Классификация статистических показателей
Критический момент – момент времени, по состоянию на который регистрируются данные. Устанавливается при исследовании динамично изменяющегося объекта
Виды статистических группировок
Частотные характеристики рядов распределения
Средняя арифметическая величина и ее расчет прямым способом
Степенные средние
Измерители вариации
Упрощенный способ расчета дисперсии и средне квадратического отклонения
Моменты распределения
Ошибка выборки
Малая выборка
Распространение результатов выборочного распределения на генеральную совокупность
Способ моментных наблюдений
Классификация методов исследования взаимосвязей
Парная регрессия
Множественная корреляция и регрессия
Обеспечение сопоставимости рядов динамики
Изучение основной тенденции развития, социально-экономического развития во времени
Корреляция в рядах динамики
Сводные индексы
Средние индексы
Навигация
Виды статистических группировок
Статистика
128810
знаков
46
таблиц
0
изображений
4. Виды статистических группировок.
В соответствии с задачами группировки подразделяются на:
- Типологические группировки служат для выявления социально-экономических типов явлений.
- Структурные группировки предназначены для выявления структуры совокупности, то есть соотношение между частями целого.
Пример: Группировка рабочих цеха по профессии.
| Профессия | Численность в % к итогу |
| Токари | 35 |
| Фрезеровщики | 10 |
| Слесари | 40 |
| Прочие | 15 |
| Итого | 100 |
- Аналитические группировки позволяют установить, в какой мере изменение значений одного из признаков (признак-фактор), влияя на вариацию другого (результативного) признака.
Пример: Аналитическая группировка магазинов по величине торговой площади.
| Группа магазинов с торговой площадью, кв. м | Число магазинов | Средний уровень издержек, в % к товарообороту |
| До 200 | 12 | 28,7 |
| От 200 до 400 | 23 | 24,5 |
| От 400 до 600 | 17 | 21,3 |
| Свыше 600 | 15 | 18,7 |
Группировка показывает обратную связь между торговой площадью и издержками магазина в расчете на 100 руб. товарооборота.
- Комбинационные группировки применяются в тех случаях, когда для выявления социально-экономического типа недостаточно одного признака. Комбинационные группировки строятся по иерархической системе, когда группы, выделенные по одному признаку, делятся на подгруппы по значениям других признаков.
Пример: Группировка промышленных предприятий по стоимости основных фондов и среднесписочной численности работников.
| Группы предприятий по стоимости основных фондов, тыс. руб. | В том числе с численностью рабочих, чел. | Число предприятий |
| До 500 | До 50 | 7 |
| 51-100 | 4 | |
| 101-500 | 2 | |
| 501-1000 | - | |
| Свыше 1000 | - | |
| 501-1000 | До 50 | 1 |
| 51-100 | 3 | |
| 101-500 | 4 | |
| 501-1000 | 4 | |
| Свыше 1000 | - |
Построение комбинационной группировки требует многочисленной совокупности, в противном случае при образовании большого числа групп появляются малочисленные и пустые интервалы.
Недостаток комбинационной группировки: устраняет многомерные группировки, появившиеся в 60-70 годах прошлого века.
- Многомерные группировки предназначены для выделения групп однородных по совокупности признаков.
Для решения этой задачи применяются различные математические алгоритма, общая идея которых заключается в разбиении исходного множества на непересекающиеся подмножества (кластеры, таксоны), элементы, которые либо подобны друг другу, либо наименее удалены друг от друга в N-мерном пространстве признаков.
5. Понятие и виды статистических таблиц.
Статистическая таблица – наиболее рациональная и распространенная форма представления статистических данных. Существует примерно 300 лет.
Любая статистическая таблица состоит из ряда элементов.
Пересечение строк и столбцов называется скелетом таблицы. Если включить в скелет таблицы заголовки граф и строк, получим макет таблицы, который отражает основную цель ее построения. Макеты таблиц обязательно составляются на этапе подготовки программы статистической сводки, для уточнения программ и схемы обработки собранной информации. По аналогии с грамматикой, содержание таблицы делится на подлежащее и сказуемое. Подлежащим таблицы считается объект исследования, сказуемым – перечень признаков, характеризующих объект исследования.
В зависимости от характера разработки подлежащего таблицы делятся на:
- Простые таблицы;
- Групповые таблицы;
- Комбинационные таблицы.
В подлежащем простых таблиц содержатся либо перечень единиц наблюдений, либо показатели времени, либо отдельные территории. В зависимости от этого различают:
- Перечневые простые таблицы;
- Хронологические простые таблицы;
- Территориальные простые таблицы.
Подлежащее групповых таблиц содержит группировку по одному признаку, а комбинационных по нескольким признакам.
Сказуемое таблица может быть:
- Простым – содержит перечень признаков, характеризующих подлежащее;
- Комбинированным – содержит группировку признаков, характеризующих подлежащее.
При составлении таблиц рекомендуется соблюдать ряд общепринятых требований:
1. Таблица не должна быть слишком громоздкой, перенасыщенной показателями, лучше построить 2-3 простых таблиц;
2. Общий заголовок таблицы должен лаконично отображать ее содержание, определять место и время, к которому относятся статистические данные;
3. Территориальные единицы в подлежащем даются в алфавитном порядке, а даты в хронологическом порядке;
4. Кратко формулируются заголовки граф и строк, и в них указываются единицы измерения. Общая единица измерения указывается в общем заголовке;
5. Все показатели таблицы даются с одинаковой точностью, если значение показателя не имеет смысла ставится «х», если отсутствует «-», если данные не известны «….», если величина очень мала «0,0…»;
6. Таблицы могут сопровождаться примечаниями со ссылками на источники информации и методы расчета данных.
