Понятие информации. Задачи и постулаты прикладной теории информации
Бит = 3,32 бит
Энтропия при непрерывном сообщении
Условная энтропия
Взаимная энтропия
Эффективное кодирование
Энтропия алфавита
Кодирование информации для канала с помехами
Связь корректирующей способности кода с кодовым расстоянием
Понятие качества корректирующего кода
Математическое введение к линейным кодам
Линейный код как пространство линейного векторного пространства
Составление таблицы опознавателей
Определение проверочных равенств
Мажоритарное декодирование групповых кодов
Технические средства кодирования и декодирования для групповых кодов
Построение циклических кодов
Выбор образующего многочлена по заданному объему кода и заданной корректирующей способности
Обнаружение и исправление независимых ошибок произвольной кратности
Технические средства кодирования и декодирования для циклических кодов
Кодирующие устройства
Декодирующие устройства
Навигация
Связь корректирующей способности кода с кодовым расстоянием
Теория информации
229704
знака
44
таблицы
52
изображения
4.3 Связь корректирующей способности кода с кодовым расстоянием
При взаимно независимых ошибках наиболее вероятен переход в кодовую комбинацию, отличающуюся от данной в наименьшем числе символов.
Степень отличия любых двух кодовых комбинаций характеризуется расстоянием между ними в смысле Хэмминга или просто кодовым расстоянием.
Кодовое расстояние выражается числом символов, в которых комбинации отличаются одна от другой, и обозначается через d.
|
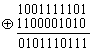
(Сложение ”по модулю 2”: y= х1 Å х2,сумма равна 1 тогда и только тогда, когда х1 и x2 не совпадают ).
Минимальное расстояние, взятое по всем парам кодовых разрешенных комбинаций кода, называют минимальным кодовым расстоянием.
Более полное представление о свойствах кода дает матрица расстояний D, элементы которой dij (i,j = 1,2,…,m) равны расстояниям между каждой парой из всех m разрешенных комбинаций.
Пример23: Представить симметричной матрицей расстояний код х1 = 000; х2 = 001; х3 = 010; х4 = 111.
Решение. 1. Минимальное кодовое расстояние для кода d=1.
2. Симметричная матрица четвертого порядка для кода
Таблица 4.1.
| x1 | x2 | x3 | x4 | ||
| 000 | 001 | 010 | 111 | ||
| x1 | 000 | 1 | 1 | 3 | |
| x2 | 001 | 1 | 2 | 2 | |
| x3 | 010 | 1 | 2 | 2 | |
| x4 | 111 | 3 | 2 | 2 | |
Декодирование после приема производится таким образом, что принятая кодовая комбинация отождествляется с той разрешенной, которая находится от нее на наименьшем кодовом расстоянии.
Такое декодирование называется декодированием по методу максимального правдоподобия.
Очевидно, что при кодовом расстоянии d=1 все кодовые комбинации являются разрешенными.
Например, при n=3 разрешенные комбинации образуют следующее множество: 000, 001, 010, 011, 100, 101, 110, 111.
Любая одиночная ошибка трансформирует данную комбинацию в другую разрешенную комбинацию. Это случай безызбыточного кода, не обладающего корректирующей способностью.
Если d = 2, то ни одна из разрешенных кодовых комбинаций при одиночной ошибке не переходит в другую разрешенную комбинацию. Например, подмножество разрешенных кодовых комбинаций может быть образовано по принципу четности в нем числа единиц. Например, для n=3:
000, 011, 101, 110 – разрешенные комбинации;
001, 010, 100, 111 – запрещенные комбинации.
Код обнаруживает одиночные ошибки, а также другие ошибки нечетной кратности (при n=3 тройные).
В общем случае при необходимости обнаруживать ошибки кратности до r включительно минимальное хэммингово расстояние между разрешенными кодовыми комбинациями должно быть по крайней мере на единицу больше r, т.е d0 min³r+1.
Действительно, в этом случае ошибка, кратность которой не превышает r, не в состоянии перевести одну разрешенную кодовую комбинацию в другую.
Для исправления одиночной ошибки кодовой комбинации необходимо сопоставить подмножество запрещенных кодовых комбинаций.
Чтобы эти подмножества не пересекались, хэммингово расстояние между разрешенными кодовыми комбинациями должно быть не менее трех. При n=3 за разрешенные кодовые комбинации можно, например, принять 000 и 111. Тогда разрешенной комбинации 000 необходимо приписать подмножество запрещенных кодовых комбинаций 001, 010, 100, образующихся в результате двоичной ошибки в комбинации 000.
Подобным же образом разрешенной комбинации 111 необходимо приписать подмножество запрещенных кодовых комбинаций: 110, 011, 101, образующихся в результате возникновения единичной ошибки в комбинации 111:
|
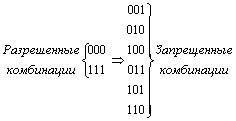
Рис. 4.1.
