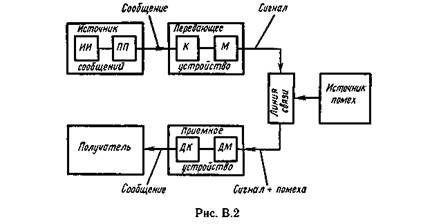
Понятие информации. Задачи и постулаты прикладной теории информации
Бит = 3,32 бит
Энтропия при непрерывном сообщении
Условная энтропия
Взаимная энтропия
Эффективное кодирование
Энтропия алфавита
Кодирование информации для канала с помехами
Связь корректирующей способности кода с кодовым расстоянием
Понятие качества корректирующего кода
Математическое введение к линейным кодам
Линейный код как пространство линейного векторного пространства
Составление таблицы опознавателей
Определение проверочных равенств
Мажоритарное декодирование групповых кодов
Технические средства кодирования и декодирования для групповых кодов
Построение циклических кодов
Выбор образующего многочлена по заданному объему кода и заданной корректирующей способности
Обнаружение и исправление независимых ошибок произвольной кратности
Технические средства кодирования и декодирования для циклических кодов
Кодирующие устройства
Декодирующие устройства
Навигация
Определение проверочных равенств
Теория информации
229704
знака
44
таблицы
52
изображения
4.8.2 Определение проверочных равенств
Итак, для любого кода, имеющего целью исправлять наиболее вероятные векторы ошибок заданного канала связи (взаимно независимые ошибки или пачки ошибок), можно составить таблицу опознавателей одиночных ошибок в каждом из разрядов. Пользуясь этой таблицей, нетрудно определить, символы каких разрядов должны входить в каждую из проверок на четность.
Таблица 4.7.
| Номер разряда | Опознаватель | Номер разряда | Опознаватель | Номер разряда | Опознаватель |
| 1 | 00000001 | 6 | 00010000 | 11 | 01101010 |
| 2 | 00000010 | 7 | 00100000 | 12 | 10000000 |
| 3 | 00000100 | 8 | 00110011 | 13 | 10010110 |
| 4 | 00001000 | 9 | 01000000 | 14 | 10110101 |
| 5 | 00001111 | 10 | 01010101 | 15 | 11011011 |
Рассмотрим в качестве примера опознаватели для кодов, предназначенных исправлять единичные ошибки (табл. 4.8).
Таблица 4.8.
| Номер разрядов | Опознаватель | Номер разрядов | Опознаватель | Номер разрядов | Опознаватель |
| 1 | 0001 | 7 | 0111 | 12 | 1100 |
| 2 | 0010 | 8 | 1000 | 13 | 1101 |
| 3 | 0011 | 9 | 1001 | 14 | 1110 |
| 4 | 0100 | 10 | 1010 | 15 | 1111 |
| 5 | 0101 | 11 | 1011 | 16 | 10000 |
| 6 | 0110 |
В принципе можно построить код, усекая эту таблицу на любом уровне. Однако из таблицы видно, что оптимальными будут коды (7, 4), (15, 11), где первое число равно n, а второе k, и другие, которые среди кодов, имеющих одно и то же число проверочных символов, допускают наибольшее число информационных символов.
Усечем эту таблицу на седьмом разряде и найдем номера разрядов, символы которых должны войти в каждое из проверочных равенств.
Предположим, что в результате первой проверки на четность для младшего разряда опознавателя будет получена единица. Очевидно, это может быть следствием ошибки в одном из разрядов, опознаватели которых в младшем разряде имеют единицу. Следовательно, первое проверочное равенство должно включать символы 1, 3, 5 и 7-го разрядов: a1![]() a3
a3![]() a5
a5![]() a7=0.
a7=0.
Единица во втором разряде опознавателя может быть следствием ошибки в разрядах, опознаватели которых имеют единицу во втором разряде. Отсюда второе проверочное равенство должно иметь вид a2![]() a3
a3![]() a6
a6![]() a7= 0 .
a7= 0 .
Аналогично находим и третье равенство: a4![]() a5
a5![]() a6
a6![]() a7= 0 .
a7= 0 .
Чтобы эти равенства при отсутствии ошибок удовлетворялись для любых значений информационных символов в кодовой комбинации, в нашем распоряжении имеется три проверочных разряда. Мы должны так выбрать номера этих разрядов, чтобы каждый из них входил только в одно из равенств. Это обеспечит однозначное определение значений символов в проверочных разрядах при кодировании. Указанному условию удовлетворяют разряды, опознаватели которых имеют по одной единице. В нашем случае это будут первый, второй и четвертый разряды.
Таким образом, для кода (7, 4), исправляющего одиночные ошибки, искомые правила построения кода, т. е. соотношения, реализуемые в процессе кодирования, принимают вид:
a1=a3![]() a5
a5![]() a7,
a7,
a2=a3![]() a6
a6![]() a7, (4.1)
a7, (4.1)
a4=a5![]() a6
a6![]() a7 .
a7 .
Поскольку построенный код имеет минимальное хэммингово расстояние dmin = 3, он может использоваться с целью обнаружения единичных и двойных ошибок. Обращаясь к табл. 4.8, легко убедиться, что сумма любых двух опознавателей единичных ошибок дает ненулевой опознаватель, что и является признаком наличия ошибки.
