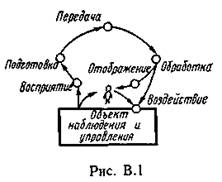
Понятие информации. Задачи и постулаты прикладной теории информации
Бит = 3,32 бит
Энтропия при непрерывном сообщении
Условная энтропия
Взаимная энтропия
Эффективное кодирование
Энтропия алфавита
Кодирование информации для канала с помехами
Связь корректирующей способности кода с кодовым расстоянием
Понятие качества корректирующего кода
Математическое введение к линейным кодам
Линейный код как пространство линейного векторного пространства
Составление таблицы опознавателей
Определение проверочных равенств
Мажоритарное декодирование групповых кодов
Технические средства кодирования и декодирования для групповых кодов
Построение циклических кодов
Выбор образующего многочлена по заданному объему кода и заданной корректирующей способности
Обнаружение и исправление независимых ошибок произвольной кратности
Технические средства кодирования и декодирования для циклических кодов
Кодирующие устройства
Декодирующие устройства
Навигация
Кодирование информации для канала с помехами
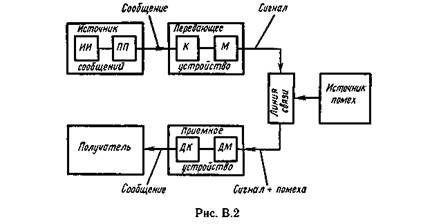
Теория информации
229704
знака
44
таблицы
52
изображения
4. Кодирование информации для канала с помехами
Ошибка в кодовой комбинации появляется при ее передаче по каналу связи вследствие замены одних элементов другими под воздействием помех. Например, 2-кратная ошибка возникает при замене (искажении) двух элементов. Например, если кодовая комбинация 0110111 принята как 0100110, то имеет место двукратная ошибка.
Теория помехоустойчивого кодирования базируется на результатах исследований, проведенных Шенноном и сформулированных в виде теоремы:
1. При любой производительности источника сообщений, меньшей, чем пропускная способность канала, существует такой способ кодирования, который позволяет обеспечить передачу всей информации, создаваемой источником сообщений, со сколь угодно малой вероятностью ошибки.
2. Не существует способа кодирования, позволяющего вести передачу информации со сколь угодно малой вероятностью ошибки, если производительность источника сообщений больше пропускной способности канала.
Из теоремы следует, что помехи в канале не накладывают ограничений на точность передачи. Ограничение накладывается только на скорость передачи, при которой может быть достигнута сколь угодно высокая точность передачи.
Теорема не затрагивает вопроса о путях построения кодов, обеспечивающих идеальную передачу информации, но, обосновав принципиальную возможность такого кодирования, позволяет вести разработку конкретных кодов.
При любой конечной скорости передачи информации вплоть до пропускной способности канала, сколь угодно малая вероятность ошибки достигается лишь при безграничном увеличении длительности кодируемых последовательностей знаков. Таким образом, безошибочная передача при наличии помех возможна лишь теоретически.
Обеспечение передачи информации с весьма малой вероятностью ошибки и достаточно высокой эффективностью возможно при кодировании чрезвычайно длинными последовательностями знаков.
На практике точность передачи информации и эффективность каналов связи ограничивается двумя факторами:
1) размером и стоимостью аппаратуры кодирования/декодирования;
2) временем задержки передаваемого сообщения.
4.1 Разновидности помехоустойчивых кодов
Коды, которые обеспечивают возможность обнаружения и исправления ошибки, называют помехоустойчивыми.
Эти коды используют для:
1) исправления ошибок – корректирующие коды;
2) обнаружения ошибок.
Корректирующие коды основаны на введении избыточности.
У подавляющего большинства помехоустойчивых кодов помехоустойчивость обеспечивается их алгебраической структурой. Поэтому их называют алгебраическими кодами.
Алгебраические коды подразделяются на два класса:
1) блоковые;
2) непрерывные.
В случае блоковых кодов процедура кодирования заключается в сопоставлении каждой букве сообщения (или последовательности из k символов, соответствующей этой букве) блока из n символов. В операциях по преобразованию принимают участие только указанные k символов, и выходная последовательность не зависит от других символов в передаваемом сообщении.
Блоковый код называют равномерным, если n остается постоянным для всех букв сообщения.
Различают разделимые и неразделимые блоковые коды. При кодировании разделимыми кодами выходные последовательности состоят из символов, роль которых может быть отчетливо разграничена. Это информационные символы, совпадающие с символами последовательности, поступающей на вход кодера канала, и избыточные (проверочные) символы, вводимые в исходную последовательность кодером канала и служащие для обнаружения и исправления ошибок.
При кодировании неразделимыми кодами разделить символы входной последовательности на информационные и проверочные невозможно.
Непрерывными (древовидными) называют такие коды, в которых введение избыточных символов в кодируемую последовательность информационных символов осуществляется непрерывно, без разделения ее на независимые блоки. Непрерывные коды также могут быть разделимыми и неразделимыми.
4.2 Общие принципы использования избыточности
Способность кода обнаруживать и исправлять ошибки обусловлена наличием в нем избыточных символов.