В общем случае для обеспечения возможности исправления всех ошибок кратности до s включительно при декодировании по методу максимального правдоподобия, каждая из ошибок должна приводить к запрещенной комбинации, относящейся к подмножеству исходной разрешенной кодовой комбинации.
Любая n-разрядная двоичная кодовая комбинация может быть интерпретирована как вершина m-мерного единичного куба, т.е. куба с длиной ребра, равной 1.
При n=2 кодовые комбинации располагаются в вершинах квадрата:
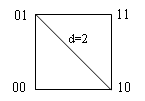
Рис. 4.2.
При n=3 кодовые комбинации располагаются в вершинах единичного куба:
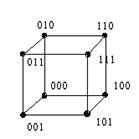
Рис. 4.3.
В общем случае n-мерный единичный куб имеет 2n вершин, что равно наибольшему возможному числу кодовых комбинаций.
Такая модель дает простую геометрическую интерпретацию и кодовому расстоянию между отдельными кодовыми комбинациями. Оно соответствует наименьшему числу ребер единичного куба, которые необходимо пройти, чтобы попасть от одной комбинации к другой.
Ошибка будет не только обнаружена, но и исправлена, если искаженная комбинация остается ближе к первоначальной, чем к любой другой разрешенной комбинации, то есть должно быть: ![]() или
или ![]()
В общем случае для того, чтобы код позволял обнаруживать все ошибки кратности r и исправлять все ошибки кратности s (r>s), его кодовое расстояние должно удовлетворять неравенству d ³ r+s+1 (r³s).
Метод декодирования при исправлении одиночных независимых ошибок можно пояснить следующим образом. В подмножество каждой разрешенной комбинации относят все вершины, лежащие в сфере с радиусом (d-1)/2 и центром в вершине, соответствующей данной разрешенной кодовой комбинации. Если в результате действия помехи комбинация переходит в точку, находящуюся внутри сферы (d-1)/2, то такая ошибка может быть исправлена.
Если помеха смещает точку разрешенной комбинации на границу двух сфер (расстояние d/2) или больше (но не в точку, соответствующую другой разрешенной комбинации), то такое искажение может быть обнаружено.
Для кодов с независимым искажением символов лучшие корректирующие коды – это такие, у которых точки, соответствующие разрешенным кодовым комбинациям, расположены в пространстве равномерно.
Проиллюстрируем построение корректирующего кода на следующем примере. Пусть исходный алфавит, состоящий из четырех букв, закодирован двоичным кодом: х1 = 00; х2 = 01; х3 = 10; х4 = 11. Этот код использует все возможные комбинации длины 2, и поэтому не может обнаруживать ошибки (так как d=1).
Припишем к каждой кодовой комбинации один элемент 0 или 1 так, чтобы число единиц в нем было четное, то есть х1 = 000; х2 = 011; х3 = 101; х4 = 110.
Для этого кода d=2, и, следовательно, он способен обнаруживать все однократные ошибки. Так как любая запрещенная комбинация содержит нечетное число единиц, то для обнаружения ошибки достаточно проверить комбинацию на четность (например, суммированием по модулю 2 цифр кодовой комбинации). Если число единиц в слове четное, то сумма по модулю 2 его разрядов будет 0, если нечетное – то 1. Признаком четности называют инверсию этой суммы.
Рассмотрим общую схему организации контроля по четности (контроль по нечетности, parity check – контроль по паритету).
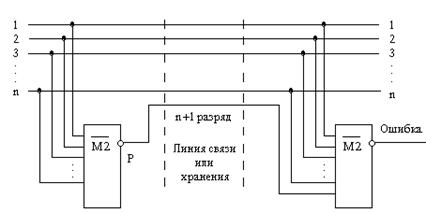
Рис. 4.4.
На n-входовом элементе ![]() формируется признак четности Р числа, который в качестве дополнительного, (n+1)-го контрольного разряда (parity bit) отправляется вместе с передаваемым словом в линию связи или запоминающее устройство. Передаваемое (n+1)-разрядное слово имеет всегда нечетное число единиц. Если в исходном слове оно было нечетным, то инверсия функции М2 от такого слова равна 0, и нулевое значение контрольного разряда не меняет число единиц при передаче слова. Если же число единиц в исходном слове было четным, то контрольный разряд Р для такого числа будет равен 1, и результирующее число единиц в передаваемом (n+1)-разрядном слове станет нечетным. Вид контроля, когда по линии передается нечетное число единиц, по строгой терминологии называют контролем по нечетности.
формируется признак четности Р числа, который в качестве дополнительного, (n+1)-го контрольного разряда (parity bit) отправляется вместе с передаваемым словом в линию связи или запоминающее устройство. Передаваемое (n+1)-разрядное слово имеет всегда нечетное число единиц. Если в исходном слове оно было нечетным, то инверсия функции М2 от такого слова равна 0, и нулевое значение контрольного разряда не меняет число единиц при передаче слова. Если же число единиц в исходном слове было четным, то контрольный разряд Р для такого числа будет равен 1, и результирующее число единиц в передаваемом (n+1)-разрядном слове станет нечетным. Вид контроля, когда по линии передается нечетное число единиц, по строгой терминологии называют контролем по нечетности.
