочленом g(x) = х3 + х2 + 1 и применении в декодирующем устройстве схем деления за n и k тактов.
Определим опознаватели ошибок и выделенный синдром для случая использования схемы деления за n тактов:
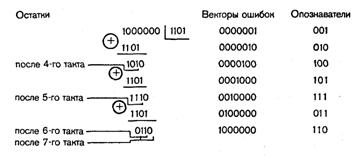
Детектор ошибки, обеспечивающий формирование на выходе сигнала только в случае появления в схеме деления остатка 110, можно реализовать посредством двух логических элементов НЕ и одного логического элемента ИЛИ-НЕ.
На рис. 4.18 приведена схема соответствующего декодирующего устройства. В табл. 4.19 представлен процесс исправления ошибки для случая, когда кодовая комбинация 1001011 (см. табл. 4.18) поступила на вход декодирующего устройства с искаженным символом в 4-м разряде (1000011).
После n (в данном случае 7) тактов в схему деления II переписывается опознаватель ошибки 101.
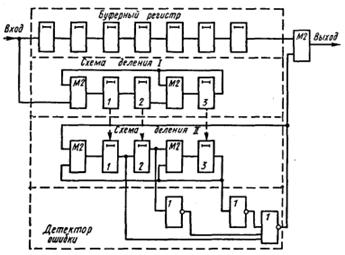
Рис. 4.18.
Таблица 4.19.
| Номер такта | Вход | Состояние ячеек схем деления | Выход после коррекции | ||
| 1 | 2 | 3 | |||
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 | 1 0 0 0 0 1 1 0 0 0 0 0 0 0 | 1 0 0 1 1 0 1 1 1 0 0 0 0 0 | 0 1 0 0 1 1 0 1 1 1 0 0 0 0 | 0 0 1 1 1 0 1 1 0 1 0 0 0 0 | Переписывается в схему деления II 1 01 001 1001 01001 101001 1101001 |
На каждом последующем такте на выходе буферного регистра появляется неискаженный символ корректируемой кодовой комбинации, а в схеме деления II новый остаток. Выделенный синдром появится в схеме деления на 10-м такте, когда искаженный символ займет крайнюю правую ячейку регистра. На следующем такте он попадет в корректирующий сумматор и будет там исправлен импульсом, поступающим с выхода детектора ошибки. Этот же импульс по цепи обратной связи приводит ячейки схемы деления II в нулевое состояние (корректирует выделенный синдром). При использовании схемы деления за k тактов соответствие между векторами ошибок и остатками на n-м такте иное.
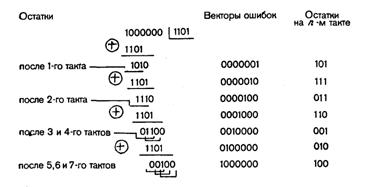
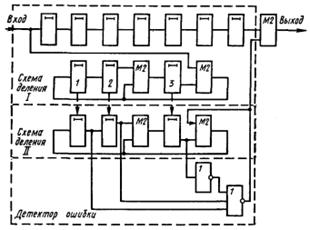
Рис. 4.19.
Таблица 4.20.
| Номер такта | Вход | Состояние ячеек схем деления | Выход после коррекции | ||
| 1 | 2 | 3 | |||
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 | 1 0 0 0 0 1 1 0 0 0 0 0 0 0 | 1 1 1 0 1 1 0 1 0 0 0 0 0 0 | 0 1 1 1 0 1 1 0 1 0 0 0 0 0 | 1 1 0 1 0 1 1 0 0 1 0 0 0 | Переписывается в схему деления II 1 01 001 1001 01001 101001 1101001 |
Детектор для выделенного синдрома 100 можно построить из одного логического элемента НЕ и одного элемента ИЛИ-НЕ.
На рис. 4.19 представлена схема декодирующего устройства для этого случая. Табл. 4.20 позволяет проследить по тактам процесс исправления ошибки в кодовой комбинации 1000011 (искажен символ в 4-м разряде).
Сравнение показывает, что использование в декодирующем устройстве схемы деления за k тактов предпочтительнее, так как выделенный синдром в этом случае при любом объеме кода содержит единицу в старшем и нули во всех остальных разрядах, что приводит к более простому детектору ошибки.
Пример 41. Рассмотрим более сложный случай исправления одиночных и двойных смежных ошибок. Для этой цели может использоваться циклический код (7,3) с образующим многочленом g(x) = (х + 1)(x3 + x2+1).
