Понятие информации. Задачи и постулаты прикладной теории информации
Бит = 3,32 бит
Энтропия при непрерывном сообщении
Условная энтропия
Взаимная энтропия
Эффективное кодирование
Энтропия алфавита
Кодирование информации для канала с помехами
Связь корректирующей способности кода с кодовым расстоянием
Понятие качества корректирующего кода
Математическое введение к линейным кодам
Линейный код как пространство линейного векторного пространства
Составление таблицы опознавателей
Определение проверочных равенств
Мажоритарное декодирование групповых кодов
Технические средства кодирования и декодирования для групповых кодов
Построение циклических кодов
Выбор образующего многочлена по заданному объему кода и заданной корректирующей способности
Обнаружение и исправление независимых ошибок произвольной кратности
Технические средства кодирования и декодирования для циклических кодов
Кодирующие устройства
Декодирующие устройства
Навигация
Мажоритарное декодирование групповых кодов
Теория информации
229704
знака
44
таблицы
52
изображения
4.8.3 Мажоритарное декодирование групповых кодов
Для линейных кодов, рассчитанных на исправление многократных ошибок, часто более простыми оказываются декодирующие устройства, построенные по мажоритарному принципу. Это метод декодирования называют также принципом голосования или способом декодирования по большинству проверок. В настоящее время известно значительное число кодов, допускающих мажоритарную схему декодирования, а также сформулированы некоторые подходы при конструировании таких кодов.
Мажоритарное декодирование тоже базируется на системе проверочных равенств. Система последовательно может быть разрешена относительно каждой из независимых переменных, причем в силу избыточности это можно сделать не единственным способом.
Любой символ аi выражается d (минимальное кодовое расстояние) различными независимыми способами в виде линейных комбинаций других символов. При этом может использоваться тривиальная проверка аi = аi. Результаты вычислений подаются на соответствующий этому символу мажоритарный элемент. Последний представляет собой схему, имеющую d входов и один выход, на котором появляется единица, когда возбуждается больше половины его входов, и нуль, когда возбуждается число таких входов меньше половины. Если ошибки отсутствуют, то проверочные равенства не нарушаются и на выходе мажоритарного элемента получаем истинное значение символа. Если число проверок d![]() 2s+ 1 и появление ошибки кратности s и менее не приводит к нарушению более s проверок, то правильное решение может быть принято по большинству неискаженных проверок. Чтобы указанное условие выполнялось, любой другой символ aj(j
2s+ 1 и появление ошибки кратности s и менее не приводит к нарушению более s проверок, то правильное решение может быть принято по большинству неискаженных проверок. Чтобы указанное условие выполнялось, любой другой символ aj(j![]() i) не должен входить более чем в одно проверочное равенство. В этом случае мы имеем дело с системой разделенных проверок.
i) не должен входить более чем в одно проверочное равенство. В этом случае мы имеем дело с системой разделенных проверок.
Пример 29. Построим систему разделенных проверок для декодирования информационных символов рассмотренного ранее группового кода (8,2).
Поскольку код рассчитан на исправление любых единичных и двойных ошибок, число проверочных равенств для определения каждого символа должно быть не менее 5. Подставив в равенства (4.2 а) и (4.2 б) значения а8, полученные из равенств (4.2 д) и (4.2 е) и записав их относительно a5 совместно с равенствами (4.2 в) и (4.2 г) и тривиальным равенством a5 = a5, получим следующую систему разделенных проверок для символа a5:
a5 = a6![]() a1,
a1,
a5 = a7![]() a2,
a2,
а5 = а3,
а5 = a4,
а5 = а5.
Для символа a8 систему разделенных проверок строим аналогично:
a8 = a3![]() a1,
a1,
a8 = a4![]() a2,
a2,
a8 = а6,
a8 = a7,
a8 = а8.
4.8.4 Матричное представление линейных кодов
Матрицей размерности l![]() n называют упорядоченное множество l
n называют упорядоченное множество l![]() n элементов, расположенных в виде прямоугольной таблицы с l строками и n столбцами:
n элементов, расположенных в виде прямоугольной таблицы с l строками и n столбцами:
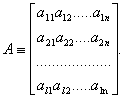
Транспонированной матрицей к матрице А называют матрицу, строками которой являются столбцы, а столбцами строки матрицы А:
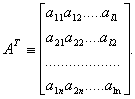
Матрицу размерности n![]() n называют квадратной матрицей порядка n. Квадратную матрицу, у которой по одной из диагоналей расположены только единицы, а все остальные элементы равны нулю, называют единичной матрицей I. Суммой двух матриц А
n называют квадратной матрицей порядка n. Квадратную матрицу, у которой по одной из диагоналей расположены только единицы, а все остальные элементы равны нулю, называют единичной матрицей I. Суммой двух матриц А ![]() |аij| и В
|аij| и В![]() |bij| размерности l
|bij| размерности l![]() n называют матрицу размерности l
n называют матрицу размерности l![]() n:
n:
А + В![]() |аij| + |bij|
|аij| + |bij|![]() |аij + bij|.
|аij + bij|.