На приемном конце линии или из памяти от полученного (n+1)-разрядного слова снова берется свертка по четности, Если значение этой свертки равно 1, то или в передаваемом слове, или в контрольном разряде при передаче или хранении произошла ошибка. Столь простой контроль не позволяет исправить ошибку, но он, по крайней мере, дает возможность при обнаружении ошибки исключить неверные данные, затребовать повторную передачу и т.д.
Систему контроля можно построить на основе не только инверсии функции М2, но и прямой функции М2 (строго контроль по четности). Однако, в этом случае исходный код “все нули” будет иметь контрольный разряд, равный 0. В линию отправится посылка из сплошных нулей, и на приемном конце она будет неотличима от весьма опасной неисправности – полного пропадания связи. Поэтому контроль по четности в своем чистом виде почти никогда не применяют, контрольный разряд формируют как четности, и в нестрогой терминологии “контролем по четности” называют то, что, строго говоря, на самом деле является контролем по нечетности.
Контроль по четности основан на том, что одиночная ошибка (безразлично – пропадание единицы или появление линией) инвертирует признак четности. Однако две ошибки проинвертируют его дважды, то есть оставят без изменения, поэтому двойную ошибку контроль по четности не обнаруживает. Рассуждая аналогично, легко прийти к выводу, что контроль по четности обнаруживает все нечетные ошибки и не реагирует на любые четные. Пропуск четных ошибок – это не какой-либо дефект системы контроля. Это следствие предельно малой избыточности, равной всего одному разряду. Для более глубокого контроля требуется соответственно и большая избыточность. Если ошибки друг от друга не зависят, то из не обнаруживаемых чаще всего будет встречаться двойная ошибка, а при вероятности одиночной ошибки, равной Р, вероятность двойной будет Р2. Поскольку в нормальных цифровых устройствах P<<1, необнаруженные двойные ошибки встречаются значительно реже, чем обнаруженные одиночные. Поэтому далее при таком простом контроле качество работы устройства существенно возрастает. Это верно лишь для взаимно независимых ошибок.
Признаки четности можно использовать для контроля только неизменяемых данных. При выполнении над данными каких-либо логических операций признаки четности слов в общем изменяются, и попытки компенсировать эти изменения оказываются неэффективными. Счастливое исключение – операция арифметического сложения: сумма по модулю 2 признаков четности двоичных слагаемых и всех, возникших в процессе сложения переносов, равна признаку четности кода арифметической суммы этих слагаемых.
Контроль по четности – самый дешевый по аппаратурным затратам вид контроля, и применяется он очень широко. Практически любой канал передачи цифровых данных или запоминающее устройство, если они не имеют какого-либо более сильного метода контроля, защищены контролем по четности.
Продолжим рассмотрение примера построения корректирующего метода. Чтобы код был способен и исправлять однократные ошибки, необходимо добавить еще не менее двух разрядов. Это можно сделать различными способами, например, повторить первые две цифры:
х1 = 00000; х2 = 01101; х3 = 10110; х4 = 11011;
Матрица расстояний этого кода:
Таблица 4.2.
| x1 | x2 | x3 | x4 | ||
| D= | 3 | 3 | 4 | x1 | |
| 3 | 4 | 3 | x2 | ||
| 3 | 4 | 3 | x3 | ||
| 4 | 3 | 3 | x4 |
Видно, что d ³ 3, что отвечает неравенству (d ³ 2+3+1).
Пример23: Постройте корректирующий код для передачи двух сообщений:
1) обнаруживающий одну ошибку;
2) обнаруживающий и исправляющий одну ошибку;
3) обнаруживающий две и исправляющий одну ошибку.
КОНТРОЛЬ ПРАВИЛЬНОСТИ РАБОТЫ ЦИФРОВЫХ УСТРОЙСТВ
Общие сведения
В процессе работы цифрового устройства возникают ошибки, искажающие информацию. Причинами таких ошибок могут быть:
◙ выход из строя какого-либо элемента, из-за чего устройство теряет работоспособность;
◙ воздействие различного рода помех, возникающих из-за проникновения сигналов из одних цепей в другие через различные паразитные связи.
Выход из строя элемента устройства рассматривается как неисправность. При этом в устройстве наблюдается постоянное искажение информации.
Иной характер искажений информации имеет место под воздействием помех. Вызвав ошибку, помехи могут затем в течение длительного времени не проявлять себя. Такие ошибки называют случайными сбоями.
В связи с возникновением ошибок необходимо снабжать цифровые устройства системой контроля правильности циркулирующей в ней информации. Такие системы контроля могут предназначаться для решения задач двух типов:
◙ задачи обнаружения ошибок;
◙ задачи исправления ошибок.