На вход кодирующего устройства поступает последовательность из k информационных двоичных символов. На выходе ей соответствует последовательность из n двоичных символов, причем n>k.
Всего может быть 2k различных входных и 2n различных выходных последовательностей.
Из общего числа 2n выходных последовательностей только 2k последовательностей соответствуют входным. Их называют разрешенными кодовыми комбинациями.
Остальные 2n-2k возможных выходных последовательностей для передачи не используются. Их называют запрещенными кодовыми комбинациями.
Искажения информации в процессе передачи сводятся к тому, что некоторые из передаваемых символов заменяются другими – неверными.
Так как каждая из 2k разрешенных комбинаций в результате действия помех может трансформироваться в любую другую, то всегда имеется 2k*2n возможных случаев передачи. В это число входят:
1) 2k случаев безошибочной передачи;
2) 2k(2k –1) случаев перехода в другие разрешенные комбинации, что соответствует необнаруженным ошибкам;
3) 2k(2n – 2k) случаев перехода в неразрешенные комбинации, которые могут быть обнаружены.
Следовательно, часть обнаруживаемых ошибочных кодовых комбинаций от общего числа возможных случаев передачи составляет
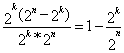 .
.
Пример22: Определить обнаруживающую способность кода, каждая комбинация которого содержит всего один избыточный символ (n=k+1).
Решение : 1. Общее число выходных последовательностей составляет 2k+1, т.е. вдвое больше общего числа кодируемых входных последовательностей.
2. За подмножество разрешенных кодовых комбинаций можно принять, например, подмножество 2k комбинаций, содержащих четное число единиц (или нулей).
3. При кодировании к каждой последовательности из k информационных символов добавляют один символ (0 или 1), такой, чтобы число единиц в кодовой комбинации было четным. Исполнение любого нечетного числа символов переводит разрешенную кодовую комбинацию в подмножество запрещенных комбинаций, что обнаруживается на приемной стороне по нечетности числа единиц. Часть опознанных ошибок составляет
![]() .
.
Любой метод декодирования можно рассматривать как правило разбиения всего множества запрещенных кодовых комбинаций на 2k пересекающихся подмножеств Mi, каждая из которых ставится в соответствие одной из разрешенных комбинаций. При получении запрещенной комбинации, принадлежащей подмножеству Mi, принимают решение, что передавалась запрещенная комбинация Ai. Ошибка будет исправлена в тех случаях, когда полученная комбинация действительно образовалась из Ai, т.е. 2n-2k cлучаях.
Всего случаев перехода в неразрешенные комбинации 2k(2n – 2k). Таким образом, при наличии избыточности любой код способен исправлять ошибки.
Отношение числа исправляемых кодом ошибочных кодовых комбинаций к числу обнаруживаемых ошибочных комбинаций равно
![]() .
.
Способ разбиения на подмножества зависит от того, какие ошибки должны направляться конкретным кодом.
Большинство разработанных кодов предназначено для корректирования взаимно независимых ошибок определенной кратности и пачек (пакетов) ошибок.
Взаимно независимыми ошибками называют такие искажения в передаваемой последовательности символов, при которых вероятность появления любой комбинации искаженных символов зависит только от числа искаженных символов r и вероятности искажения обычного символа p.
При взаимно независимых ошибках вероятность искажения любых r символов в n-разрядной кодовой комбинации:
![]() ,
,
где p – вероятность искажения одного символа;
r – число искаженных символов;
n– число двоичных символов на входе кодирующего устройства;
![]() – число ошибок порядка r.
– число ошибок порядка r.
Если учесть, что p<<1, то в этом случае наиболее вероятны ошибки низшей кратности. Их следует обнаруживать и исправлять в первую очередь.
Похожие работы
... порядок чередования букв формируется согласно правилам, заданным верхними иерархическими уровнями текста, то есть не «снизу вверх», а «сверху вниз». Что же касается используемой теорией информации вероятностной функции энтропии, то она может быть использована в качестве точного математического инструмента только на нижних уровнях иерархии текста, поскольку только на этих уровнях удается найти ...
... , 1968. - 340 с.]. В связи с этим логично было бы далее предположить, что она не предполагает строго количественного эквивалента, подобно энергии или материи. Но парадокс классической теории информации именно в том и состоит, что в её основе лежит предположение Р.Хартли, согласно которому информация допускает количественную оценку [Hartley R.V.L. Transmission of Information // BSTJ.- 1928. - V.7 - ...
... связано с приложением теории в технике связи - рассмотрением проблемы разработки конкретных методов и средств кодирования сообщений, то совокупность излагаемых вопросов называют теорией информации и кодирования или прикладной теорией информации. Другая точка зрения состоит в том, что глобальной проблемой теории информации следует считать разработку принципов оптимизации системы связи в целом. В ...
... с явлениями, которых, может быть, никогда не было и никогда не будет. Память каждого объекта всегда ограничена, а большая часть поступающей информации так и остается невостребованной. При этом общее ее количество (с точки зрения переносящих ее информационных кодов), безусловно, превышает возможности полного ее запоминания. Для предотвращения переполнения памяти и соответственно потери возможности ...
0 комментариев