Пример 27. Построим групповой код объемом 15 слов, способный исправлять единичные и обнаруживать двойные ошибки.
В соответствии с dи 0 min![]() r+s+1код должен обладать минимальным хэмминговым расстоянием, равным 4. Такой код можно построить в два этапа. Сначала строим код заданного объема, способный исправлять единичные ошибки. Это код Хэмминга (7, 4). Затем добавляем еще один проверочный разряд, который обеспечивает четность числа единиц в разрешенных комбинациях.
r+s+1код должен обладать минимальным хэмминговым расстоянием, равным 4. Такой код можно построить в два этапа. Сначала строим код заданного объема, способный исправлять единичные ошибки. Это код Хэмминга (7, 4). Затем добавляем еще один проверочный разряд, который обеспечивает четность числа единиц в разрешенных комбинациях.
Таким образом, получаем код (8, 4). В процессе кодирования реализуются соотношения:
a1=a3![]() a5
a5![]() a7,
a7,
a2=a3![]() a6
a6![]() a7,
a7,
a4=a5![]() a6
a6![]() a7 .
a7 .
a8=a1![]() a2
a2![]() a3
a3![]() a4
a4![]() a5
a5![]() a6
a6![]() a7,
a7,
Обозначив синдром кода (7, 4) через S1, результат общей проверки на четность — через S2(S2 = ![]() ) и пренебрегая возможностью возникновения ошибок кратности 3 и выше, запишем алгоритм декодирования:
) и пренебрегая возможностью возникновения ошибок кратности 3 и выше, запишем алгоритм декодирования:
при S1= 0 и S2= 0 ошибок нет;
при S1= 0 и S2= 1 ошибка в восьмом разряде;
при S1![]() 0 и S2= 0 двойная ошибка (коррекция блокируется, посылается запрос повторной передачи);
0 и S2= 0 двойная ошибка (коррекция блокируется, посылается запрос повторной передачи);
при S1![]() 0 и S2= 1 одиночная ошибка (осуществляется ее исправление).
0 и S2= 1 одиночная ошибка (осуществляется ее исправление).
Пример 28. Используя табл. 4.8, составим правила построения кода (8,2), исправляющего все одиночные и двойные ошибки.
Усекая табл. 4.7 на восьмом разряде, найдем следующие проверочные равенства:
a1![]() a5
a5![]() a8=0,
a8=0,
a2![]() a5
a5![]() a8=0,
a8=0,
a3![]() a5=0,
a5=0,
a4![]() a5=0,
a5=0,
a6![]() a8=0,
a8=0,
a7![]() a8=0.
a8=0.
Соответственно правила построения кода выразим соотношениями
a1=a5![]() a8 (4.2 а)
a8 (4.2 а)
a2=a5![]() a8 (4.2 б)
a8 (4.2 б)
a3=a5 (4.2 в)
a4=a5 (4.2 г)
a6=a8 (4.2 д)
a7=a8 (4.2 е)
Отметим, что для построенного кода dmin = 5, и, следовательно, он может использоваться для обнаружения ошибок кратности от 1 до 4.
Соотношения, отражающие процессы кодирования и декодирования двоичных линейных кодов, могут быть реализованы непосредственно с использованием сумматоров по модулю два. Однако декодирующие устройства, построенные таким путем для кодов, предназначенных исправлять многократные ошибки, чрезвычайно громоздки. В этом случае более эффективны другие принципы декодирования.
Похожие работы
... порядок чередования букв формируется согласно правилам, заданным верхними иерархическими уровнями текста, то есть не «снизу вверх», а «сверху вниз». Что же касается используемой теорией информации вероятностной функции энтропии, то она может быть использована в качестве точного математического инструмента только на нижних уровнях иерархии текста, поскольку только на этих уровнях удается найти ...
... , 1968. - 340 с.]. В связи с этим логично было бы далее предположить, что она не предполагает строго количественного эквивалента, подобно энергии или материи. Но парадокс классической теории информации именно в том и состоит, что в её основе лежит предположение Р.Хартли, согласно которому информация допускает количественную оценку [Hartley R.V.L. Transmission of Information // BSTJ.- 1928. - V.7 - ...
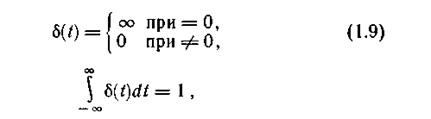
... связано с приложением теории в технике связи - рассмотрением проблемы разработки конкретных методов и средств кодирования сообщений, то совокупность излагаемых вопросов называют теорией информации и кодирования или прикладной теорией информации. Другая точка зрения состоит в том, что глобальной проблемой теории информации следует считать разработку принципов оптимизации системы связи в целом. В ...
... с явлениями, которых, может быть, никогда не было и никогда не будет. Память каждого объекта всегда ограничена, а большая часть поступающей информации так и остается невостребованной. При этом общее ее количество (с точки зрения переносящих ее информационных кодов), безусловно, превышает возможности полного ее запоминания. Для предотвращения переполнения памяти и соответственно потери возможности ...
0 комментариев