Система обнаружения ошибок, производя контроль информации, способна лишь выносить решения: нет ошибок и есть ошибка, причем в последнем случае она не указывает, какие разряды слов искажены.
Система исправления ошибок сигнализирует о наличии ошибок и указывает, какие из разрядов искажены. При этом непосредственное исправление цифр искаженных разрядов представляет собой уже несложную операцию. Если известно, что некоторый разряд двоичного слова ошибочен, то появление в нем ошибочного лог.0 означает, что правильное значение — лог. 1 и наоборот.
Трудно локализовать ошибку, т.е. указать, в каких разрядах слова она возникла. После решения этой задачи само исправление сводится лишь к инверсии цифр искаженных разрядов, поэтому обычно под исправлением ошибок понимают решение задачи локализации ошибок.
При постоянном нарушении правильности информации, обнаружив ошибку, можно принять меры для поиска неисправного элемента и заменить его исправным. Причины же случайных сбоев обычно выявляются чрезвычайно трудно, и такие изредка возникающие ошибки желательно было бы устранять автоматически, восстанавливая правильное значение слов с помощью системы исправления ошибок. Однако следует иметь в виду, что система исправления ошибок требует значительно большего количества оборудования, чем система обнаружения ошибок.
Ниже раздельно рассматриваются методы контроля:
◙ цифровых устройств хранения и передачи информации;
◙ цифровых устройств обработки информации.
К устройствам первого типа могут быть отнесены запоминающие устройства, регистры, цепи передачи и другие устройства, в которых информация не должна изменяться. На выходе этих устройств информация та же, что и на входе. К устройствам второго типа относятся устройства, у которых входная информация не совпадает с выходной и в тех случаях, когда ошибки не возникают. Примером могут служить арифметические и логические устройства.
Обнаружение одиночных ошибок в устройствах хранения и передачи информации
Для дальнейшего изложения потребуется понятие кодовое расстояние по Хеммингу. Для двух двоичных слов кодовое расстояние по Хеммингу есть число разрядов, в которых разнятся эти слова. Так, для слов 11011 и 10110 кодовое расстояние d = 3, так как эти слова различаются в трех разрядах (первом, третьем и четвертом).
Пусть используемые слова имеют m разрядов. Для представления информации можно использовать все 2![]() возможных комбинаций от 00 ... 0 до 11 ... 1. Тогда для каждого слова найдутся другие такие слова, которые отличаются от данного не более чем в одном разряде. Например, для некоторого слова 1101 можно найти следующие слова: 0101, отличающиеся только в четвертом разряде; 1001, отличающееся только в третьем разряде, и т.д. Таким образом, минимальное кодовое расстояние d
возможных комбинаций от 00 ... 0 до 11 ... 1. Тогда для каждого слова найдутся другие такие слова, которые отличаются от данного не более чем в одном разряде. Например, для некоторого слова 1101 можно найти следующие слова: 0101, отличающиеся только в четвертом разряде; 1001, отличающееся только в третьем разряде, и т.д. Таким образом, минимальное кодовое расстояние d![]() = 1. Обнаружить ошибки в таких словах невозможно. Например, если передавалось слово N
= 1. Обнаружить ошибки в таких словах невозможно. Например, если передавалось слово N![]() = 1101, а принято N
= 1101, а принято N![]() = 0101, то в принятом слове невозможно обнаружить никаких признаков наличия ошибки (ведь могло бы быть передано и слово N
= 0101, то в принятом слове невозможно обнаружить никаких признаков наличия ошибки (ведь могло бы быть передано и слово N![]() = 0101). Для того чтобы можно было обнаружить одиночные ошибки (ошибки, возникающие не более чем в одном из разрядов слова), минимальное кодовое расстояние должно удовлетворять условию d
= 0101). Для того чтобы можно было обнаружить одиночные ошибки (ошибки, возникающие не более чем в одном из разрядов слова), минимальное кодовое расстояние должно удовлетворять условию d![]() ≥ 2. Это условие требует, чтобы любая пара используемых слов отличалась друг от друга не менее чем в двух разрядах. При этом, если возникает ошибка, она образует такую комбинацию цифр, которая не используется для представления слов, т.е. образует так называемую запрещенную комбинацию.
≥ 2. Это условие требует, чтобы любая пара используемых слов отличалась друг от друга не менее чем в двух разрядах. При этом, если возникает ошибка, она образует такую комбинацию цифр, которая не используется для представления слов, т.е. образует так называемую запрещенную комбинацию.