Умножение матрицы А ![]() |аij| размерности l
|аij| размерности l![]() n на скаляр с дает матрицу размерности l
n на скаляр с дает матрицу размерности l![]() n: сА
n: сА ![]() c |аij|
c |аij|![]() |c аij|.
|c аij|.
Матрицы А ![]() |аij| размерности l
|аij| размерности l![]() n и В
n и В![]() |bjk| размерности n
|bjk| размерности n![]() m могут быть перемножены, причем элементами cik матрицы — произведения размерности l
m могут быть перемножены, причем элементами cik матрицы — произведения размерности l![]() m являются суммы произведений элементов l-й строки матрицы А на соответствующие элементы k-го столбца матрицы В:
m являются суммы произведений элементов l-й строки матрицы А на соответствующие элементы k-го столбца матрицы В:
cik = ![]()
В теории кодирования элементами матрицы являются элементы некоторого поля GF(P), а строки и столбцы матрицы рассматриваются как векторы. Сложение и умножение элементов матриц осуществляется по правилам поля GF(P).
Пример 30. Вычислим произведение матриц с элементами из поля GF (2):
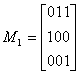
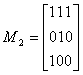
Элементы cik матрицы произведения М = M1M2 будут равны:
c11 = (011) (101) = 0 + 0 + 1 = 1
c12 = (011) (110) = 0 + 1 + 0 = 1
c13 = (011) (100) = 0 + 0 + 0 = 0
c21 = (100) (101) = 1 + 0 + 0 = 1
c22 = (100) (110) = 1 + 0 + 0 = 1
c23 = (100) (100) = 1 + 0 + 0 = 1
c31 = (001) (101) = 0 + 0 + 1 = 1
c32 = (001) (110) = 0 + 0 + 0 = 0
c33 = (001) (100) = 0 + 0 + 0 = 0
Следовательно, 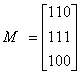
Зная закон построения кода, определим все множество разрешенных кодовых комбинаций. Расположив их друг под другом, получим матрицу, совокупность строк которой является подпространством векторного пространства n-разрядных кодовых комбинаций (векторов) из элементов поля GF(P). В случае двоичного (n, k)-кода матрица насчитывает n столбцов и 2k—1 строк (исключая нулевую). Например, для рассмотренного ранее кода (8,2), исправляющего все одиночные и двойные ошибки, матрица имеет вид
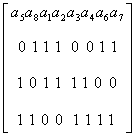
При больших n и k матрица, включающая все векторы кода, слишком громоздка. Однако совокупность векторов, составляющих линейное пространство разрешенных кодовых комбинаций, является линейно зависимей, так как часть векторов может быть представлена в виде линейной комбинации некоторой ограниченной совокупности векторов, называемой базисом пространства.
Совокупность векторов V1, V2, V3, ..., Vn называют линейно зависимой, когда существуют скаляры с1,..сn(не все равные нулю), при которых
c1V1 + c2V2+…+ cnVn= 0
В приведенной матрице, например, третья строка представляет собой суммы по модулю два первых двух строк. Для полного определения пространства разрешенных кодовых комбинаций линейного кода достаточно записать в виде матрицы только совокупность линейно независимых векторов. Их число называют размерностью векторного пространства.
Среди 2k– 1 ненулевых двоичных кодовых комбинаций — векторов их только k. Например, для кода (8,2)
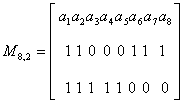
Матрицу, составленную из любой совокупности векторов линейного кода, образующей базис пространства, называют порождающей (образующей) матрицей кода.
Если порождающая матрица содержит k строк по n элементов поля GF(q), то код называют (n, k)-кодом. В каждой комбинации (n, k)-кода k информационных символов и n – k проверочных. Общее число разрешенных кодовых комбинаций (исключая нулевую) Q = qk-1.
Зная порождающую матрицу кода, легко найти разрешенную кодовую комбинацию, соответствующую любой последовательности Аki из k информационных символов.
Она получается в результате умножения вектора Аki на порождающую матрицу Мn,k:
Аni = Аki • Мn,k .
Найдем, например, разрешенную комбинацию кода (8,2), соответствующую информационным символам a5=l, a8 = 1:
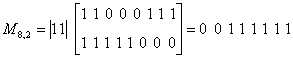 .