Ряды распределения.
1. Понятие и виды рядов распределения.
2. Частотные характеристики рядов распределения.
3. Графическое изображение рядов распределения.
1. Понятие и виды рядов распределения.
Ряд распределения – упорядоченная совокупность значений признака.
Бывают ряды распределения:
- Качественных признаков (атрибутивные ряды распределения);
- Количественных признаков (вариационные ряды распределения).
Любой ряд состоит из 2 видов элементов:
- Вариантов ряда (значения признака);
- Его частотной характеристики.
Атрибутивные ряды характеризуют распределение качественных признаков, например распределение рабочих по полу, профессии, образованию.
Вариационные ряды обычно упорядочиваются в соответствии с увеличением значений количественного признака.
Они бывают дискретные и интервальные. Варианты дискретного ряда – это дискретно прерывно изменяющиеся значения признак, обычно это результат подсчета.
Пример: Распределение мужских костюмов, реализованных магазинами за месяц по размерам.
| Размер костюма | Число проданных костюмов, шт. |
| 44 | 12 |
| 46 | 31 |
| 48 | 127 |
| 50 | 215 |
| 52 | 164 |
| 54 | 91 |
| 56 | 47 |
| 58 | 28 |
| 60 | 11 |
| Итого | 726 |
Интервальные ряды предназначены для анализа распределения непрерывно изменяющегося признака, значение которого чаще всего регистрируется путем измерения или взвешивания. Варианты такого ряда – это группировка.
Пример: Распределение покупок в продуктовом магазине по сумме.
| Сумма покупки, руб. | Число покупок |
| До 50 | 37 |
| 50,1-100 | 78 |
| 100,1-150 | 111 |
| 150,1-200 | 105 |
| 200,1-250 | 68 |
| Свыше 250 | 49 |
| Итого | 448 |
Если в атрибутивных и дискретных вариационных рядах частотная характеристика относится непосредственно к варианту ряда, то в интервальных к группе вариантов.
Поскольку в расчетах группа должна быть представлена обычно одним вариантом, в качестве этого варианта условно выбирается середина каждого интервала.
Такой подход возможен исходя из гипотезы о равномерном распределении вариантов внутри каждого интервала.
Интервальный ряд, таким образом, преобразуется в дискретный, варианты которого – это середины соответствующих интервалов. Середины закрытых интервалов определяются как полусумма нижней и верхней границы интервала.
Середина первого интервала с открытой нижней границей определяется по формуле , где xВ1 – верхняя граница первого интервала, c2 – второй интервал.
Середина последнего интервала определяется по формуле , где xнn – нижняя граница n-го интервала, сn-1 – предыдущий интервал (предпоследний).
Похожие работы
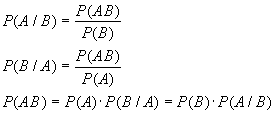
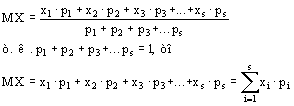
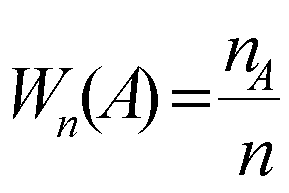
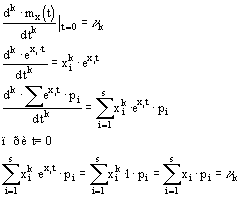
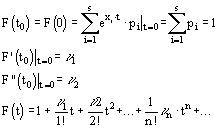
... Доказать: По определению второй смешанной производной. Найдем по двумерной плотности одномерные плотности случайных величин X и Y. Т.к. полученное равенство верно для всех х, то подинтегральные выражение аналогично В математической теории вероятности вводится как базовая формула (1) ибо предлагается, что плотность вероятности как аналитическая функция может не существовать. Но т.к. в нашем ...
... распределения генеральной совокупности F(x) и – эмпирической функция распределения Fn(x) , построенной по выборке х1,…,хn, называется функция. Теорема. Если F(x) непрерывна, то распределения статистики Колмогорова Dn не зависит от F(x). Условные математические ожидания и условные распределения. Св-ва условных мат. ожиданий. Аналоги формул полной вероятности и формулы Байеса для мат. ожиданий ГММЕ ...
... дает возможность статистического моделирования, происходящих в населении процессов. Потребность в моделировании возникает в случае невозможности исследования самого объекта. Наибольшее число моделей, применяемых в статистике населения, разработано для характеристики его динамики. Среди них выделяются экспоненциальные и логистические. Особое значение в прогнозе населения на будущие периоды имеют ...
... на задний план традиционными постановками. Несколько лет назад при описании современного этапа развития статистических методов нами были выделены [29] пять актуальных направлений, в которых развивается современная прикладная статистика, т.е. пять "точек роста": непараметрика, робастность, бутстреп, интервальная статистика, статистика объектов нечисловой природы. Обсудим их. 5. ...
0 комментариев