Для получения d![]() = 2 достаточно к словам, использующим любые комбинации из m информационных двоичных разрядов, добавить один дополнительный разряд, называемый контрольным. При этом значение цифры контрольного разряда выбирают таким, чтобы общее число единиц в слове было четным. Например:
= 2 достаточно к словам, использующим любые комбинации из m информационных двоичных разрядов, добавить один дополнительный разряд, называемый контрольным. При этом значение цифры контрольного разряда выбирают таким, чтобы общее число единиц в слове было четным. Например:
![]()
В первом из приведенных примеров число единиц информационной части четно (8), поэтому контрольный разряд должен содержать 0. Во втором примере число единиц в информационной части слова нечетно (7), и для того, чтобы общее число единиц в слове было четным, контрольный разряд должен содержать единицу. Таким способом во все слова вводится определенный признак — четность числа единиц. Принятые слова проверяются на наличие в них этого признака, и, если он оказывается нарушенным (т.е. обнаруживается, что число содержащихся в разрядах слова единиц нечетно), принимается решение, что слово содержит ошибку.
Этот метод позволяет обнаруживать ошибку. Но с его помощью нельзя определить, в каком разряде слова содержится ошибка, т.е. нельзя исправить ее. Кроме того, при этом методе не могут обнаруживаться ошибки четной кратности, т.е. ошибки одновременно в двух, четырех и т.д. разрядах, так как при таком четном числе ошибок не нарушается четность числа единиц в разрядах слова. Однако наряду с одиночными ошибками могут обнаруживаться ошибки, возникающие одновременно в любом нечетном числе разрядов.
На практике часто вместо признака четности используется признак нечетности, т.е. цифра контрольного разряда выбирается такой, чтобы общее число единиц в разрядах слова было нечетным. При этом, если имеет место, например, обрыв линии связи, это обнаруживается, так как принимаемые слова будут иметь 0 во всех разрядах и нарушится принцип нечетности числа единиц.
Рассмотрим схемы, выполняющие операцию проверки на четность (нечетность). Проверка на четность требует суммирования по модулю 2 цифр разрядов слова. Если а![]() , а
, а![]() ,…, а
,…, а![]() — цифры разрядов, результат проверки на четность определится выражением р = а
— цифры разрядов, результат проверки на четность определится выражением р = а![]() ± а
± а![]() ± а
± а![]() ± ,…, ± а
± ,…, ± а![]() . Если р = 0, то число единиц в разрядах слова четно, в противном случае оно нечетно.
. Если р = 0, то число единиц в разрядах слова четно, в противном случае оно нечетно.
Наиболее просто эта операция реализуется, когда контролируемое слово передается в последовательной форме. Суммирование в этом случае может быть выполнено в последовательности р = ...((a![]() ± а
± а![]() ) ± а
) ± а![]() ) ± ... ± а
) ± ... ± а![]() . К результату суммирования р
. К результату суммирования р![]() первых разрядов прибавляется цифра очередного поступающего разряда (i + 1), находится результат суммирования (i + 1) разрядов p
первых разрядов прибавляется цифра очередного поступающего разряда (i + 1), находится результат суммирования (i + 1) разрядов p![]() = p
= p![]() ± а
± а![]() , и так до тех пор, пока не будут просуммированы цифры всех разрядов.
, и так до тех пор, пока не будут просуммированы цифры всех разрядов.
Из таблицы истинности
Таблица 1

для операции p![]() = p
= p![]() ± а
± а![]() (табл. 1) видно, что лог.0 не должен менять состояния устройства суммирования (p
(табл. 1) видно, что лог.0 не должен менять состояния устройства суммирования (p![]() = p
= p![]() ), лог.1 переводит устройство в новое состояние (p
), лог.1 переводит устройство в новое состояние (p![]() =
= ![]() ). Эта логика соответствует работе триггера со счетным входом (рис.1).
). Эта логика соответствует работе триггера со счетным входом (рис.1).
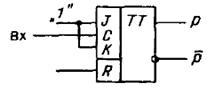
Рис.1. Триггер со счетным входом.
Действительно, пусть триггер был предварительно установлен в состояние 0, после чего на его синхронизирующий вход стали поступать логические уровни, соответствующие цифрам контролируемого слова. При этом первая лог.1 переведет триггер в состояние 1, вторая лог. 1 вернет триггер в состояние 0 и т.д. Следовательно, после подачи четного числа единиц триггер окажется в состоянии р = 0; при поступлении нечетного числа единиц — в состоянии р = 1.
Если разряды контролируемого слова передаются в параллельной форме, то последовательность действий при проверке на четность может быть следующая:
![]()
Согласно этому выражению для нахождения р вначале попарно суммируются по модулю 2 цифры разрядов контролируемого слова, далее полученные результаты также суммируются попарно и т.д.
Этот принцип вычисления р использован в схеме проверки на четность на рис.2.
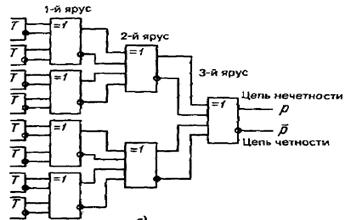
Рис.2. Схема проверки на четность.
Цифры разрядов (и их инверсии) поступают на входы элементов (на рис.2 обозначены =1) первого яруса схемы, в которых они попарно суммируются по модулю 2. Полученные результаты попарно суммируются в элементах второго яруса и т.д.