.
Пространство строк матрицы остается неизменным при выполнении следующих элементарных операций над строками: 1) перестановка любых двух строк; 2) умножение любой строки на ненулевой элемент поля; 3) сложение какой-либо строки с произведением другой строки на ненулевой элемент поля, а также при перестановке столбцов.
Если образующая матрица кода M2 получена из образующей матрицы кода M1 с помощью элементарных операций над строками, то обе матрицы порождают один и тот же код. Перестановка столбцов образующей матрицы кода приводит к образующей матрице эквивалентного кода. Эквивалентные коды весьма близки по своим свойствам. Корректирующая способность таких кодов одинакова.
Для анализа возможностей линейного (n, k)-кода, а также для упрощения процесса кодирования удобно, чтобы порождающая матрица (Мn,k) состояла из двух матриц: единичной матрицы размерности k ![]() k и дописываемой справа матрицы-дополнения (контрольной подматрицы) размерности k • (n – k), которая соответствует n – k проверочным разрядам:
k и дописываемой справа матрицы-дополнения (контрольной подматрицы) размерности k • (n – k), которая соответствует n – k проверочным разрядам:
 (4.3)
(4.3)
Разрешенные кодовые комбинации кода с такой порождающей матрицей отличаются тем, что первые k символов в них совпадают с исходными информационными, а проверочными оказываются (n - k) последних символов. Действительно, если умножим вектор-строку Ak,i = = (a1 a2…ai...ak) на матрицу Мn,k= [IkPk,n-k], получим вектор
An,i = (a1a2...ai...ak...ak+1...aj...an),
где проверочные символы аj(k +1![]() j
j![]() n) являются линейными комбинациями информационных:
n) являются линейными комбинациями информационных:
![]() (4.4)
(4.4)
Коды, удовлетворяющие этому условию, называют систематическими. Для каждого линейного кода существует эквивалентный систематический код. Как следует из (4.3), (4.4), информацию о способе построения такого кода содержит матрица-дополнение. Если правила построения кода (уравнения кодирования) известны, то значения символов любой строки матрицы-дополнения получим, применяя эти правила к символам соответствующей строки единичной матрицы.
Пример 31. Запишем матрицы Ik, Рk,n-k_и Mn,k для двоичного кода (7,4).
Единичная матрица на четыре разряда имеет вид
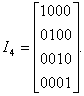
Один из вариантов матрицы дополнения можно записать, используя соотношения (4.1)
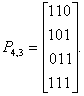
Тогда для двоичного кода Хэммннга имеем:
![]()
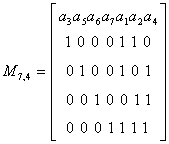
Запишем также матрицу для систематического кода (7,4):
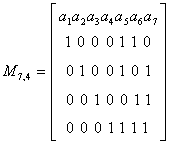
В свою очередь, по заданной матрице-дополнению Pk,n-k можно определить равенства, задающие правила построения кода. Единица в первой строке каждого столбца указывает на то, что в образовании соответствующего столбцу проверочного разряда участвовал первый информационный разряд. Единица в следующей строке любого столбца говорит об участии в образовании проверочного разряда второго информационного разряда и т, д.
Так как матрица-дополнение содержит всю информацию о правилах построения кода, то систематический код с заданными свойствами можно синтезировать путем построения соответствующей матрицы-дополнения.
Так как минимальное кодовое расстояние d для линейного кода равно минимальному весу его ненулевых векторов, то в матрицу-дополнение должны быть включены такие k строк, которые удовлетворяли бы следующему общему условию: вектор-строка образующей матрицы, получающаяся при суммировании любых l (1![]() l
l![]() k) строк, должна содержать не менее d – l отличных от нуля символов.
k) строк, должна содержать не менее d – l отличных от нуля символов.
Действительно, при выполнении указанного условия любая разрешенная кодовая комбинация, полученная суммированием l строк образующей матрицы, имеет не менее d ненулевых символов, так как l ненулевых символов она всегда содержит в результате суммирования строк единичной матрицы. Синтезируем таким путем образующую матрицу двоичного систематического кода (7,4) с минимальным кодовым расстоянием d = 3. В каждой вектор-строке матрицы-дополнения согласно сформулированному условию (при l=1) должно быть не менее двух единиц. Среди трехразрядных векторов таких имеется четыре: 011, 110, 101, 111.
Эти векторы могут быть сопоставлены со строками единичной матрицы в любом порядке. В результате получим матрицы систематических кодов, эквивалентных коду Хэмминга, например:

Нетрудно убедиться, что при суммировании нескольких строк такой матрицы (l>1) получим вектор-строку, содержащую не менее d=3 ненулевых символов.
