Классификация статистических показателей
Критический момент – момент времени, по состоянию на который регистрируются данные. Устанавливается при исследовании динамично изменяющегося объекта
Виды статистических группировок
Частотные характеристики рядов распределения
Средняя арифметическая величина и ее расчет прямым способом
Степенные средние
Измерители вариации
Упрощенный способ расчета дисперсии и средне квадратического отклонения
Моменты распределения
Ошибка выборки
Малая выборка
Распространение результатов выборочного распределения на генеральную совокупность
Способ моментных наблюдений
Классификация методов исследования взаимосвязей
Парная регрессия
Множественная корреляция и регрессия
Обеспечение сопоставимости рядов динамики
Изучение основной тенденции развития, социально-экономического развития во времени
Корреляция в рядах динамики
Сводные индексы
Средние индексы
Навигация
Малая выборка
Статистика
128810
знаков
46
таблиц
0
изображений
3. Малая выборка.
В процессе статистических исследований нередко приходится ограничивать объем выборки, особенно в тех случаях, когда исследования единиц совокупности приводит к их разрушению.
В статистике доказано, что даже в выборке весьма малого объема (20-30, а иногда 4-5 единиц) позволяют получить приемлемые для анализа результаты. Проблема малых выборок была решена в 1908г. английским статистиком У.Гассетом (псевдоним Студент). Он сумел определить зависимость между величиной доверительного коэффициента t, а так же численностью малой выборки n с одной стороны, и вероятностью нахождения ошибки выборки в заданных пределах с другой стороны. Эта зависимость получила название – распределение Стьюдента. Для упрощения расчетов имеются специальные таблицы значений критериев Стьюдента (стр. 372 «Практикума по теории статистики»).
n=n-1 – число степеней свободы.
Малая выборка определяется по формуле
| |
| ||||||
| | |||||||
Средняя ошибка малой выборки
| |
- число степеней свободы.
Пример: Ежедневные затраты времени 15 работников на поездки туда и обратно составляют в среднем 1,7 часа. Определить пределы, в которых находится среднее время поездки на работу и обратно.
| |
=1,7 часа
S2=0,134
P=0,954. Определение оптимальной численности выборки.
Трудовые и материальные затраты на проведение выборки напрямую зависят от ее численности, поэтому чрезвычайно важно до оптимума сохранить численность выборки, так чтобы не утратить ее точность.
Поиск оптимальной численности выборки удобно осуществлять на основе формул средней и предельной ошибок. Из формулы средней ошибки случайного повторного отбора видно, что величина средней ошибки обратно пропорциональна квадратному корню из численности выборки (). Чтобы сократить среднюю ошибку в 2 раза, нужно численность выборки увеличить в 4 раза. Используя формулу предельной ошибки выборки можно найти численность . Это оптимальная численность выборки для случайного повторного отбора.
Пример: Для определения среднего размера банковского вклада сроком на 91 день необходимо провести повторный отбор из совокупности в 2500 договоров. Какое количество договоров необходимо отобрать, чтобы с вероятностью 0,954 предельная ошибка выборки не превысила 25 руб.
| |
p=0,954
D=25 руб.
n-?
s2=8900
Наличие в формуле оптимальной численности генеральной дисперсии приводит на первый взгляд к парадоксу: зачем нам проводить выборку, если известна генеральная дисперсия (а, следовательно, и генеральная средняя). Однако на практике генеральная дисперсия обычно не известна, вместо нее используют выборочную дисперсию предыдущего обследования, так как дисперсия как показатель является более устойчивой, чем сами варианты, на основе которых она рассчитана.
Если отбор осуществляется бесповторно, то численность выборки для такого отбора рассчитывается по формуле:
| |
Для предыдущего примера:
Результаты близки, так как очень велика генеральная совокупность.
Если в условиях задачи присутствует предельная ошибка выборочной доли, то формула:
| |
- для повторного отбора;
- для бесповторного отбора.
Пример: В целях изучения спроса на спортивную обувь периодически проводился опрос 1500 спортсменов. Какова должна быть численность случайного бесповторного отбора, чтобы с p=0,954 ошибка выборки доли спортсменов, предпочитающих обувь с верхом из натуральной кожи, не превысила 0,05, если известно, что ранее этой обуви отдавали предпочтение 65% спортсменов.
| |
p=0,954 (t=2)
D=0,05
w=65%=0,65
n-?
Похожие работы
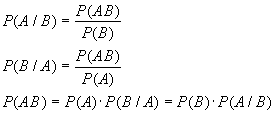
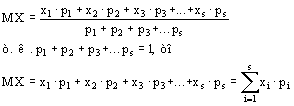
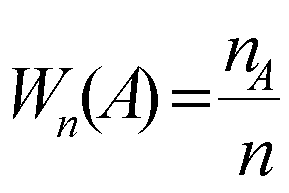
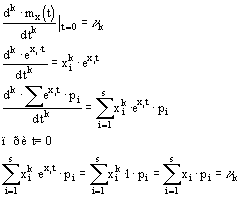
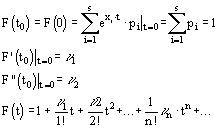
... Доказать: По определению второй смешанной производной. Найдем по двумерной плотности одномерные плотности случайных величин X и Y. Т.к. полученное равенство верно для всех х, то подинтегральные выражение аналогично В математической теории вероятности вводится как базовая формула (1) ибо предлагается, что плотность вероятности как аналитическая функция может не существовать. Но т.к. в нашем ...
... распределения генеральной совокупности F(x) и – эмпирической функция распределения Fn(x) , построенной по выборке х1,…,хn, называется функция. Теорема. Если F(x) непрерывна, то распределения статистики Колмогорова Dn не зависит от F(x). Условные математические ожидания и условные распределения. Св-ва условных мат. ожиданий. Аналоги формул полной вероятности и формулы Байеса для мат. ожиданий ГММЕ ...
... дает возможность статистического моделирования, происходящих в населении процессов. Потребность в моделировании возникает в случае невозможности исследования самого объекта. Наибольшее число моделей, применяемых в статистике населения, разработано для характеристики его динамики. Среди них выделяются экспоненциальные и логистические. Особое значение в прогнозе населения на будущие периоды имеют ...
... на задний план традиционными постановками. Несколько лет назад при описании современного этапа развития статистических методов нами были выделены [29] пять актуальных направлений, в которых развивается современная прикладная статистика, т.е. пять "точек роста": непараметрика, робастность, бутстреп, интервальная статистика, статистика объектов нечисловой природы. Обсудим их. 5. ...
0 комментариев