Результат проверки на четность образуется на выходе элемента старшего яруса. Каждый из элементов схемы реализует следующую логическую функцию:
![]()
Построенная по данному выражению схема элемента, выполняющего операцию суммирования по модулю 2, приведена на рис.3.
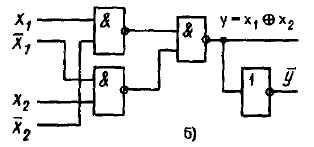
Рис.3.Схема элемента, выполняющего операцию суммирования по модулю 2.
Определим число ярусов и число элементов в этой схеме проверки на четность. Пусть число разрядов n контролируемого слова составляет целую степень двух. Число элементов в отдельных ярусах а![]() составляет геометрическую прогрессию 1,2,4,8,..., n/2, знаменатель которой q = 2. Для последнего k-то яруса а
составляет геометрическую прогрессию 1,2,4,8,..., n/2, знаменатель которой q = 2. Для последнего k-то яруса а![]() = 1, для первого яруса а
= 1, для первого яруса а![]() =a
=a![]() q
q![]() откуда 2
откуда 2![]() = n/2 или 2
= n/2 или 2![]() = n.
= n.
Из этого соотношения можно найти число ярусов k. Число суммирующих элементов в схеме равно сумме членов приведенной выше геометрической прогрессии:
![]()
Контроль арифметических операций
В устройствах хранения и передачи информации одиночная ошибка вызывала искажение цифры лишь одного разряда слова. При выполнении арифметических операций одиночная ошибка в получаемом результате может вызвать искажение одновременно группы разрядов. Пусть в суммирующем счетчике хранится число N![]() = 10111 и на вход поступает очередная единица. Произойдет сложение: N
= 10111 и на вход поступает очередная единица. Произойдет сложение: N![]() = N
= N![]() +1. При этом
+1. При этом

Пусть в процессе суммирования из-за ошибочной работы устройства не будет передан перенос из 2-го разряда в 3-й. Такая одиночная ошибка приведет к следующему результату:
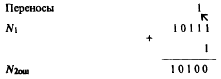
Сравнивая ошибочный результат N![]() с правильным N
с правильным N![]() , видим, что они различаются в двух разрядах. Тем не менее считаем, что в N
, видим, что они различаются в двух разрядах. Тем не менее считаем, что в N![]() содержится одиночная ошибка. Во всех случаях, когда ошибочный результат связан с арифметическим прибавлением (или вычитанием) ошибочной единицы к одному из разрядов, имеет место одиночная ошибка. И если ошибочный результат может быть получен из правильного результата путем арифметического суммирования (или вычитания) единицы не менее чем в k разрядах, кратность ошибки равна k.
содержится одиночная ошибка. Во всех случаях, когда ошибочный результат связан с арифметическим прибавлением (или вычитанием) ошибочной единицы к одному из разрядов, имеет место одиночная ошибка. И если ошибочный результат может быть получен из правильного результата путем арифметического суммирования (или вычитания) единицы не менее чем в k разрядах, кратность ошибки равна k.
Для контроля арифметических операций чаще всего используется контроль по модулю q. Этот метод более универсален и годится также для контроля устройств хранения и передачи информации. Сущность метода состоит в следующем.
Контролируемое число N арифметически делится на q, и выделяется остаток r![]() . Остаток вписывается в контрольные разряды числа N вслед за его информационными разрядами. Принятое число N* делится на q и выделяется остаток r
. Остаток вписывается в контрольные разряды числа N вслед за его информационными разрядами. Принятое число N* делится на q и выделяется остаток r![]() *. Эту операцию выполняет устройство свертки по модулю q (рис.4).
*. Эту операцию выполняет устройство свертки по модулю q (рис.4).
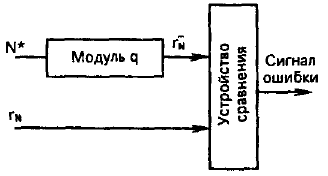
Рис.4. Устройство свертки по модулю q.
Устройство сравнения сравнивает r![]() и r
и r![]() *, в случае их несовпадения выносит решение о наличии ошибки в принятом слове. Схема на рис. 5 иллюстрирует принцип контроля суммирующего устройства.
*, в случае их несовпадения выносит решение о наличии ошибки в принятом слове. Схема на рис. 5 иллюстрирует принцип контроля суммирующего устройства.
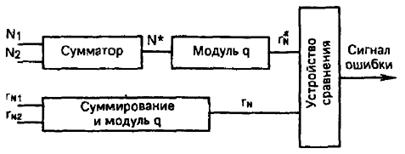
Рис.5. Схема, иллюстрирующая принцип контроля суммирующего устройства.
Пусть в результате суммирования чисел N![]() и N
и N![]() получено N*. Остатки r
получено N*. Остатки r![]() и r
и r![]() также суммируются с выделением остатка r
также суммируются с выделением остатка r![]() . Если остаток r
. Если остаток r![]() *, полученный от деления числа N* на модуль q, не совпадает с r
*, полученный от деления числа N* на модуль q, не совпадает с r![]() , то элемент сравнения сигнализирует о наличии ошибок в работе устройства.