Имея образующую матрицу систематического кода Мn,k= [IkPk,n-k], можно построить так называемую проверочную (контрольную) матрицу Н размерности (n – k)![]() n:
n:

При умножении неискаженного кодового вектора Аni на матрицу, транспонированную к матрице Н, получим вектор, все компоненты которого равны нулю:

Каждая компонента Sj является результатом проверки справедливости соответствующего уравнения декодирования:
![]()
В общем случае, когда кодовый вектор Аni=(a1, a2,…, ai,…,ak,ak+1,…,aj,…,an) искажен вектором ошибки ξni=(ξ1, ξ2,…, ξi,…,ξk,aξk+1,…,ξj,…,ξn), умножение вектора (Аni+ ξni) на матрицу Нт дает ненулевые компоненты:
![]()
Отсюда видно, что Sj(k +1![]() j
j![]() n) представляют собой символы, зависящие только от вектора ошибки, а вектор S = (Sk + 1, Sk + 2, ...,, Sj, ..., Sn) является не чем иным, как опознавателем ошибки (синдромом).
n) представляют собой символы, зависящие только от вектора ошибки, а вектор S = (Sk + 1, Sk + 2, ...,, Sj, ..., Sn) является не чем иным, как опознавателем ошибки (синдромом).
Для двоичных кодов (операция сложения тождественна операции вычитания) проверочная матрица имеет вид

Пример 32. Найдем проверочную матрицу Н для кода (7,4) с образующей матрицей М:
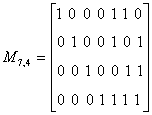
Определим синдромы в случаях отсутствия и наличия ошибки в кодовом векторе 1100011.
Выполним транспонирование матрицы P4,3
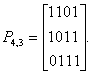
Запишем проверочную матрицу:
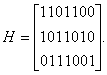
Умножение на Нт неискаженного кодового вектора 1100011 дает нулевой синдром:
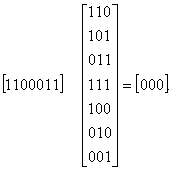
При наличии в кодовом векторе ошибки, например, в 4-м разряде (1101011) получим:
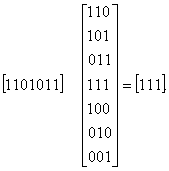
Следовательно, вектор-строка 111 в данном коде является опознавателем (синдромом) ошибки в четвертом разряде. Аналогично можно найти и синдромы других ошибок. Множество всех опознавателей идентично множеству опознавателей кода Хэмминга (7,4), но сопоставлены они конкретным векторам ошибок по-иному, в соответствии с образующей матрицей данного (эквивалентного) кода.
Похожие работы
... порядок чередования букв формируется согласно правилам, заданным верхними иерархическими уровнями текста, то есть не «снизу вверх», а «сверху вниз». Что же касается используемой теорией информации вероятностной функции энтропии, то она может быть использована в качестве точного математического инструмента только на нижних уровнях иерархии текста, поскольку только на этих уровнях удается найти ...
... , 1968. - 340 с.]. В связи с этим логично было бы далее предположить, что она не предполагает строго количественного эквивалента, подобно энергии или материи. Но парадокс классической теории информации именно в том и состоит, что в её основе лежит предположение Р.Хартли, согласно которому информация допускает количественную оценку [Hartley R.V.L. Transmission of Information // BSTJ.- 1928. - V.7 - ...
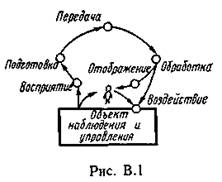
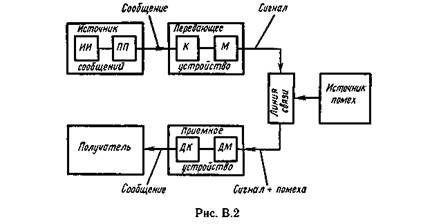
... связано с приложением теории в технике связи - рассмотрением проблемы разработки конкретных методов и средств кодирования сообщений, то совокупность излагаемых вопросов называют теорией информации и кодирования или прикладной теорией информации. Другая точка зрения состоит в том, что глобальной проблемой теории информации следует считать разработку принципов оптимизации системы связи в целом. В ...
... с явлениями, которых, может быть, никогда не было и никогда не будет. Память каждого объекта всегда ограничена, а большая часть поступающей информации так и остается невостребованной. При этом общее ее количество (с точки зрения переносящих ее информационных кодов), безусловно, превышает возможности полного ее запоминания. Для предотвращения переполнения памяти и соответственно потери возможности ...
0 комментариев