Ориентируясь на схему деления за k тактов, найдем выделенный синдром для двойных смежных ошибок:
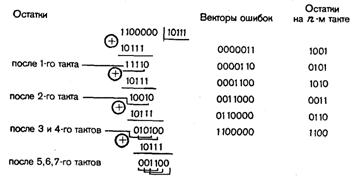
Для одиночных ошибок соответственно получим
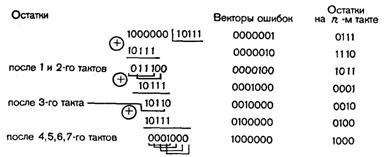
Детектор ошибок в этом случае должен формировать сигнал коррекции при появлении каждого выделенного синдрома. Схема декодирующего устройства представлена на рис. 4.20.
Процесс исправления кодовой комбинации 1000010 с искаженными символами в 4-м и 5-м разрядах поясняется табл. 4.21.
На 9-м такте в схеме деления II появляется первый выделенный синдром 1100. На следующем такте на выходе аналогично обозначенного элемента ИЛИ-НЕ детектора ошибок формируется импульс коррекции, который исправляет 5-й разряд кодовой комбинации и одновременно по цепи обратной связи изменяет остаток в схеме деления II, приводя его в соответствие выделенному синдрому еще не исправленной одиночной ошибки в 4-м разряде (1000). На 11-м такте импульс коррекции формирует элемент ИЛИ-НЕ детектора ошибок, соответствующий указанному выделенному синдрому. Этим импульсом обеспечивается исправление 4-го разряда кодовой комбинации и получение нулевого остатка в схеме деления II.
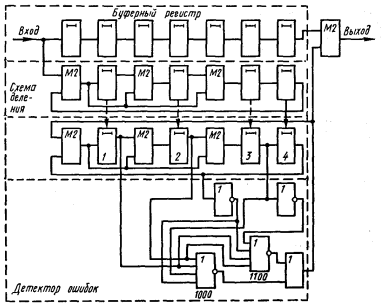
Рис. 4.20.
Таблица 4.21.
| Номер такта | Вход | Состояние ячеек схем деления | Выход после коррекции | |||
| 1 | 2 | 3 | 4 | |||
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 | 1 0 0 0 1 0 0 0 0 0 0 0 0 0 | 1 0 1 1 1 0 1 0 0 0 0 0 0 0 | 1 1 1 0 0 1 1 1 0 0 0 0 0 0 | 1 1 0 0 1 0 0 1 1 0 0 0 0 0 | 0 1 1 0 0 1 0 0 1 1 0 0 0 0 | Переписывается в схему деления II 1 01 101 1101 11101 011101 0011101 |
Список литературы
2. Дмитриев В.И. Прикладная теория информации. Учебник для студентов ВУЗов по специальности «Автоматизированные системы обработки информации и управления». – М.: Высшая школа, 1989 – 320 с.
Похожие работы
... порядок чередования букв формируется согласно правилам, заданным верхними иерархическими уровнями текста, то есть не «снизу вверх», а «сверху вниз». Что же касается используемой теорией информации вероятностной функции энтропии, то она может быть использована в качестве точного математического инструмента только на нижних уровнях иерархии текста, поскольку только на этих уровнях удается найти ...
... , 1968. - 340 с.]. В связи с этим логично было бы далее предположить, что она не предполагает строго количественного эквивалента, подобно энергии или материи. Но парадокс классической теории информации именно в том и состоит, что в её основе лежит предположение Р.Хартли, согласно которому информация допускает количественную оценку [Hartley R.V.L. Transmission of Information // BSTJ.- 1928. - V.7 - ...
... связано с приложением теории в технике связи - рассмотрением проблемы разработки конкретных методов и средств кодирования сообщений, то совокупность излагаемых вопросов называют теорией информации и кодирования или прикладной теорией информации. Другая точка зрения состоит в том, что глобальной проблемой теории информации следует считать разработку принципов оптимизации системы связи в целом. В ...
... с явлениями, которых, может быть, никогда не было и никогда не будет. Память каждого объекта всегда ограничена, а большая часть поступающей информации так и остается невостребованной. При этом общее ее количество (с точки зрения переносящих ее информационных кодов), безусловно, превышает возможности полного ее запоминания. Для предотвращения переполнения памяти и соответственно потери возможности ...
0 комментариев