, то элемент сравнения сигнализирует о наличии ошибок в работе устройства.
Чаще всего используется q = 3, иногда выбирается q = 7. При увеличении значения q возрастает способность метода к обнаружению ошибок, но одновременно увеличивается объем контролирующего оборудования.
Рассмотрим пример применительно к схеме на рис. 5. Пусть q = 3, N![]() = 32
= 32![]() = 100000
= 100000![]() , N
, N![]() = 29
= 29![]() = 011101
= 011101![]() . Соответствующие этим числам остатки равны r
. Соответствующие этим числам остатки равны r![]() = 2
= 2![]() = 10
= 10![]() , r
, r![]() = 2
= 2![]() = 10
= 10![]() (при q = 3 остатки могут принимать значения 0, 1, 2 и для их представления в двоичной форме достаточно двух контрольных разрядов). При отсутствии ошибок в работе устройства результат суммирования чисел N* = N
(при q = 3 остатки могут принимать значения 0, 1, 2 и для их представления в двоичной форме достаточно двух контрольных разрядов). При отсутствии ошибок в работе устройства результат суммирования чисел N* = N![]() + N
+ N![]() = 61
= 61![]() = = 111101
= = 111101![]() , значение свертки по модулю 3 равно r
, значение свертки по модулю 3 равно r![]() * = 01
* = 01![]() . Суммируя r
. Суммируя r![]() и r
и r![]() и выделяя остаток по модулю 3, получаем r
и выделяя остаток по модулю 3, получаем r![]() = 01
= 01![]() . Совпадение r
. Совпадение r![]() * = r
* = r![]() указывает на отсутствие ошибок. При наличии ошибок не имело бы места совпадение остатков r
указывает на отсутствие ошибок. При наличии ошибок не имело бы места совпадение остатков r![]() * и r
* и r![]() .
.
Эффективность контроля по модулю характеризуется данными, приведенными в табл. 2.
Таблица 2

В таблице указано, какую часть всех возможных комбинаций ошибок составляют ошибки, которые не обнаруживаются при контроле по модулю. Как видно из приведенных данных, обнаруживаются все однократные ошибки; доля ошибок высокой кратности, оказывающихся необнаруженными, при модуле 7 меньше, чем при модуле 3. Тем самым эффективность контроля по модулю 7 выше, чем при модуле 3. Однако при контроле по модулю 7 контрольная часть слов содержит три двоичных разряда (вместо двух разрядов при модуле 3) и, кроме того, сложнее схемы формирования остатков (схемы свертки).
В заключение рассмотрим построение схем свертки по модулю 3. Общим для этих схем является следующий метод получения остатка. Каждый разряд числа вносит определенный вклад в формируемый остаток. В табл. 3 приведены остатки от деления на 3 значений, выражаемых единицами отдельных разрядов (т.е. весовых коэффициентов разрядов). Эти остатки для единиц нечетных разрядов равны 1, для четных разрядов они равны 2. Следовательно, для получения остатка от деления на 3 всего числа достаточно просуммировать остатки для единиц отдельных его разрядов и затем для получения суммы найти остаток от деления на 3.
Таблица 3
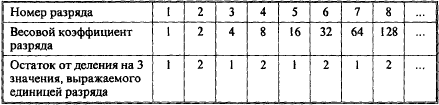
Например, пусть N = 11001011![]() ; сумма остатков, создаваемых отдельными разрядами, S=1·2+1·1 + 0·2 + 0·1 + 1·2+0·1+1·2+1·1 = 8; далее, деля 8 на 3, получаем остаток r
; сумма остатков, создаваемых отдельными разрядами, S=1·2+1·1 + 0·2 + 0·1 + 1·2+0·1+1·2+1·1 = 8; далее, деля 8 на 3, получаем остаток r![]() = 2.
= 2.
Схема свертки по модулю 3 для последовательной формы передачи чисел
Схема может быть выполнена в виде двухразрядного счетчика с циклом 3, построенного таким образом, что единицы нечетных разрядов поступающего на вход числа вызывают увеличение содержимого счетчика на единицу, а единицы четных разрядов вызывают увеличение числа в счетчике на два. Функционирование такого счетчика описывается табл. 4.
Здесь b— код, определяющий четность номера очередного разряда числа, поступающего на вход счетчика; примем для четных разрядов b = 0, для нечетных разрядов b = 1.
Таблица 4
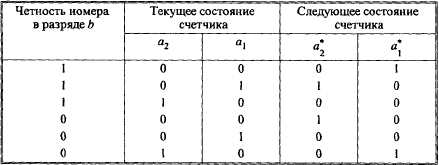
Таблица 5
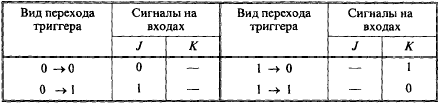
По этой таблице и таблице переходов JK-триггера (табл. 5) построены приведенные на рис. 6 карты, по которым находят логические выражения для входов триггеров ТТ1 и ТТ2 счетчика:
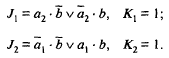
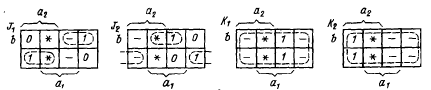
Рис.6. Карты, по которым находят логические выражения для входов триггеров ТТ1 и ТТ2 счетчика.
Представив выражения для J![]() и J
и J![]() в базисе И-НЕ:
в базисе И-НЕ:
![]()
![]()
получим схему межтриггерных связей на рис.7. Логическая переменная b формируется триггером 3.
Этот триггер переключается тактовыми импульсами (ТИ), следующими с частотой поступления разрядов числа на вход счетчика. Таким образом, в моменты поступления нечетных разрядов триггер 3 устанавливается в состояние 1 и b = 1, в моменты поступления четных разрядов b= 0.
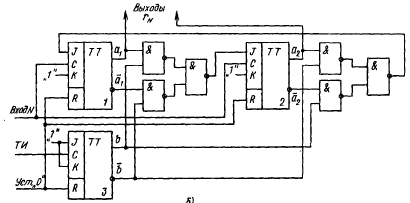
Рис.7. Схема межтриггерных связей.
Схема свертки для параллельной формы представления числа
При параллельной форме представления числа обычно используется пирамидальный способ построения схемы свертки, показанный на рис. 8.
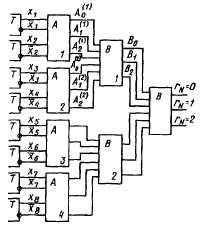
Элементы А первого яруса формируют остатки для пар разрядов числа, выдавая уровень лог. 1 на один из выходов А![]() ,А
,А![]() ,А
,А![]() в зависимости от значения остатка (0,1,2). В последующих ярусах используются однотипные элементы В, которые формируют остатки по результатам, выдаваемым парой элементов предыдущего яруса. На выходе элемента последнего яруса образуется остаток для всего числа.
в зависимости от значения остатка (0,1,2). В последующих ярусах используются однотипные элементы В, которые формируют остатки по результатам, выдаваемым парой элементов предыдущего яруса. На выходе элемента последнего яруса образуется остаток для всего числа.
Выходы элементов определяются следующими логическими выражениями: для первого яруса
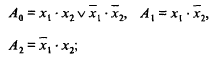
для остальных ярусов
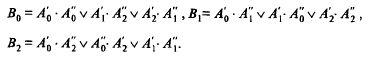
Если число разрядов n = 2![]() , то число ярусов в схеме свертки равно k, а число элементов составляет (n – 1).
, то число ярусов в схеме свертки равно k, а число элементов составляет (n – 1).
Похожие работы
... порядок чередования букв формируется согласно правилам, заданным верхними иерархическими уровнями текста, то есть не «снизу вверх», а «сверху вниз». Что же касается используемой теорией информации вероятностной функции энтропии, то она может быть использована в качестве точного математического инструмента только на нижних уровнях иерархии текста, поскольку только на этих уровнях удается найти ...
... , 1968. - 340 с.]. В связи с этим логично было бы далее предположить, что она не предполагает строго количественного эквивалента, подобно энергии или материи. Но парадокс классической теории информации именно в том и состоит, что в её основе лежит предположение Р.Хартли, согласно которому информация допускает количественную оценку [Hartley R.V.L. Transmission of Information // BSTJ.- 1928. - V.7 - ...
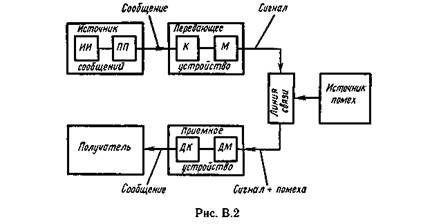
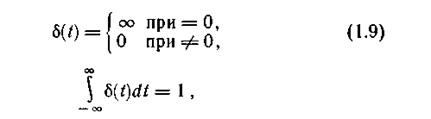
... связано с приложением теории в технике связи - рассмотрением проблемы разработки конкретных методов и средств кодирования сообщений, то совокупность излагаемых вопросов называют теорией информации и кодирования или прикладной теорией информации. Другая точка зрения состоит в том, что глобальной проблемой теории информации следует считать разработку принципов оптимизации системы связи в целом. В ...
... с явлениями, которых, может быть, никогда не было и никогда не будет. Память каждого объекта всегда ограничена, а большая часть поступающей информации так и остается невостребованной. При этом общее ее количество (с точки зрения переносящих ее информационных кодов), безусловно, превышает возможности полного ее запоминания. Для предотвращения переполнения памяти и соответственно потери возможности ...
0 комментариев